Introducing Evaluatorq
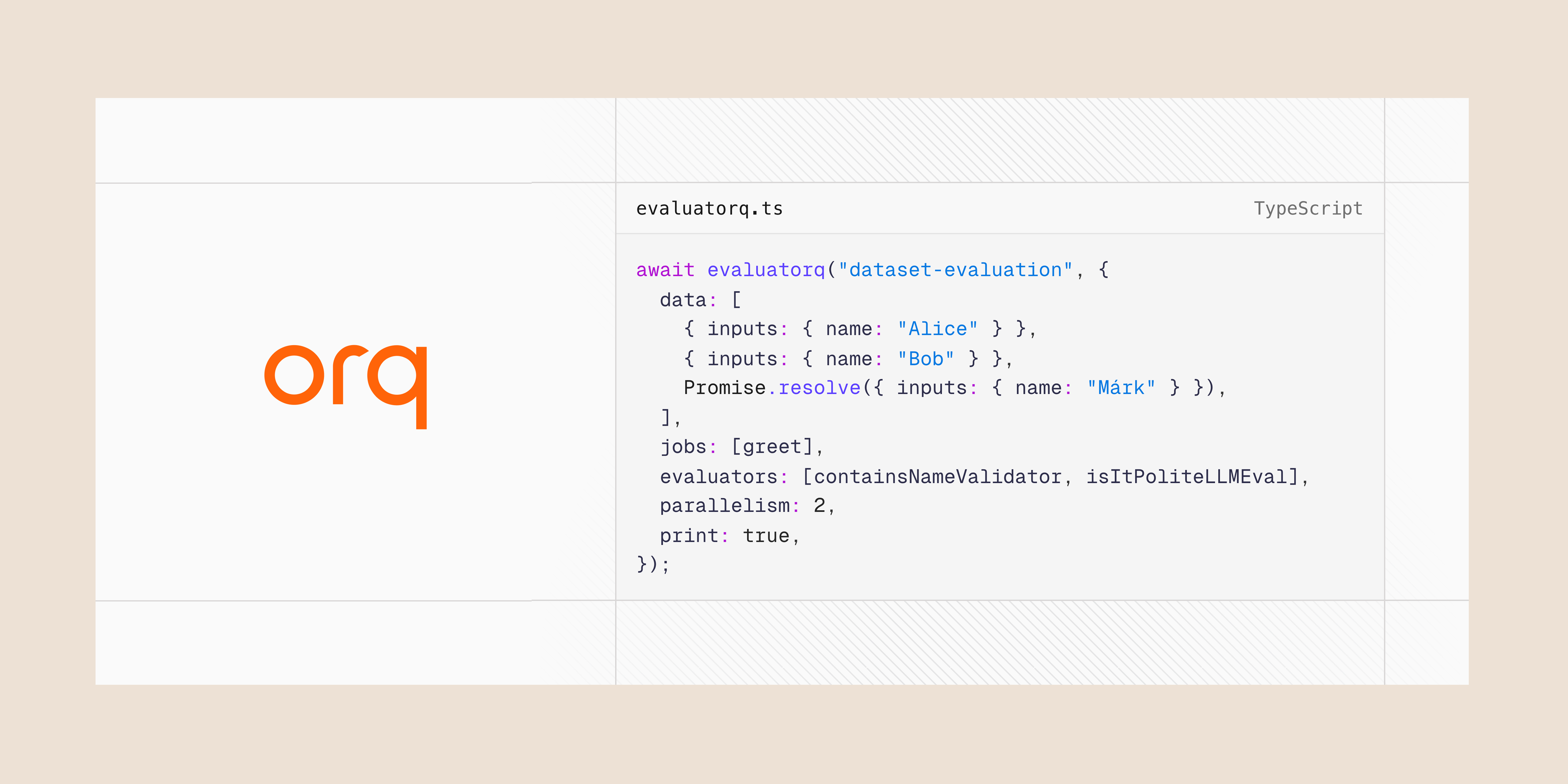
- Parallel Execution: Run multiple evaluation jobs concurrently with progress tracking
- Flexible Data Sources: Support for inline data, promises, and Orq platform datasets
- Type-safe: Fully written in TypeScript
- Orq Platform Integration: Seamlessly fetch and evaluate datasets from Orq AI (optional)
npm install @orq-ai/evaluatorqBasic UsageTypescript
Native support for Gemini models - URL Context Tool
The new URL context tool enables models to access content directly from provided URLs, enhancing responses with external information for tasks like extracting data, comparing documents, synthesizing content, and analyzing code or documentation.Key Features- Two-step retrieval: internal index cache first, live fetch if unavailable.
- Returns url_context_metadata with retrieval details and safety checks.
- Supports up to 20 URLs per request, max 34MB per URL.
- Retrieved content counts toward input tokens (tracked in usage_metadata).
- gemini-2.5-pro
- gemini-2.5-flash
- gemini-2.5-flash-lite
- Use direct, specific, fully qualified URLs (https://…).
- Avoid login-restricted or paywalled content.
- Combine with Google Search grounding for broader workflows.
OpenTelemetry Tracing Support

- Native OpenTelemetry (OTel) export for traces.
- Send spans directly to our OTLP/HTTP collector at: https://api.orq.ai/v2/otel.
- Works with standard OTel SDKs and exporters (Python, Node.js).
- Supports custom headers (e.g., bearer tokens) and resource attributes (e.g., service.name).
Python
TypeScript
Knowledge API: New Parameters
Newsearch_type field with options:vector_search: Semantic similarity searchkeyword_search: Exact text matchinghybrid_search: Combined approach (default)- Separated Top-K Controls:
top_k: Controls initial document retrieval (1-100)rerank_config.top_k: Controls final result count after reranking (1-100)
- New agentic_rag_config parameter to customize AI-driven search behavior per request
- Flexible Search Strategy: Choose optimal search method per query
- Fine-tuned Relevance: Retrieve broadly, return precisely with independent top-k settings
- Performance Optimization: Better control over retrieval vs. quality trade-offs
- Users can now choose specific search strategies instead of relying on knowledge base defaults
- Better control over the retrieval-rerank pipeline allows for more relevant results by retrieving more documents initially but returning fewer, higher-quality results
Support for OpenAI’s image edit and variation APIs
Image Edit and Image Variation are now supported in our AI Proxy. This comes with complete trace monitoring and cost tracking.Also, all the images are stored in our Orq with the same expirations as the retention period of your workspace.cURL
Python
Typescript
File Uploads for Anthropic Models
PDF support is currently supported via direct API access and Google Vertex AI on:- Claude Opus 4.1 (claude-opus-4-1-20250805)
- Claude Opus 4 (claude-opus-4-20250514)
- Claude Sonnet 4 (claude-sonnet-4-20250514)
- Claude Sonnet 3.7 (claude-3-7-sonnet-20250219)
- Claude Haiku 3.5 (claude-3-5-haiku-20241022)
Comprehensive Budget Controls & Cost Management
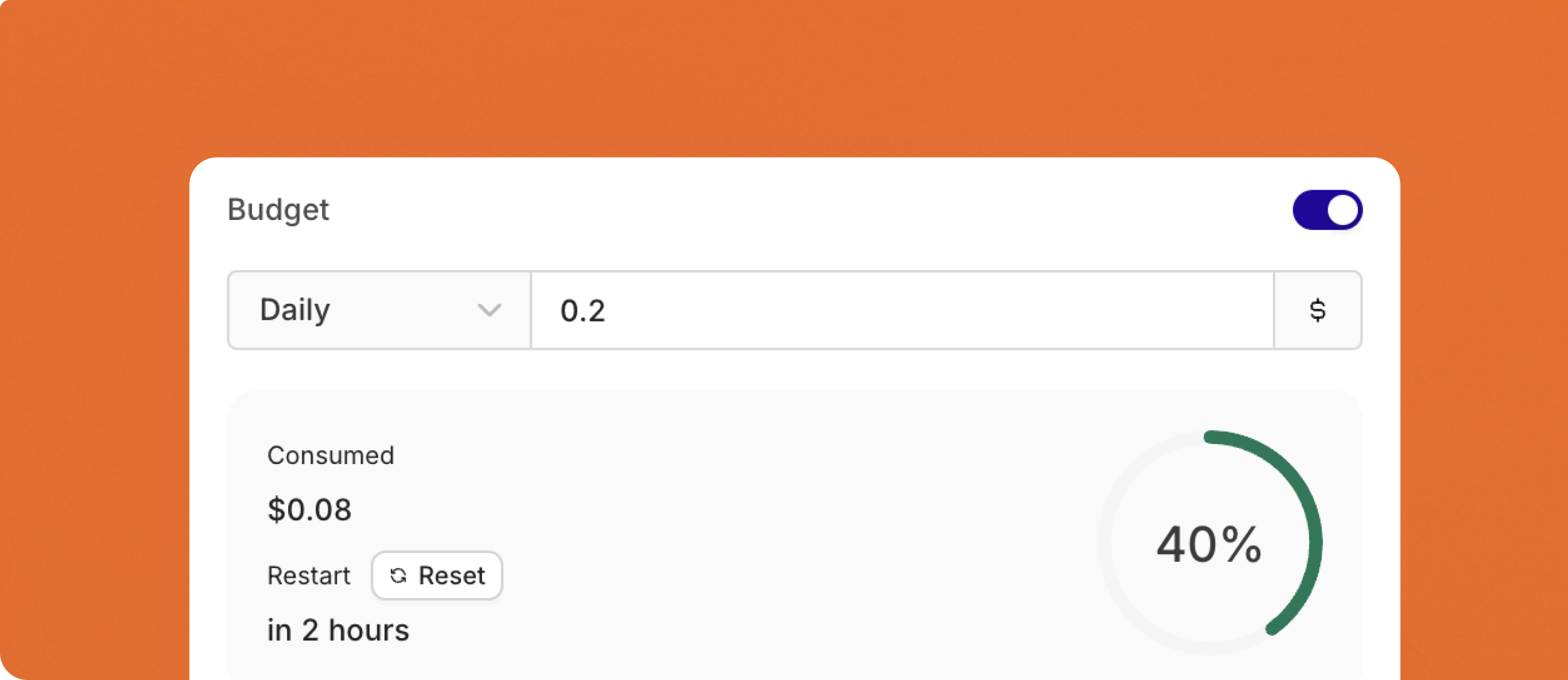
- Configure budgets with daily, weekly, monthly, or yearly reset cycles
- Automatic period boundary calculation with UTC timezone standardization
- Period-aligned cache TTL for optimal performance
-
New Budgets API to create budgets programatically
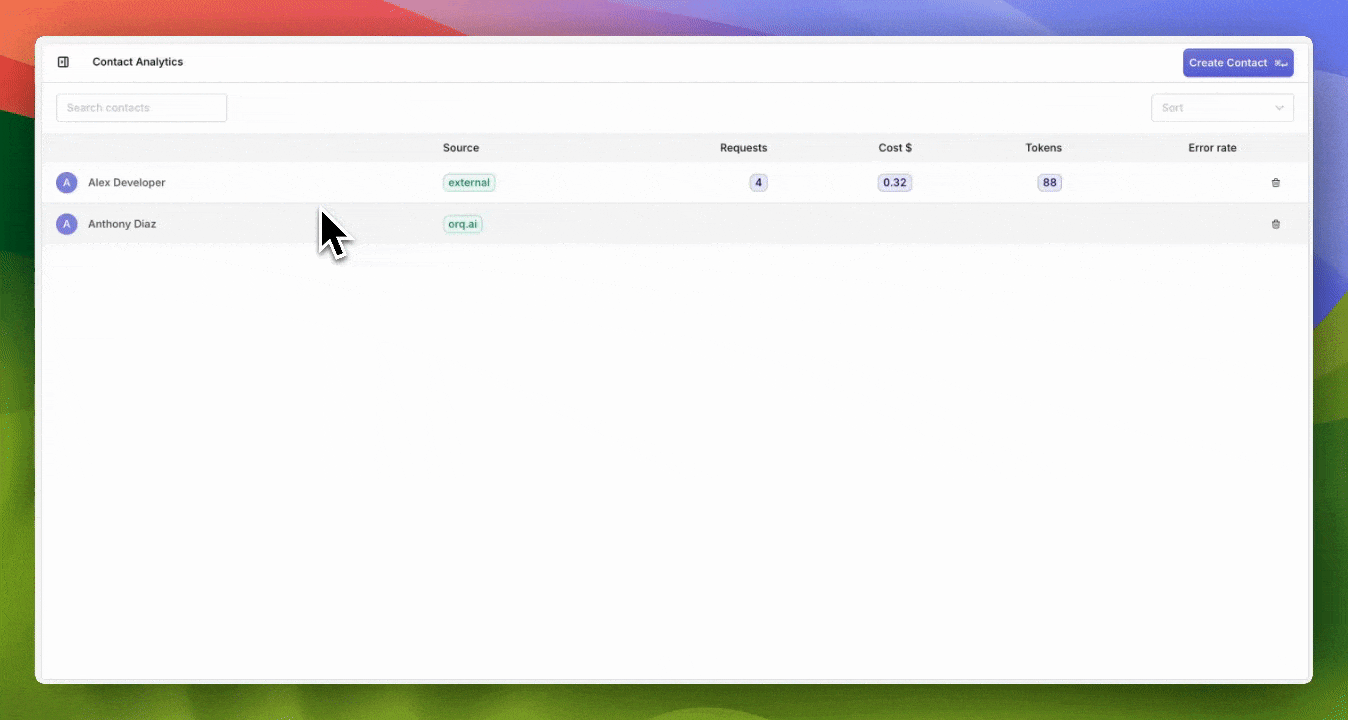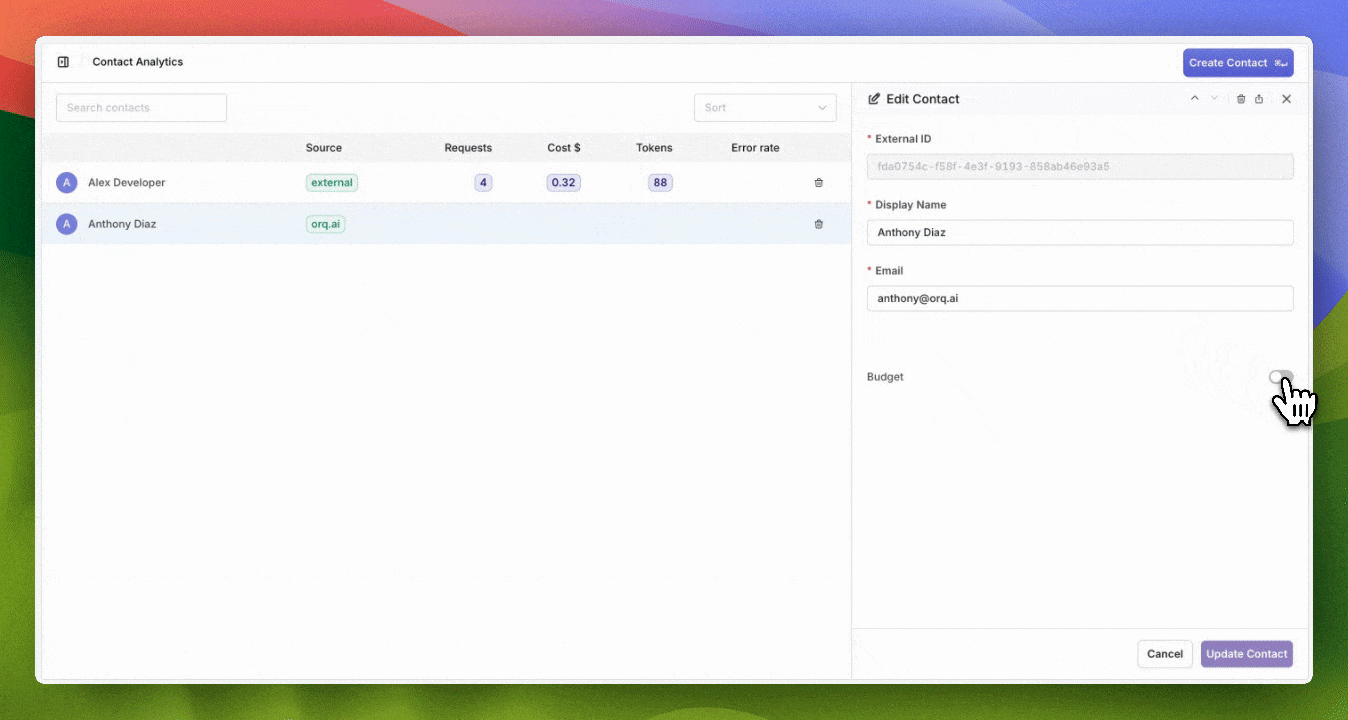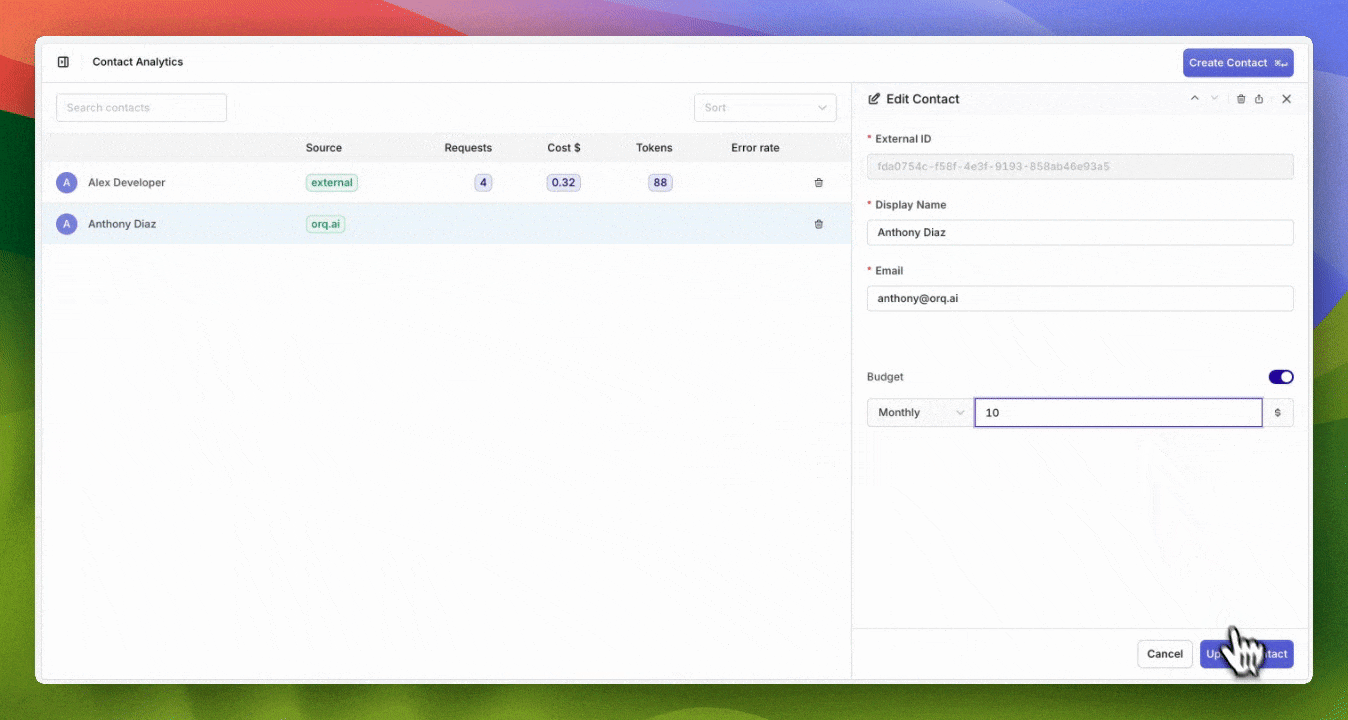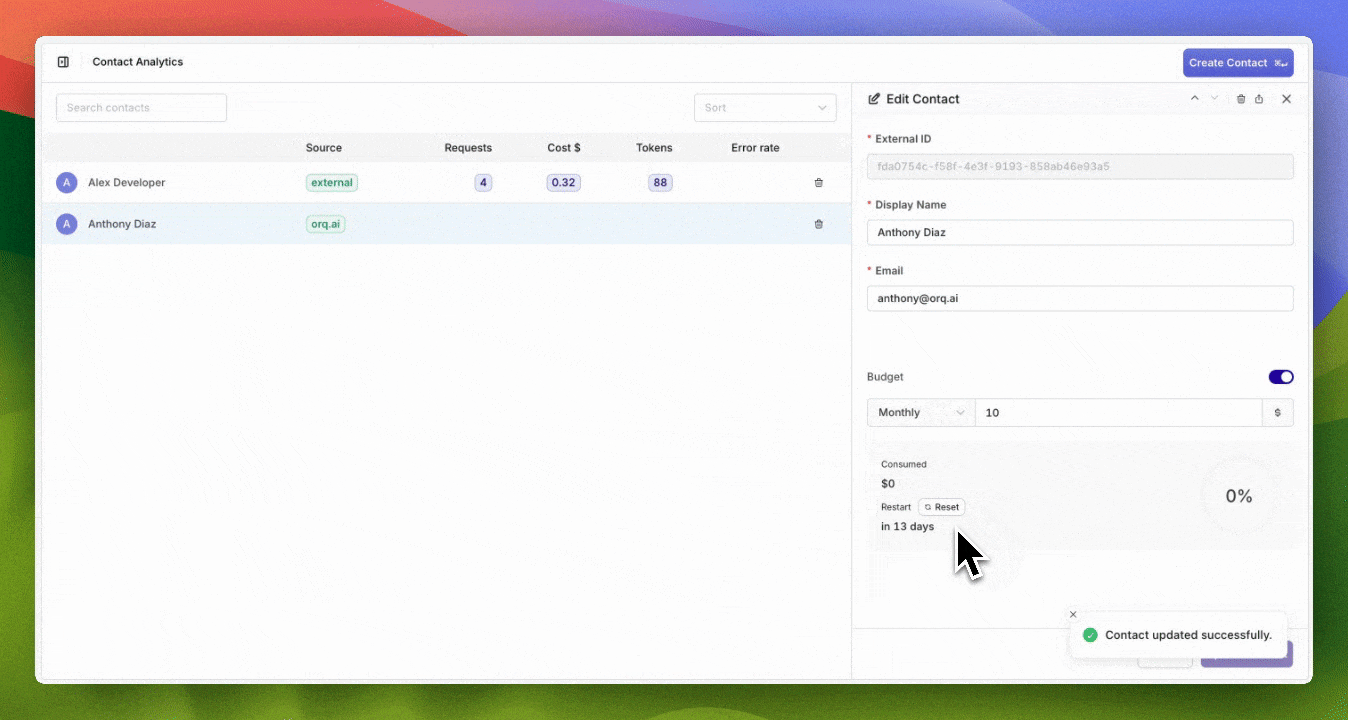
- Prevent individual users from exceeding allocated AI budgets
- Set department-level spending limits for enterprise teams
- Control costs across multiple AI models and services
To learn more about using Contacts, see Creating a Contact.
GPT-5 available in the AI Router
Today we’re introducing GPT‑5, OpenAI’s smartest, fastest, most useful model yet in the AI Router.
Preview Model Support
We will no longer support experimental and preview models by default in the AI Router.Going forward, access to preview or experimental models will only be granted upon request. Many of these models are unreliable in production, they regularly fail or become unavailable without notice, which leads to a poor experience and extra maintenance overhead.If you have a use case that specifically requires an experimental or preview model, please reach out to support@orq.aiThree new RAGAS Evaluators for enhanced RAG Experiments
We’ve added three new RAGAS evaluators to the Orq.ai platform, giving you deeper insights into your retrieval-augmented generation (RAG) workflows. These evaluators help you understand not just if the right information was retrieved, but how well your system handles noisy data and captures key context.Here’s what’s new:1. Context Recall
Measure how much of the relevant reference information your retrieval pipeline actually brings into context. This evaluator compares the retrieved text to the reference for each user query, helping you identify if important facts are missing. Use context recall to improve your retrieval strategy and ensure your LLM responses are always well-supported.Entities used:- Reference (ground truth)
- Retrieved text
- When you want to know if your retrieval step is actually surfacing all necessary information for the LLM to answer correctly.
2. Noise Sensitivity
Understand how your RAG system performs when irrelevant or “noisy” information is mixed into the retrieved context. This evaluator tests the robustness of your model by introducing noise and measuring the impact on your outputs. It’s a great way to benchmark reliability in real-world scenarios where retrieval isn’t always perfect.Entities used:- User message
- Reference (ground truth)
- Retrieved text (with added noise)
- When you want to see if your LLM can still provide accurate answers, even when extra, unrelated information appears in the context.
3. Context Entities Recall
Check whether the most important entities (names, places, organizations, etc.) present in your reference are also present in the retrieved context. This evaluator goes beyond text overlap and focuses on the coverage of key information units, helping you catch subtle gaps in your retrieval pipeline.Entities used:- Reference (ground truth)
- Retrieved text
- When you want to be sure your retrieval is capturing and surfacing all the essential entities needed to answer user queries correctly.
Use these new RAGAS evaluators to systematically assess and improve the quality, completeness, and reliability of your RAG pipelines right from within Orq.ai.
Flexbile Prompt Configuration for Experiments
Configuring Experiments just got more flexible.Previously, when setting up an Experiment, you could only use the prompt from your dataset (themessage column), or you had to set up your prompt manually in the prompt template. With this update, you can now combine both approaches, giving you far more control over your Experiments.This is especially useful if your application logs real user input from your AI features in production. Those logs often contain valuable user messages you want to test against different system prompts. With this update, you can easily combine actual user messages from your dataset with new or imported system prompts directly in your prompt template configuration. This allows you to experiment and see which prompt produces the best response, without needing to restructure your data.This improved flexibility makes it much easier to:- Systematically validate regression, improvements, and guardrail compliance
- Compare outputs for cost, latency, and consistency
- Run more realistic and effective experiments based on actual user input
Chunking API
The Chunking API is now live - the final building block for fully programmatic knowledge base workflows. With this new API, you can automatically split (“chunk”) your text data in the way that best fits your needs, all without leaving your workflow.The Chunking API supports six different chunking strategies, each suited to a different kind of content:- Token chunker: Splits your text based on token count. Great for keeping chunks small enough for LLMs and for consistent embedding sizes.
- Sentence chunker: Breaks your text at sentence boundaries, so each chunk stays readable and sentences remain intact.
- Recursive chunker: Chunks text by working down a hierarchy (paragraphs, then sentences, then words) to maintain document structure.
- Semantic chunker: Groups together sentences that are topically related, so each chunk makes sense on its own.
- SDPM chunker: Uses advanced skip-gram patterns to find natural split points, especially helpful for technical or structured documents.
- Agentic chunker: Uses an LLM to determine the best split points, ideal for complex documents that need intelligent segmentation.
📘 Try the Chunking API out for yourself here: Chunking
Evaluators API
We’ve expanded evaluator support with two new APIs, enabling much more flexible, code-driven workflows:- Evaluators Hub API: Run any evaluator on demand via API, without needing to attach it to an experiment or deployment. Ideal for integrating evaluator runs into your own pipelines or automated tools.
- Evaluators API: Create, retrieve, update, and delete evaluators directly via API. This allows you to fully manage your evaluators programmatically, instead of only through the UI.
- Decoupled Evaluation: Run and manage evaluators without relying on experiments or deployments.
- Full API Control: Create, update, and remove evaluators as your evaluation needs evolve.
- Pipeline Integration: Integrate both evaluator management and execution into your own data pipelines or CI/CD workflows.
- Faster Iteration: Quickly test, refine, and iterate on evaluators using code.
- Automation: Scale evaluations and management as needed for batch operations or continuous quality monitoring.
Connect LiteLLM models to Orq
You can now connect your LiteLLM-managed models directly to Orq.ai, making it even easier for teams already using LiteLLM to get started with Orq—without having to change your LLM gateway.Who is this for?This integration is ideal for teams who have standardized on LiteLLM for unified API access, flexible model management, or cost control—but want to benefit from Orq’s full platform for everything beyond just model access.How to get started:
- Go to the Integrations tab, click LiteLLM, and enter your base URL and API keys.
- In the AI Router, click Add Model, select Import from LiteLLM, and choose your model(s).
- No migration pain: Instantly connect your existing LiteLLM models, no rework needed.
- Keep your infra, add new superpowers: Keep LiteLLM as your gateway while gaining everything Orq offers for GenAI ops.
- Best of both worlds: For teams already invested in LiteLLM, this means you get prompt management, deployments, evaluation, and observability—on top of your existing setup.
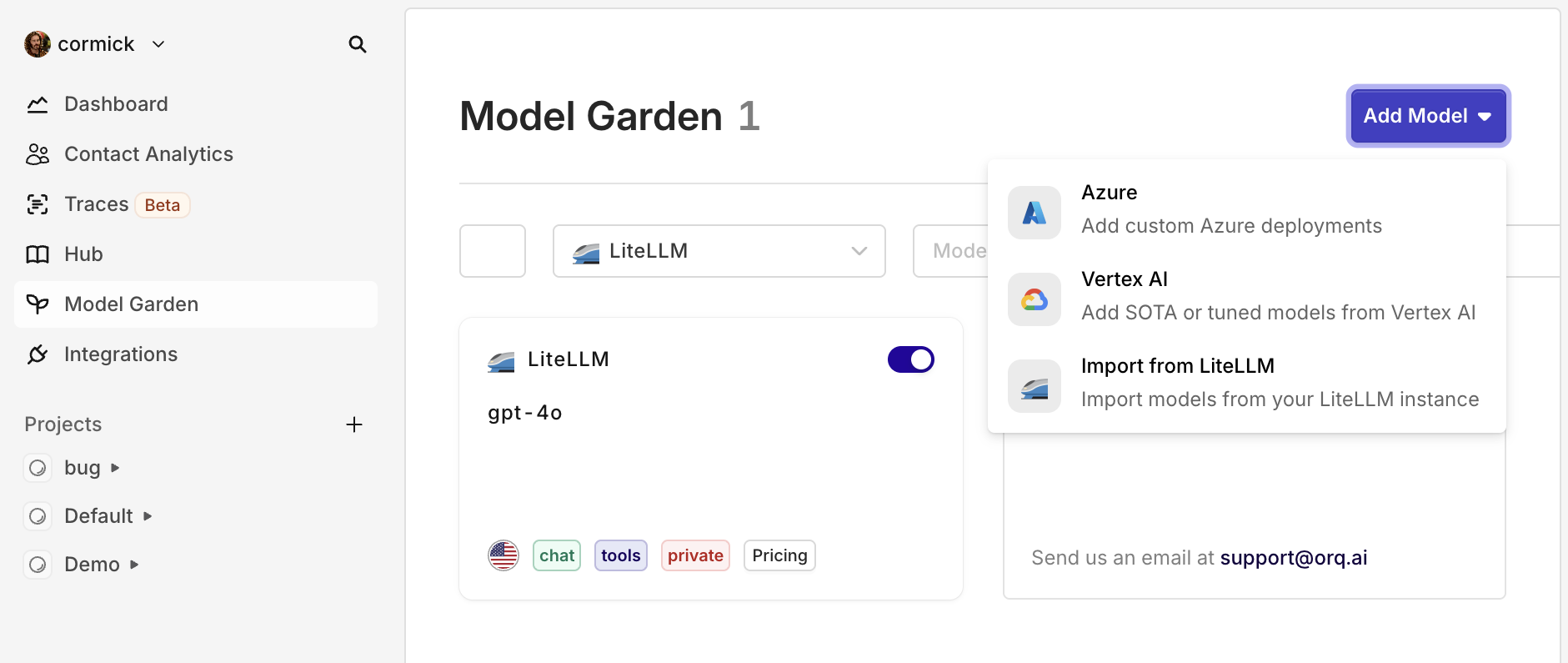
Self onboard Vertex AI models
You can now onboard your own VertexAI models, including fine-tuned and private models.Go to AI Router > Add model > Vertex AI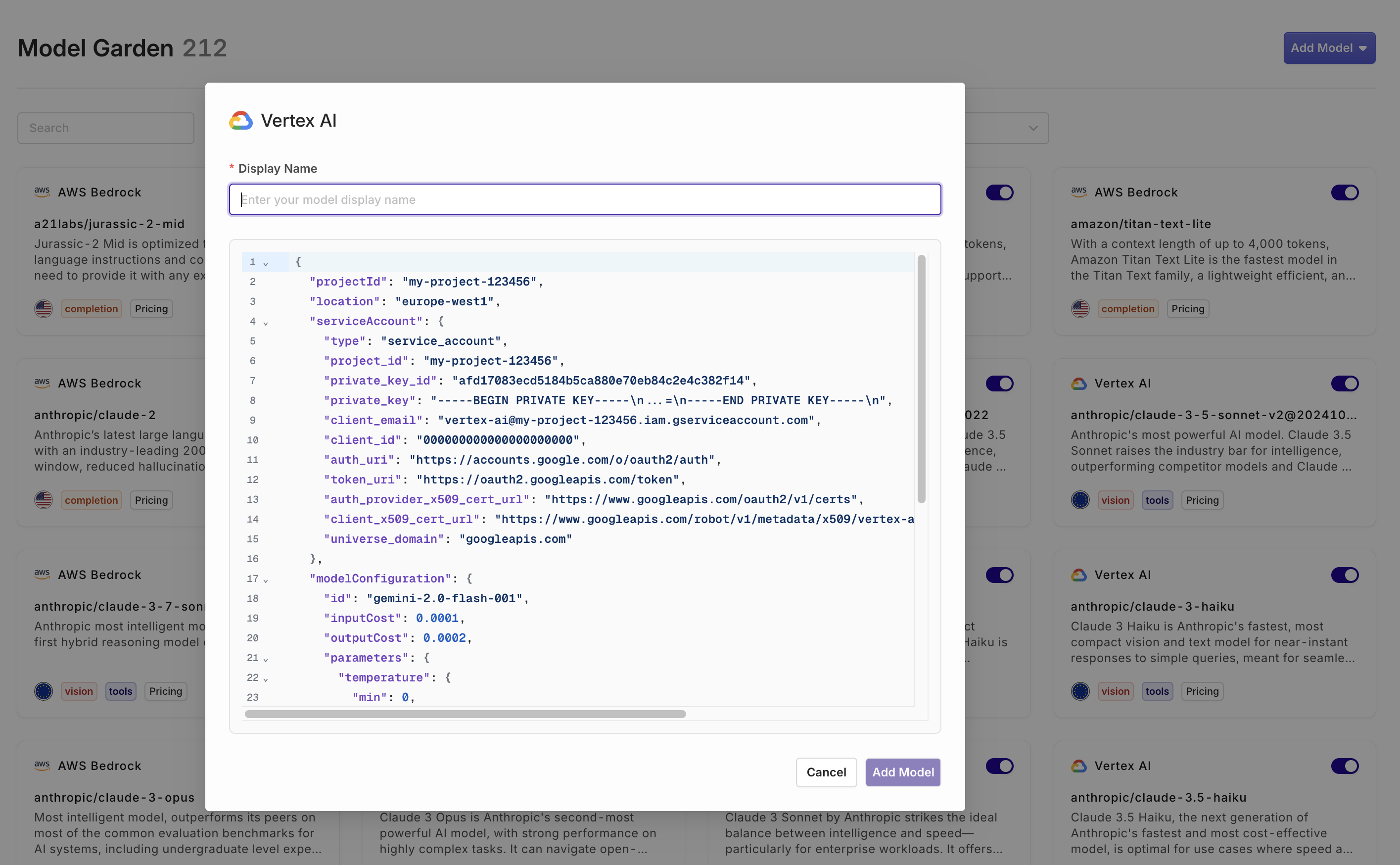
Custom Human Review
Today we’re introducing Custom human review, a major update that gives teams full flexibility in collecting and structuring human feedback in Orq.ai.With this release, you’re no longer limited to predefined review types. Now, you can create your own feedback forms tailored to your workflow and use case. Choose from three flexible input types:- Categorical: Create button options with your own labels, such as good/bad or saved/deleted.
- Range: Set up a custom scoring slider (for example, a scale from 0 to 100).
- Open field: Allow users to enter free-form feedback, perfect for more detailed comments.
How to collect feedback
There are two ways to collect feedback:- Orq Studio: Custom human review templates can be used directly within the Orq.ai platform, where colleagues and domain experts review AI outputs and provide structured feedback.
- API: Alternatively, developers can leverage the Orq API to expose these custom feedback forms in their own applications or products, allowing end users to submit feedback seamlessly.
Why this matters
Collecting high-quality, relevant human review is crucial for improving AI features. Teams can structure feedback in a way that makes sense for them, whether for quality control, prompt iteration, or continuous evaluation. All feedback is attached to the log, including prompts and outputs, making it easy for prompt engineers to refine configurations based on real-world usage.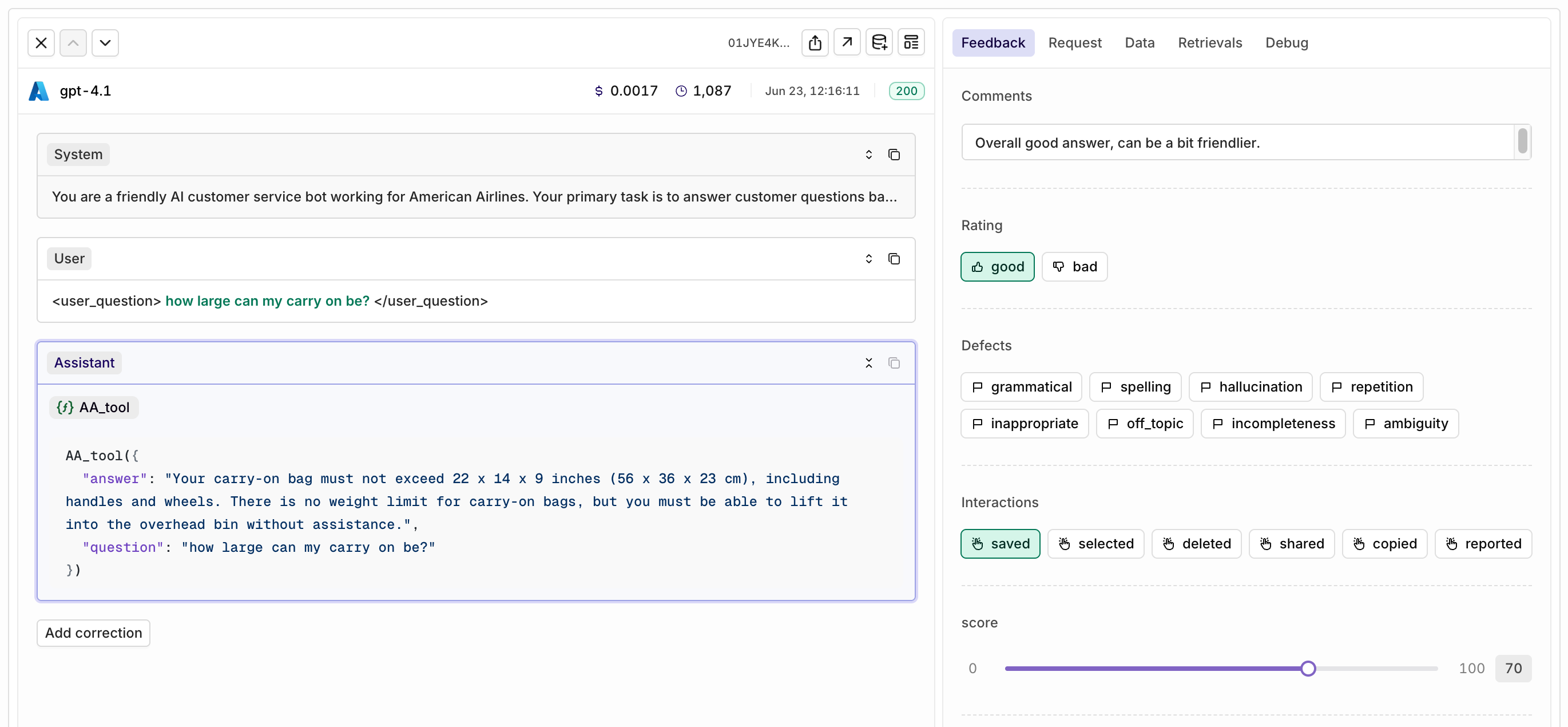
How to create custom Human Review
Evaluator playground
We’ve added a new way to quickly test your evaluators directly within the evaluator configuration screen.Previously, testing an evaluator meant attaching it to a deployment or running an experiment, often more work than needed for a quick check. With the new Test Your Evaluator playground, you can now try out your evaluator on the spot, using custom queries and responses.This makes it easier to iterate, validate, and fine-tune your evaluators, without leaving the configuration screen or disrupting your workflows.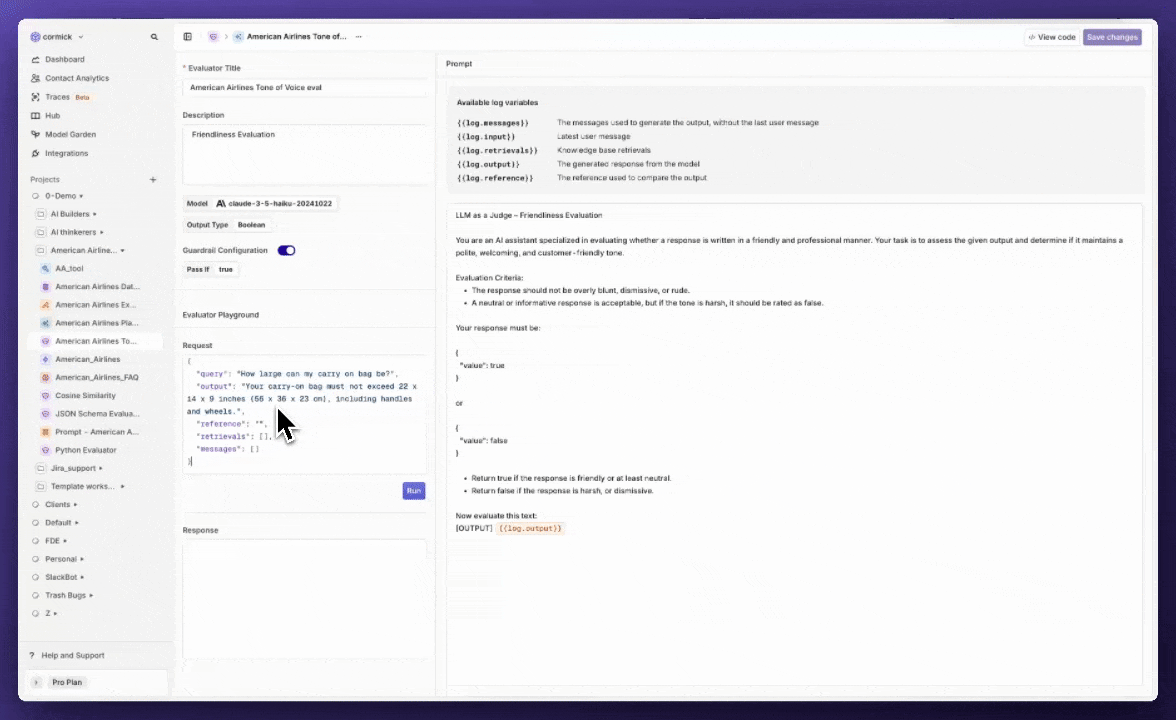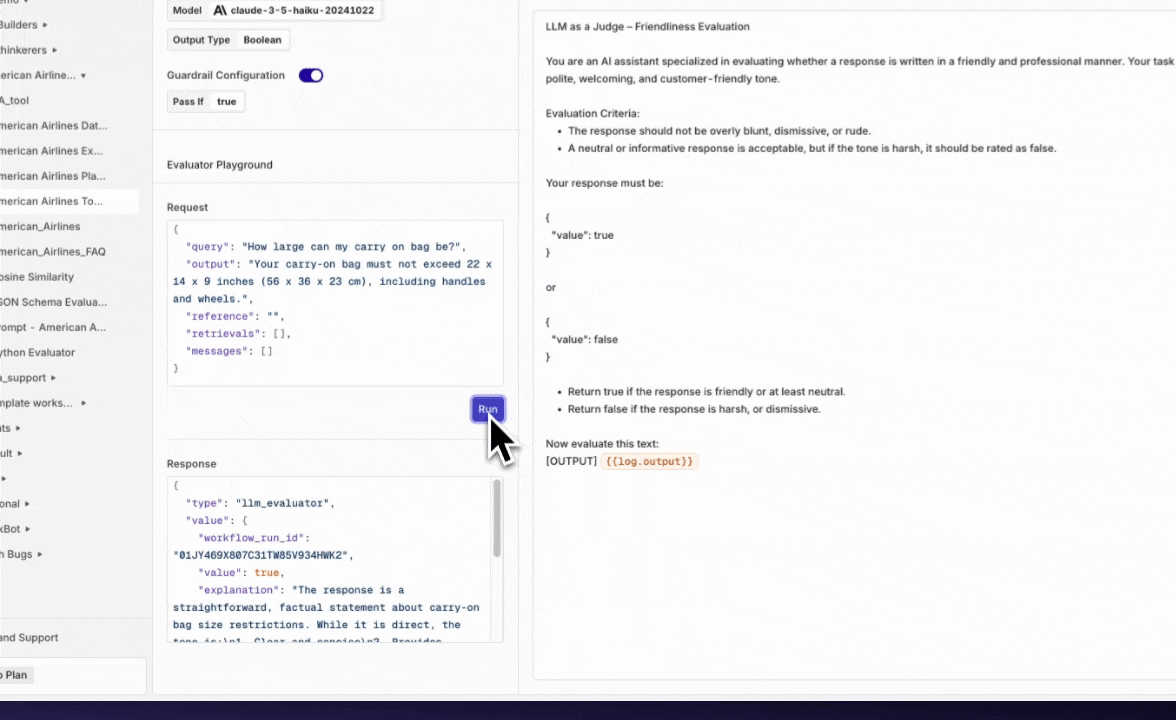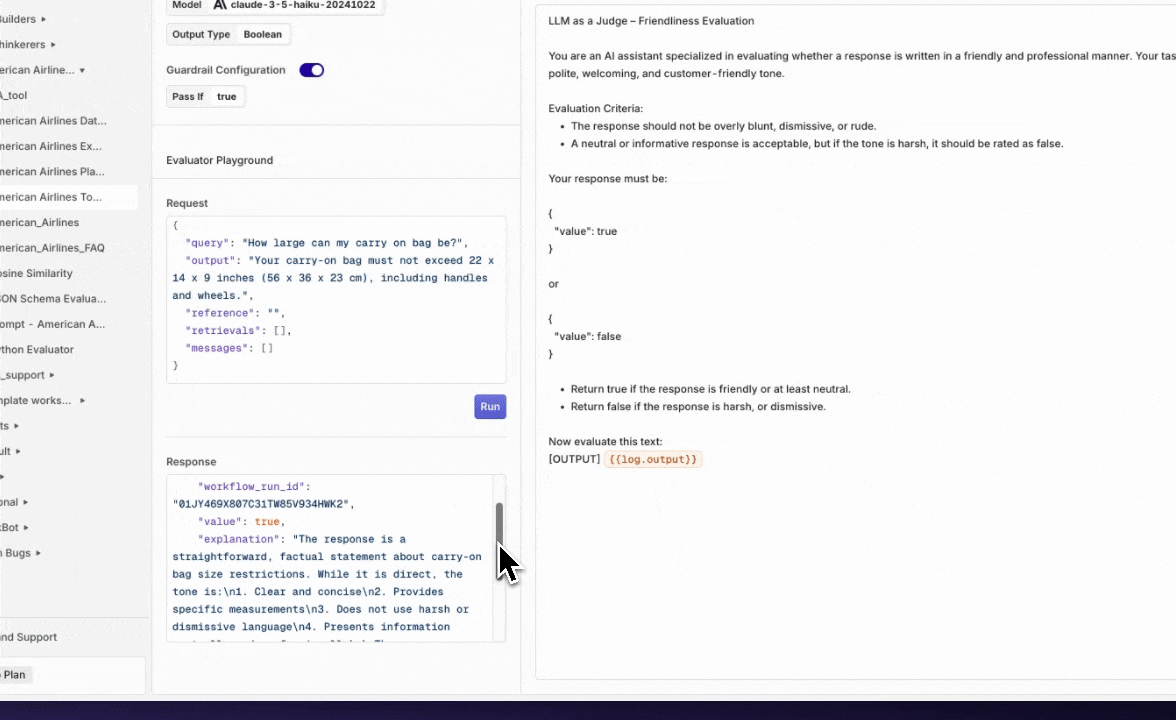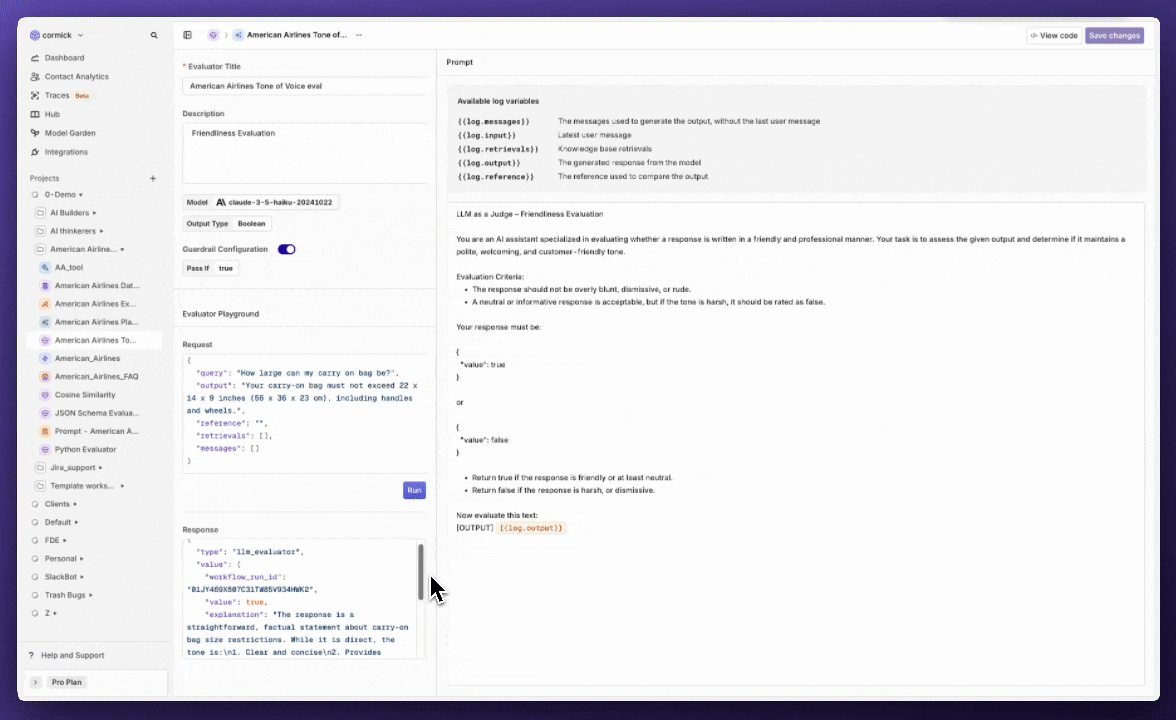
Attach files directly to the model
With our latest update, you can now attach PDF files directly to Gemini and OpenAI models. Simply include the encoded file in your deployment invocation, and the model will natively process the PDF - no more manual file uploads or bloated prompts.Why this matters- Better File Understanding: Models can directly analyze the content and structure of your PDFs—including text, images, tables, and diagrams - improving extraction quality and structured outputs.
- Cleaner Prompts: File data is no longer dumped into your system or user message, resulting in faster, less error-prone requests.
file_data should be using the standard data URI scheme (data:content/type;base64). See an example API call below:cURL
Python
Typescript
Evaluator runs without new generation
You can now evaluate existing LLM outputs without generating new responses. Previously, running an evaluator required creating a new output every time. With this update, you can retroactively score any response already stored in your dataset.Why this matters- Quality: Evaluate historical responses to ensure you’re assessing the true source of truth, not just new outputs.
- Flexibility: Apply evaluations to both** single responses and full conversation chains**, adapting to your specific review needs.
- Prepare your dataset including LLM outputs in the messages column.
- Set up an experiment and select one or more evaluators - do not select a prompt.
- The evaluator will analyze the responses already present in the “messages” column of your dataset.
Reasoning field now included in the API response
With the latest update to our reasoning models, API responses now include thereasoning and reasoning_signature fields. These additions provide more transparency into how the model arrives at its answers.See an example below:Experiment Runs overview
You can now compare different Experiment runs in a single overview using the new Runs tab.Previously, reviewing the results of multiple experiment runs required clicking into each run individually and manually comparing scores. This made it harder to spot improvements or regressions at a glance.With the new Runs overview, you get a clear, side-by-side comparison of all your experiment runs, including all your evaluator scores. This makes it much easier to see if recent changes to your prompt or model setup have led to measurable improvements, or unexpected regressions.Example:In the screenshot below, you can see that both Experiment Run #1 and #2 achieved a perfect score on the JSON Schema Evaluator (100), while Cosine Similarity improved from 0.65 to 0.69.No more clicking back and forth between runs, get instant insight into your progress in one place.
Improved Experiment configuration panel
Configuring your experiments just got a lot easier. The new side panel gives you a clear and organized overview of everything in your experiment, making setup and adjustments faster and more intuitive.With the improved configuration panel, you can instantly see:• Which prompts, models, and evaluators are included in your experiment
• The status and details of each prompt and evaluator
• A simple way to add or edit prompts and evaluators directly from the side panelThis new layout means you no longer have to dig through multiple screens or remember which components are active. Everything you need is visible at a glance, helping you stay organized and making it easier to experiment with different configurations.
Metadata filter on Knowledge Base Chunks
Knowledge Base chunks can now be enriched with metadata during creation via the Chunks API. When searching your Knowledge Base, you can filter results by metadata to target only the most relevant chunks—improving both accuracy and efficiency in retrieval.Highlights:- Add custom metadata to each Knowledge Base chunk at creation.
- Search using metadata filters to refine results.
Why this matters
As your Knowledge Base grows, searching through every chunk for every query can slow things down and introduce noise in responses. By tagging each chunk with metadata—such as document type, source, department, date, or custom tags—you gain precise control over what information gets retrieved. This ensures users and AI models only access the most relevant information, leading to faster, higher-quality answers and improved user experience.Example
If your company stores support articles in the Knowledge Base for multiple products, you can now instantly filter retrieval to only include articles for a specific product, version, or language—removing irrelevant matches and streamlining customer support.cURL
Python
Typescript
📘 To learn more about search, see Searching a knowledge base and the related API.
Claude 4 Sonnet & Opus
With the launch of Claude 4 Sonnet and Opus, Anthropic has introduced its most advanced AI models yet.Both models share the same large 200k token context window and up-to-date training data (March 2025), but they are designed for slightly different needs.| Feature | Claude 4 Sonnet | Claude 4 Opus |
|---|---|---|
| Context Window | 200k tokens | 200k tokens |
| Training Cutoff | March 2025 | March 2025 |
| Max Output Tokens | 64k | 32k |
| Input Price | $3 / million tokens | $15 / million tokens |
| Output Price | $15 / million tokens | $75 / million tokens |
| Performance Summary | Improved reasoning and intelligence vs Sonnet 3.7 | Most capable model with superior reasoning |
| Latency | Moderate | Slow |
| When to use? | Best price/ value and capable enough for 95% use cases | Best for complex tasks needing deep analysis where speed is not important |
Tool response in Playground
We’ve enhanced the Playground experience by introducing interactive tool responses. When you’re using tools (also known as function calls) within your workflow, you can now seamlessly provide the tool response back to the model, enabling continuous and efficient testing of your workflows.How it works:Invoke Tools: When your model calls a tool (e.g.,get_weather), it provides the tool name and relevant arguments.Interactive Response: Previously, your workflow paused here, requiring manual intervention. Now, you can directly give the tool response back to the model or use the handy Tab shortcut to auto-generate a suggested response.Continue Workflow: With the tool response provided, the model can continue, generating a final, context-aware response.This new capability simplifies debugging and allows you to rapidly prototype sophisticated workflows without interruption. See an example below.OpenAI’s new o3, o4-mini, GPT-4.1 models
OpenAI’s latest models can be found in the AI Router.When to use what model
- o-series models are purpose-built for reasoning and tool-use. Choose o3 when raw capability beats everything else; use o4-mini when you still need strong reasoning but want 10× cheaper tokens and snappier replies.
- GPT-4.1 family is the evolution of the “generalist” GPT line. The full model gives you 1 M-token context with strong instruction following; mini trims cost/latency for mainstream workloads; nano pushes pricing and speed to the floor for simple or massive-scale tasks.
| Feature | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | o3 | o4 mini |
|---|---|---|---|---|---|
| Training cutoff date | May 2024 | May 2024 | May 2024 | May 2024 | May 2024 |
| Context window | 1M | 1M | 1M | 200k | 200k |
| Max output tokens | 32.768 | 32.768 | 32.768 | 100k | 100k |
| Input price | $2/M Tokens | $0.40/M Tokens | $0.10/M Tokens | $10/M tokens | $1.10/M tokens |
| Output price | $8/M Tokens | $1.60/M Tokens | $0.40/M Tokens | $40/M tokens | $4.40/M tokens |
| Latency | Moderate | Fast | Very fast | Slow | Moderate |
| When to use? | Long-context chat, knowledge-work, multimodal apps needing top GPT quality | Everyday product features, prototyping & chat where speed and price count | Real-time, latency-critical or large-scale batch jobs on a tight budget | Deep research, complex multi-step reasoning, high-stakes coding/science tasks | Reasoning workloads where cost & throughput matter; API agents, math & data-science |
Rate Limits
To ensure fair usage and consistent performance, we’ve introduced rate limits for all Orq.ai APIs on a per-account basis. This helps prevent server overload, reduces risk of abuse, and keeps costs manageable.If your account exceeds its rate limit, you’ll receive a429 Too Many Requests response.Rate limits vary by subscription tier:| Subscription | Rate Limit for Deployment API calls | Rate Limit for other API calls | Log retention |
|---|---|---|---|
| Sandbox | 100 API calls/minute | 20 API calls/minute | 3 days |
| Team (Legacy) | 1000 API calls/minute | 50 API calls/minute | 14 days |
| Pro | 2000 API calls/minute | 100 API calls/minute | 30 days |
| Enterprise | Custom | Custom | Custom |
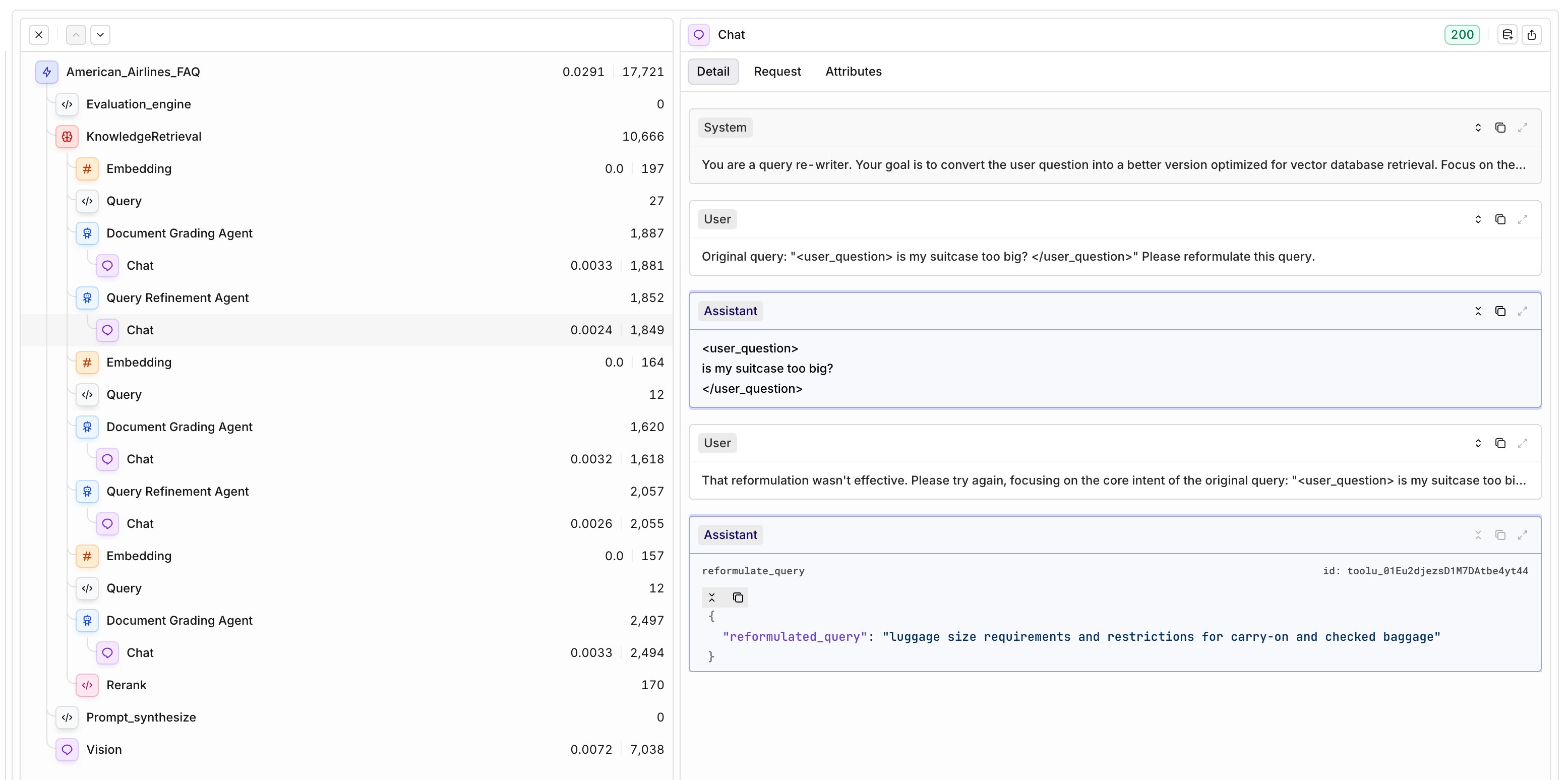
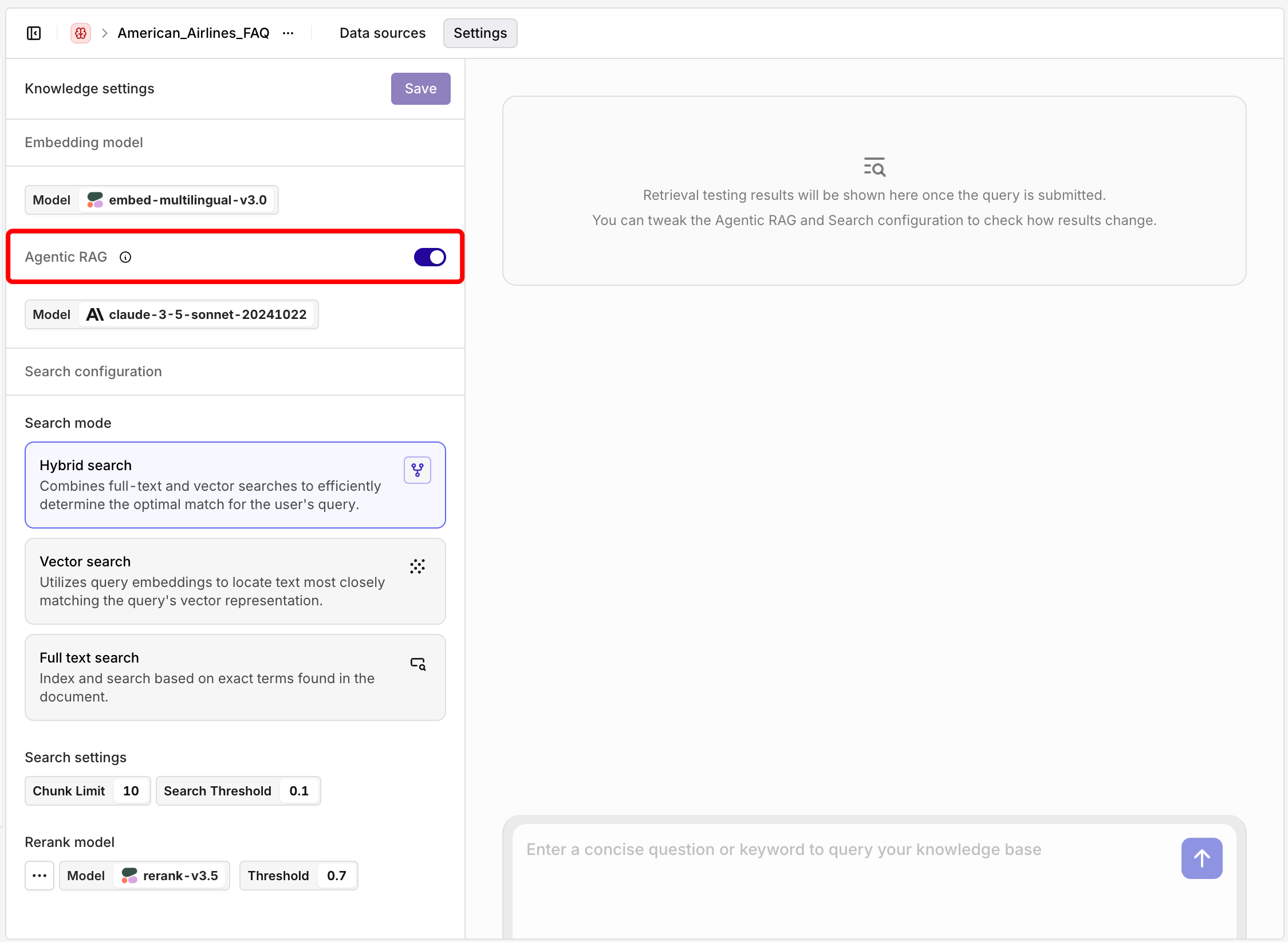
Agentic RAG
You can now enable Agentic RAG in your deployments to improve the relevance of retrieved context and the overall output quality.Once toggled on, simply select a model to act as the agent. The agent will automatically check if the retrieved knowledge chunks are relevant to the user query. If they aren’t, it rewrites the query — preserving the original intent — to improve retrieval results.This iterative refinement loop increases the chance of surfacing useful context from your Knowledge Base, giving the language model better grounding to generate high-quality, reliable responses. The setup includes two key components:- Document Grading Agent – determines if relevant chunks were retrieved.
- Query Refinement Agent – rewrites the query if needed.
Threads
We’ve added a new Threads view to help you make sense of multi-step conversations at a glance.Each thread captures the full back-and-forth between the user and the assistant, showing just the inputs and outputs per step—without the technical breakdowns like embeddings, rerankers, or guardrails. It’s ideal for reviewing how the conversation unfolds across multiple steps.The Thread Overview includes:- Start time and last update
- Total duration
- Number of traces (steps)
- Total cost and tokens used
- Project name and session ID
- Custom tags to help categorize threads
- Project
- Tags
- Start date
📘 To start using the Threads function add a thread id during the deployment invocation, to learn more, see Threads.
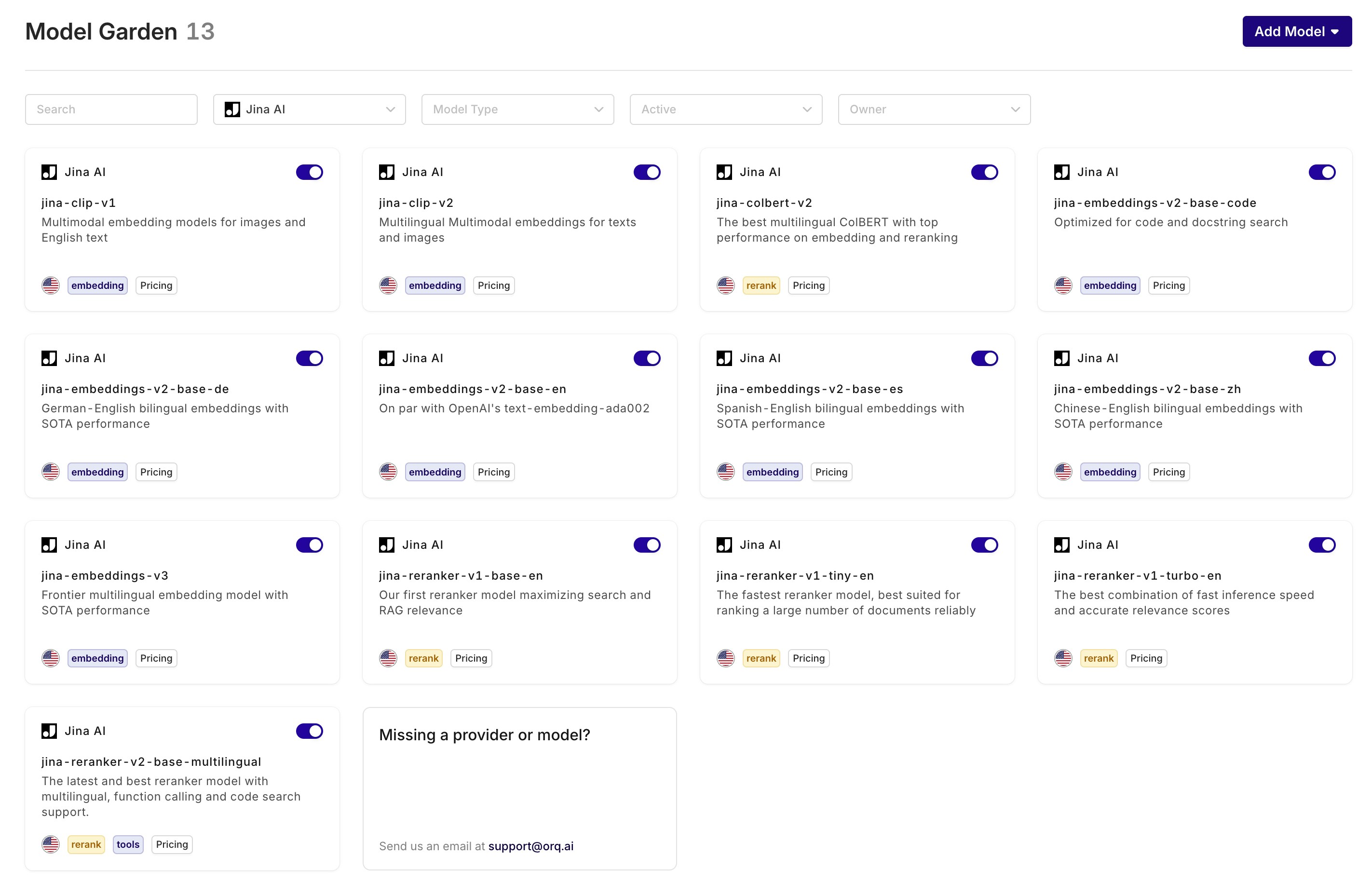
Jina AI - new embedding and rerank models
We’ve added Jina AI as a new provider, bringing a suite of high-performance models to the platform:- Multilingual Embedding Models: Use Jina AI’s embedding models—like jina-embeddings-v3, supporting 89 languages and sequences up to 8,192 tokens.
- Efficient Rerank Models: Choose from three reranker variations:
- Tiny – optimized for speed and low memory use.
- Turbo – a balance between speed and accuracy.
- Base – best-in-class accuracy for critical use cases.
Knowledge Base API
Previously, creating and managing a knowledge base required using the Orq UI. Users had to manually create a knowledge base, upload one file at a time, and define a chunking strategy per datasource. While simple, this process was time-consuming, especially for developers looking to scale or automate their workflows.With the new Knowledge Base API, all major operations are now available programmatically. You can create and manage knowledge bases, upload datasources, generate or manage chunks, and perform retrieval-related actions, all through code.This opens up much more flexibility, especially for teams working on complex chunks. You can now:• Perform chunking on your own side, tailored to your data structure
• Bring your own chunks—and even include your own embeddings
• Let Orq embed the chunks if embeddings aren’t provided, using the model specified in your API callNote: Attaching custom metadata to chunks isn’t supported yet but will be added soon.Available operations:
• Knowledge bases: create, list, retrieve, update, delete
• Datasources: create, list, retrieve, update, delete
• Chunks: create, list, retrieve, update, delete
• Search: inspect what’s being retrievedWhether you’re working with a single file or a dynamic content pipeline, this update makes the knowledge base workflow faster, more flexible, and developer-friendly.
📘 Read more on the Knowledge API in our docs or in the SDKs

Hub
We’ve added a new feature called the Hub — a library where you can browse and reuse common evaluators and prompts for your projects.Instead of starting from a blank screen, you can now add ready-made components with one click. Some can be fully customized after adding them to your project (like prompts or classification evaluators), while others — such as traditional NLP metrics like cosine similarity — are fixed by design.The goal: make it easier to start with off-the-shelf evals and prompts.At launch, the Hub includes prompts and evaluators. Soon, you’ll also find datasets, tools, and other entities here to further speed up your workflow.You can find the Hub in the left-hand menu of your workspace.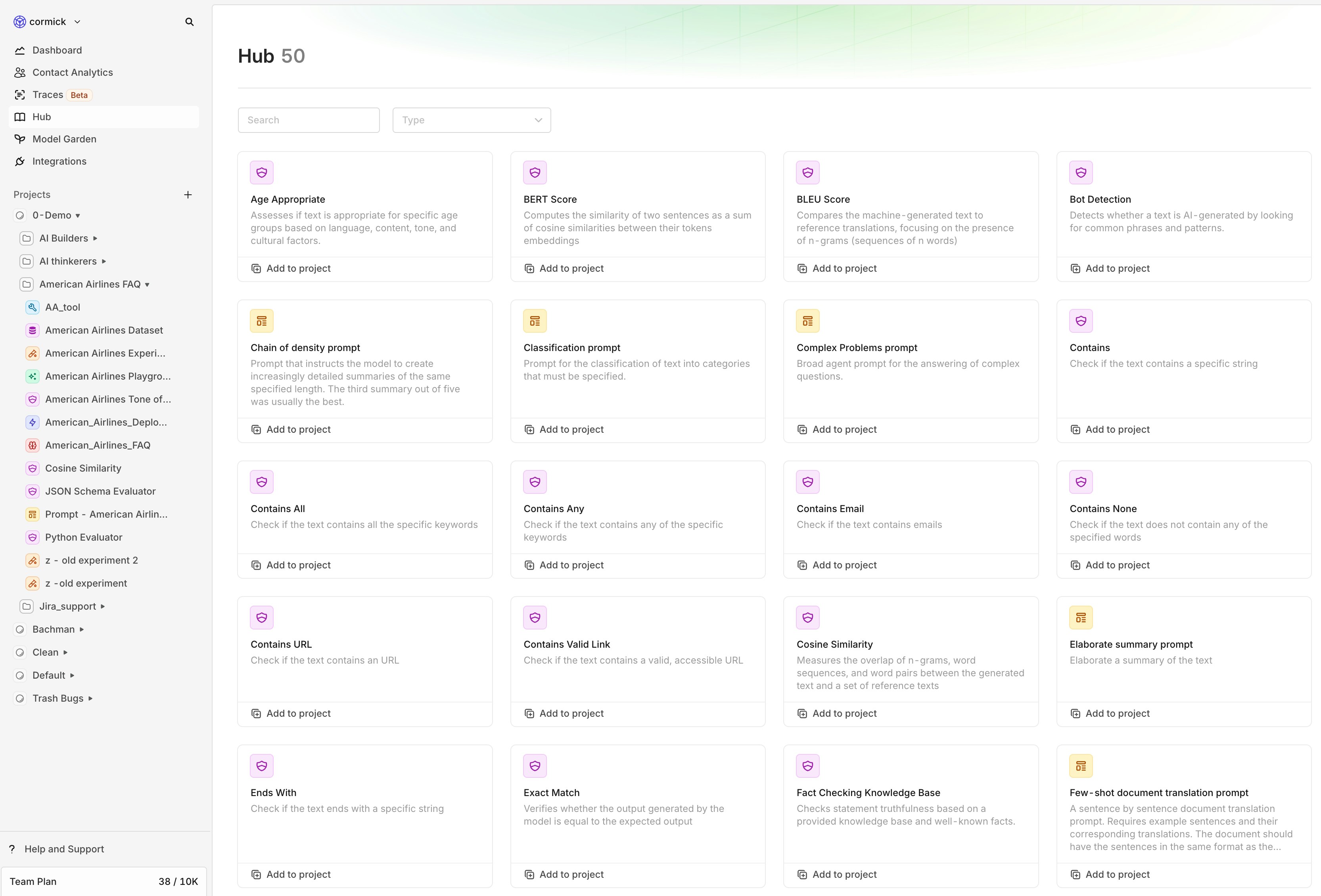
Tracing
AI workflows can feel like a black box—when something goes wrong, it’s hard to know why. Tracing changes that by giving you full visibility into every step of your workflow. Instead of guessing why an LLM output is wrong, you can quickly check every step in the workflow—saving time and reducing frustration.With this release, you can inspect all events that occur within a trace, including:- Retrieval – See which knowledge chunks were fetched.
- Embedding & Reranking – Understand how inputs are processed and prioritized.
- LLM Calls – Track prompts, responses, and latency.
- Evaluation & Guardrails – Ensure quality control in real time.
- Cache Usage – Spot inefficiencies in repeated queries.
- Fallbacks & Retries – Detect when your system auto-recovers from failures.
Billing impact - Event count
With the introduction of Traces, all the events seen in the overview will count towards the number of events. This has direct impact on the billing.An example: A chat request with 2 evaluators was historically counted as 1 request but will now be counted as 3 events.Python Evaluators
When building AI features, ensuring high-quality and reliable outputs is crucial. Orq.ai allows you to implement custom evaluators in Python, giving you full control over how AI-generated content is assessed and validated.Benefits of Using Python for Evaluators
- Flexibility & Customization
- Seamless Integration
- Preloaded with NumPy
- Automated & Scalable
📘 Read here how to set up a custom Python Evaluator, see our docs
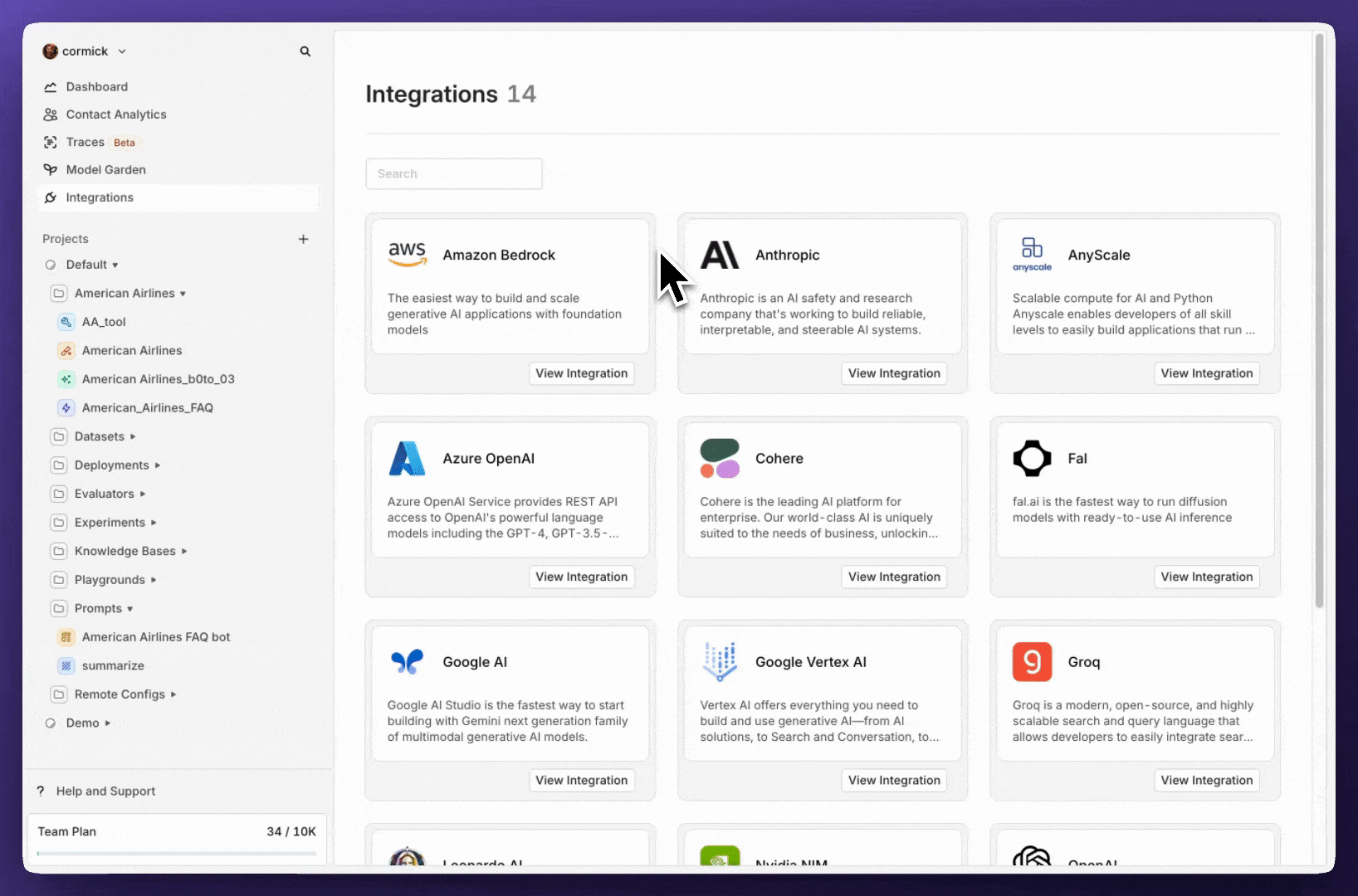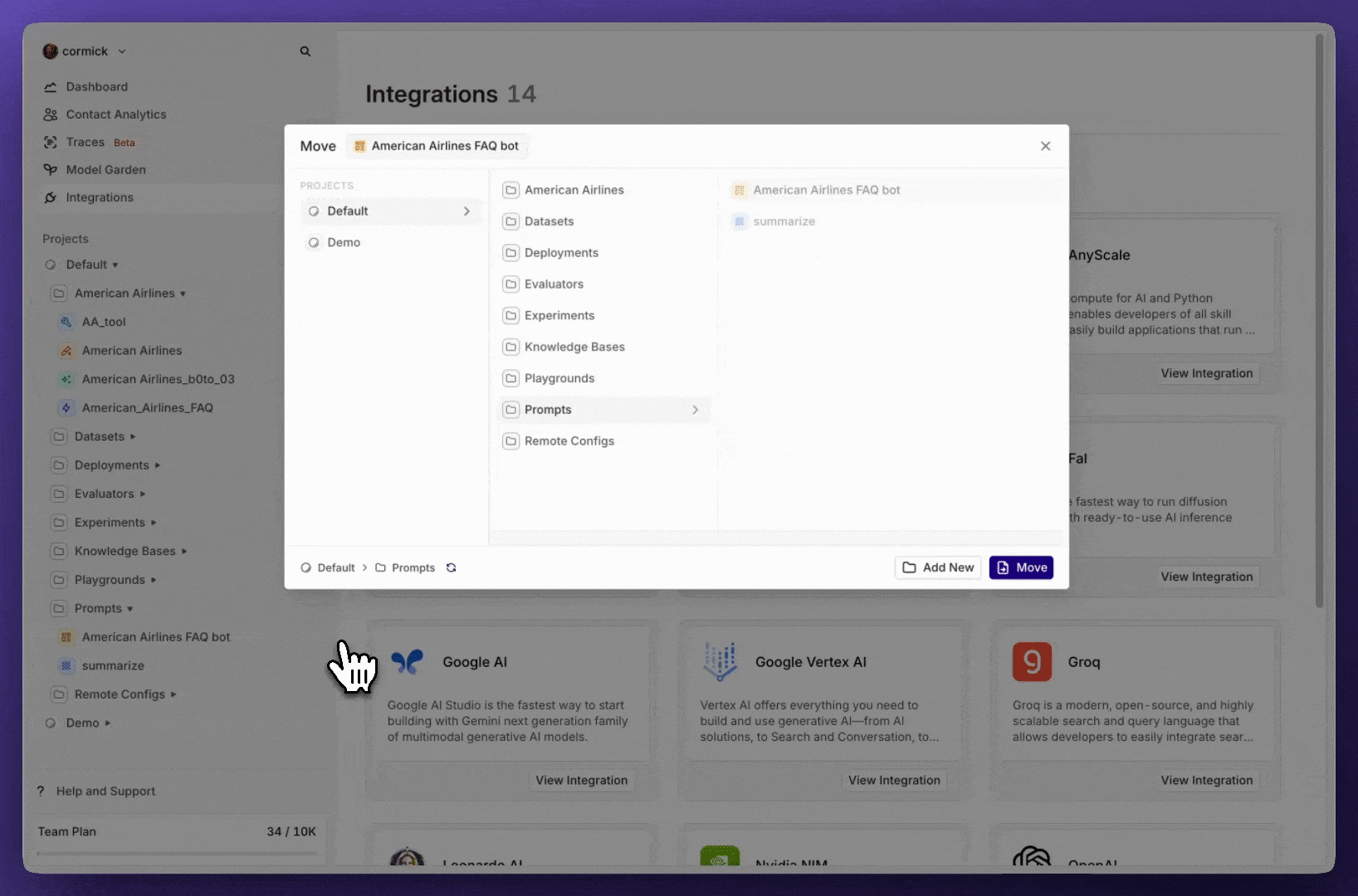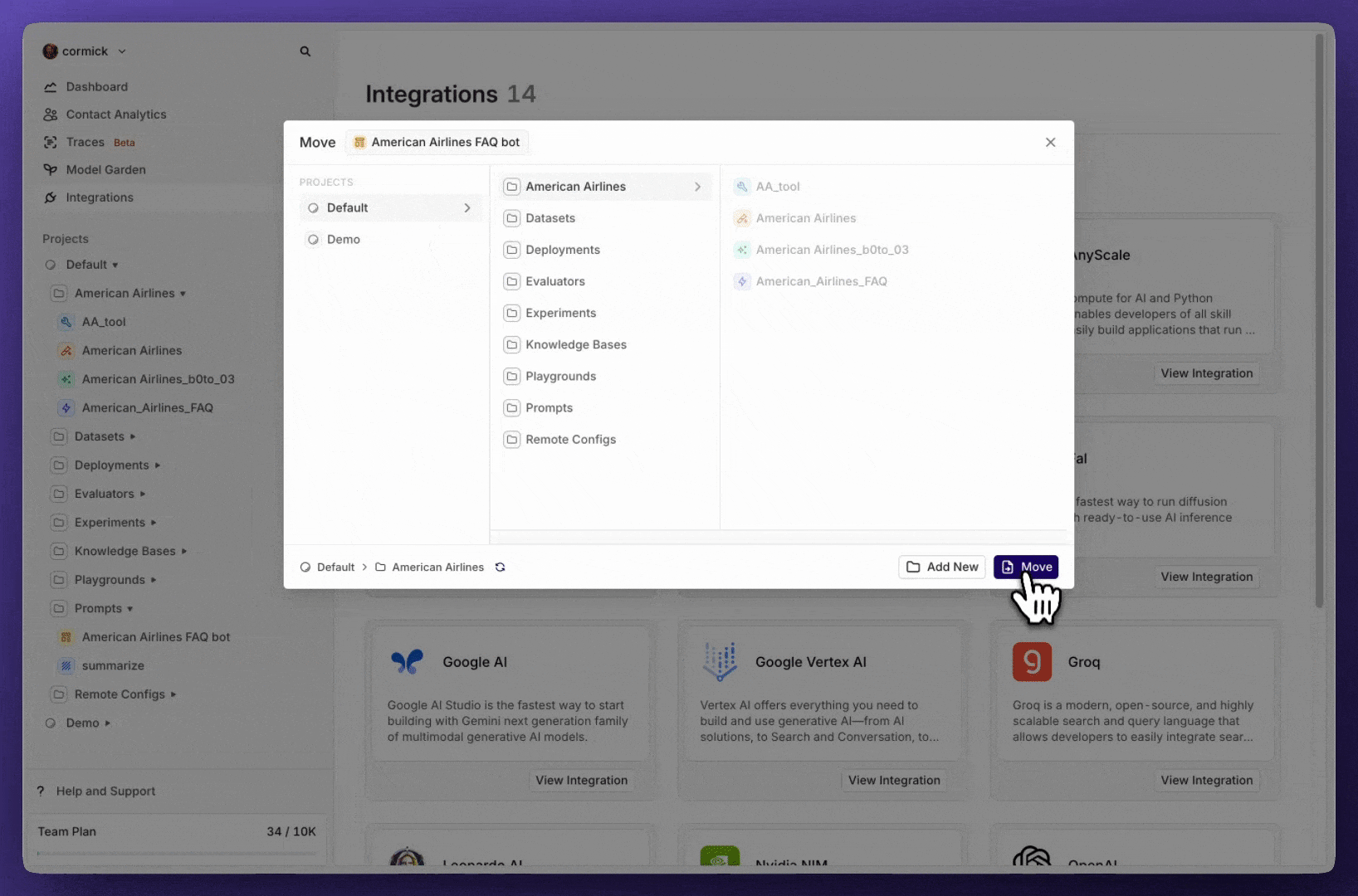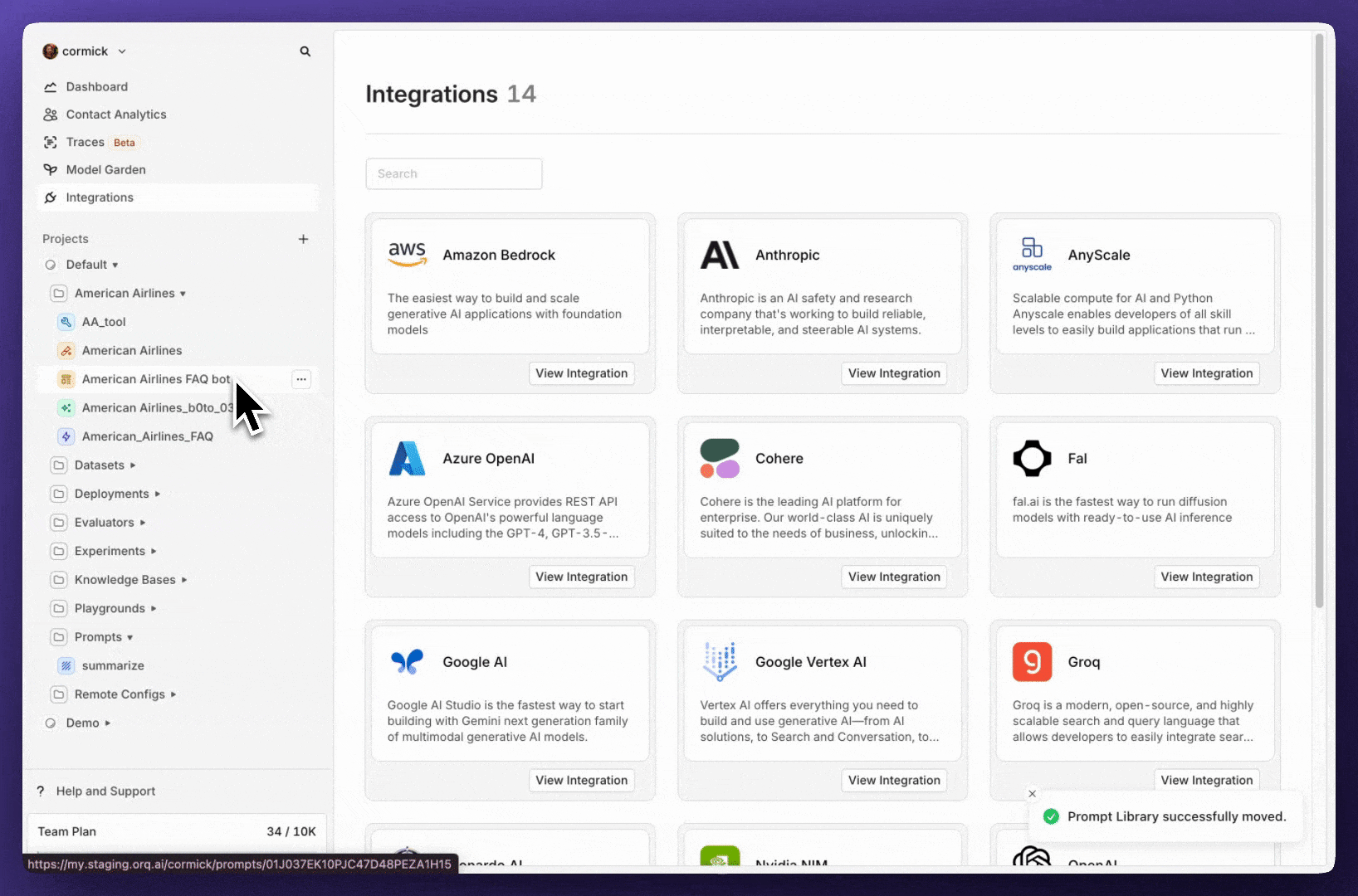
Move entities
Previously, once an entity was created, it was locked in place—you couldn’t move it to another project or directory. Now, you finally can.With this new feature, users can seamlessly move entities and directories to different projects and directories, ensuring better organization and flexibility in managing data.Key Details:
- Move entities and directories freely between projects and directories.
- Maintain project-level permissions—entities will only be visible to the selected teams assigned to that project.
- Improve workflow efficiency by keeping related entities together where they belong.
How It Works
GPT 4.5
OpenAI has unveiled GPT-4.5, its latest and most advanced AI language model to date. Building upon the foundation of GPT-4o, GPT-4.5 offers enhanced pattern recognition, deeper world knowledge, and a more refined conversational experience. This release aims to provide users with a more intuitive and reliable AI assistant for a variety of applications.Why It Matters
GPT-4.5 represents a significant step forward in AI-human interaction. By reducing instances of AI “hallucinations” and improving emotional intelligence, users can expect more accurate and contextually appropriate responses. These enhancements are particularly beneficial for tasks requiring creativity, empathy, and nuanced understanding, such as content creation, customer support, and personal assistance.What’s New?
Enhanced Knowledge: GPT-4.5 has been trained on a broader dataset, resulting in a more comprehensive understanding of various topics and improved factual accuracy.Improved Conversational Abilities: The model now exhibits a more natural and emotionally nuanced conversational style, making interactions feel more like engaging with a thoughtful human.Reduced Hallucinations: Through advanced training techniques, GPT-4.5 significantly lowers the occurrence of generating incorrect or fabricated information, enhancing user trust.Additional Enhancements
- Training Innovations: GPT-4.5 combines traditional supervised fine-tuning with scalable alignment, where smaller models generate high-quality training data for larger models. This approach accelerates training and improves the model’s ability to follow nuanced instructions.
- Multilingual and Multimodal Support: The model shows moderate gains in understanding multiple languages and processing various data types, making it versatile for global applications.
Performance & Analysis Tools
- Benchmark Evaluations: GPT-4.5 demonstrates solid improvements over GPT-4o, especially in math (+27.4%) and science (+17.8%), making it more reliable for factual reasoning.
- User Feedback Integration: OpenAI encourages users to engage with GPT-4.5 and provide feedback to further refine its capabilities and address any limitations.
-
Complex reasoning: Even though GPT-4.5 is an improvement over GPT-4.o, for more complex reasoning tasks, you should use o3-mini.

Claude 3.7 Sonnet
Claude 3.7 Sonnet is Anthropic’s most intelligent AI model yet, introducing hybrid reasoning, fine-tuned for business use cases, and an extended 200K context window.🚧 We don’t return the thinking message yet, only the final output will be shown
📘 The model is available through Anthropic and Vertex AI
🚧 In AWS, the model is only available in the US region
Thinking - Budget tokens Parameter
With the introduction of the new model, we also introduce a new parameter with it: Thinking - budget tokensUsing this parameter users can enable/ disable the models reasoning capabilities. Additionally, you can set how many tokens should be dedicated for its ‘thinking’ step. We do recommend a minimum of 1024 budget tokens. A value of 0 means the thinking is disabled. The budget tokens should never exceed the Max Tokens parameter because it still needs tokens to generate a final answer.Key highlights
🧠 Hybrid Reasoning Model- First-of-its-kind AI that can provide instant responses or extended, step-by-step reasoning based on user preference.
- API users can control “thinking time” to balance speed, accuracy, and cost.
- Improved ability to analyze charts, graphs, and complex diagrams, making it ideal for data science, analytics, and business intelligence.
- Enhanced reasoning and natural conversation flow make it ideal for interactive AI assistants that connect data, make decisions, and take actions.
- Automate complex workflows and repetitive tasks with industry-leading instruction following and tool integration.
- Supports a 200K context window for deep comprehension of long documents, knowledge bases, and large datasets.
- 128K output tokens (beta)—15x longer responses, enabling extensive code generation, planning, and detailed analysis.
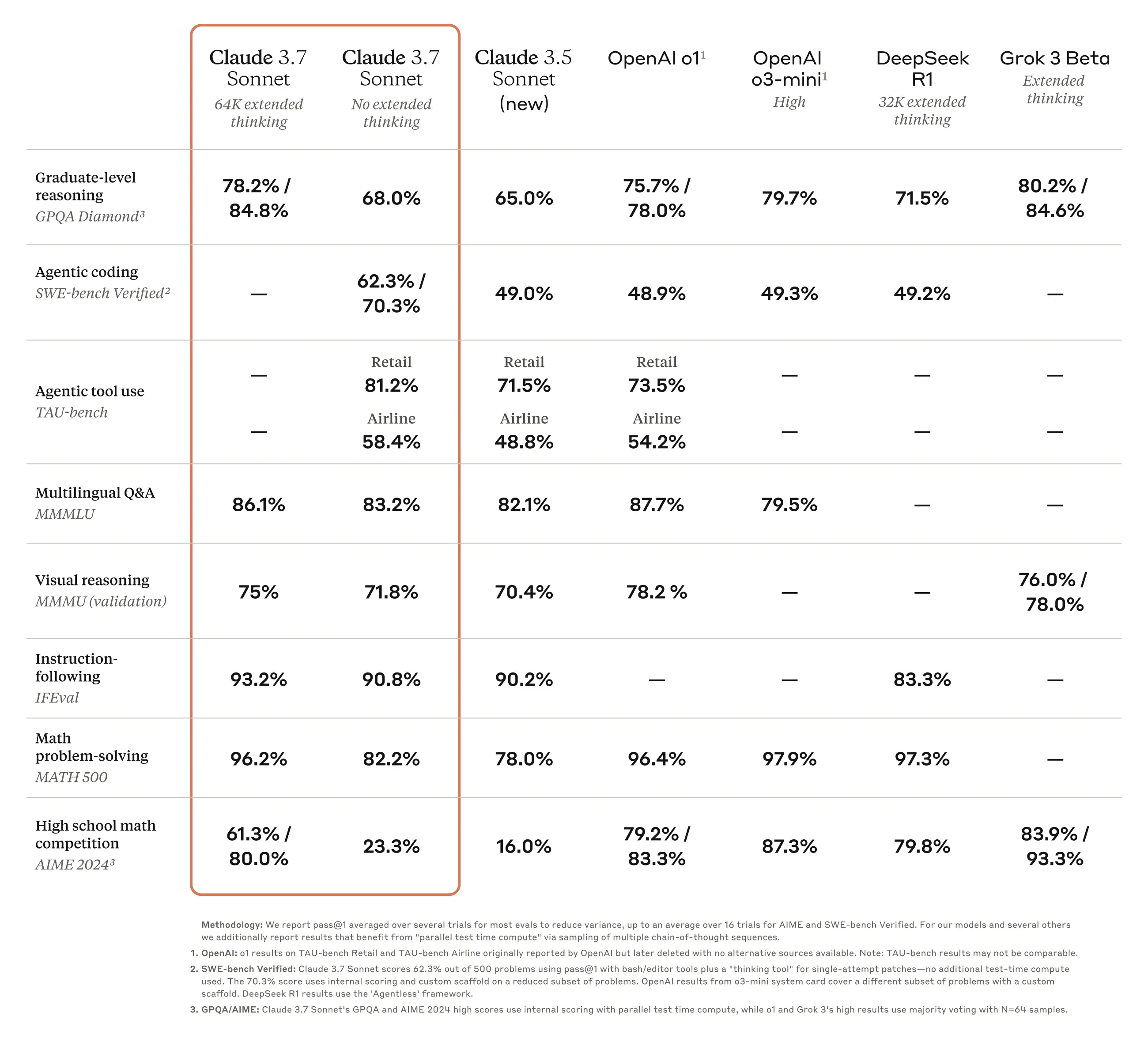
Benchmarks and performance
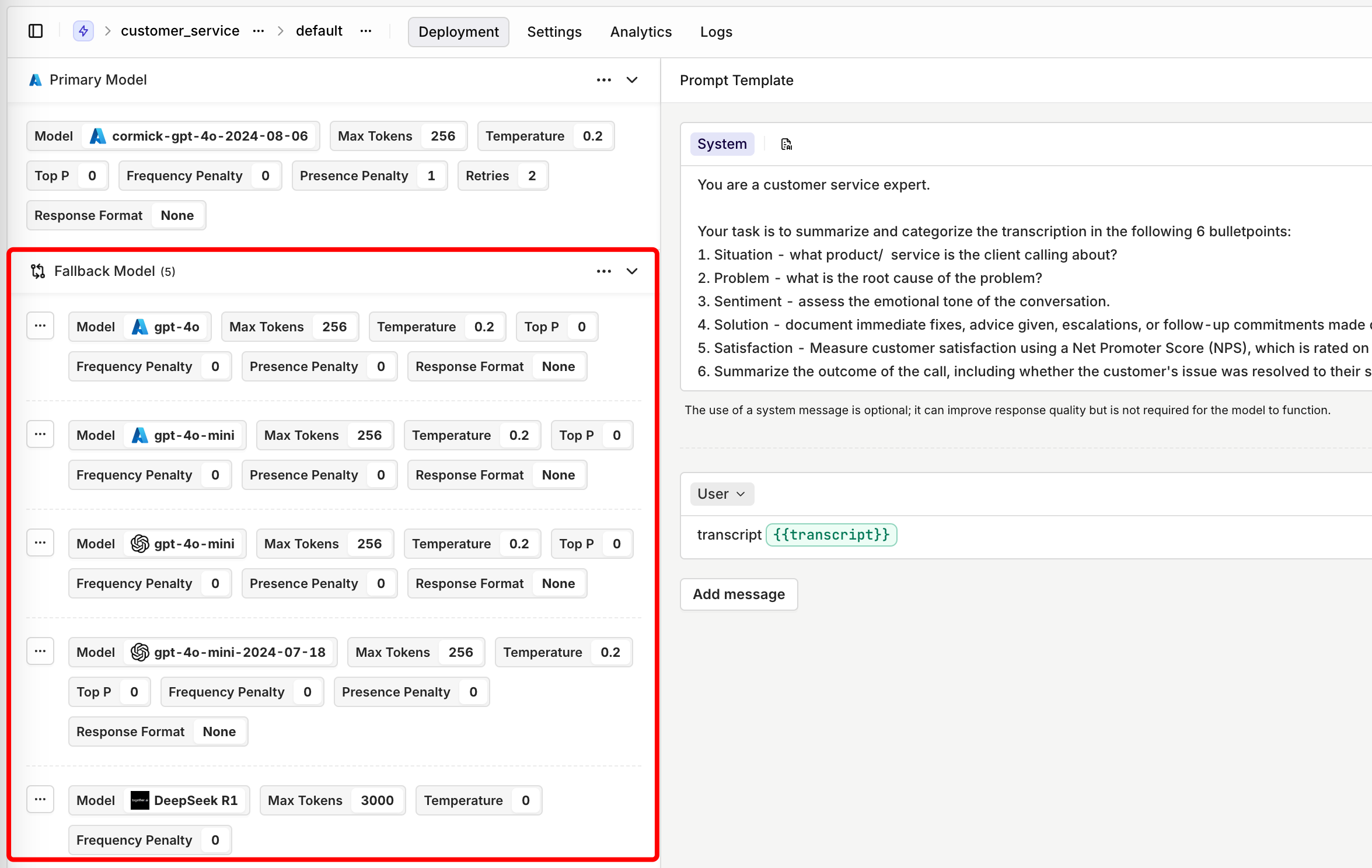
Increased fallbacks
We’ve enhanced our fallback and retry system to provide even greater reliability and flexibility in production use cases. Previously, Orq.ai allowed users to define a single fallback model if the primary model failed to generate a satisfactory output. Now, we’ve increased the number of fallback models to five, giving users even more control over model orchestration without additional coding.What’s New?
- Up to Five Fallback Models – Previously limited to one fallback model, users can now configure up to five fallback models for increased reliability.
- Flexible Fallback Configuration – The ability to define multiple fallback models allows for more advanced use cases, such as distributing API requests across different endpoints. For example:
- Azure provides different regional deployments for models like GPT-4o. If a user is making a large number of API calls through the Sweden Central region, they can configure their first fallback to West Europe, and subsequent fallbacks to other locations if rate limits are hit.
- If a primary model encounters rate limits, Orq can seamlessly transition requests to alternative endpoints, ensuring uninterrupted performance.
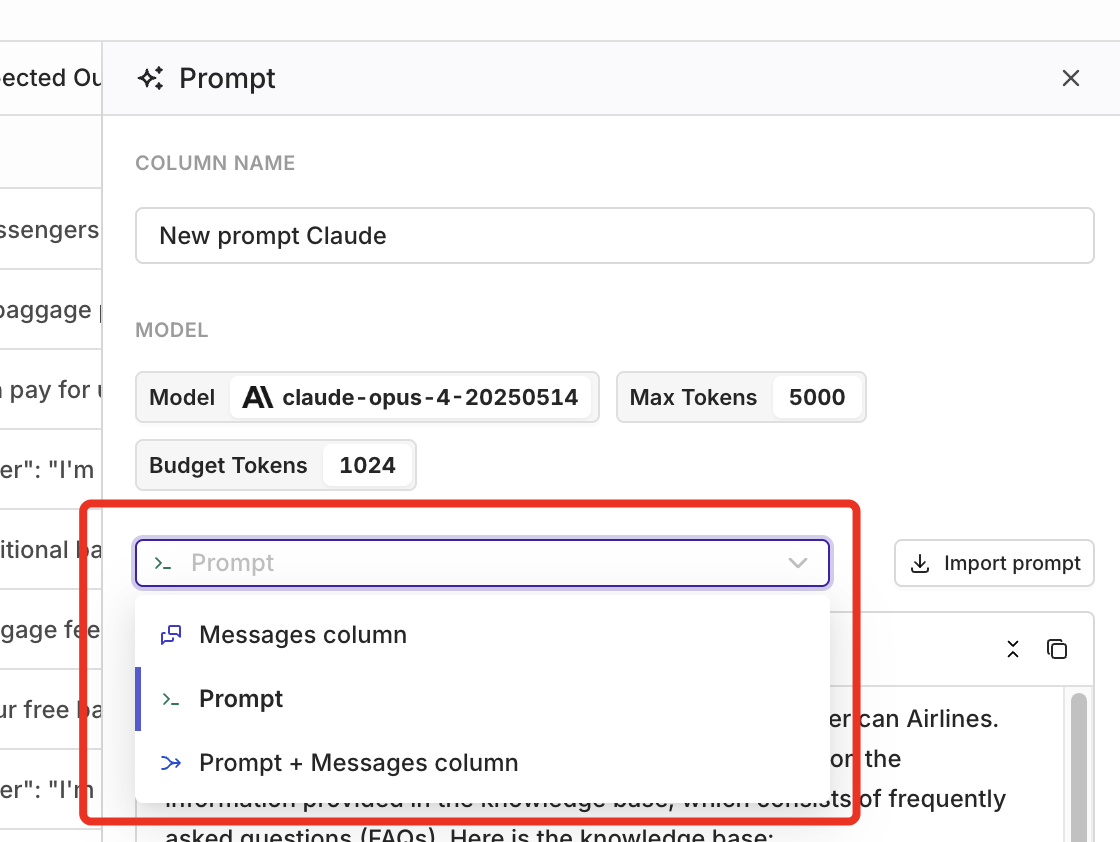
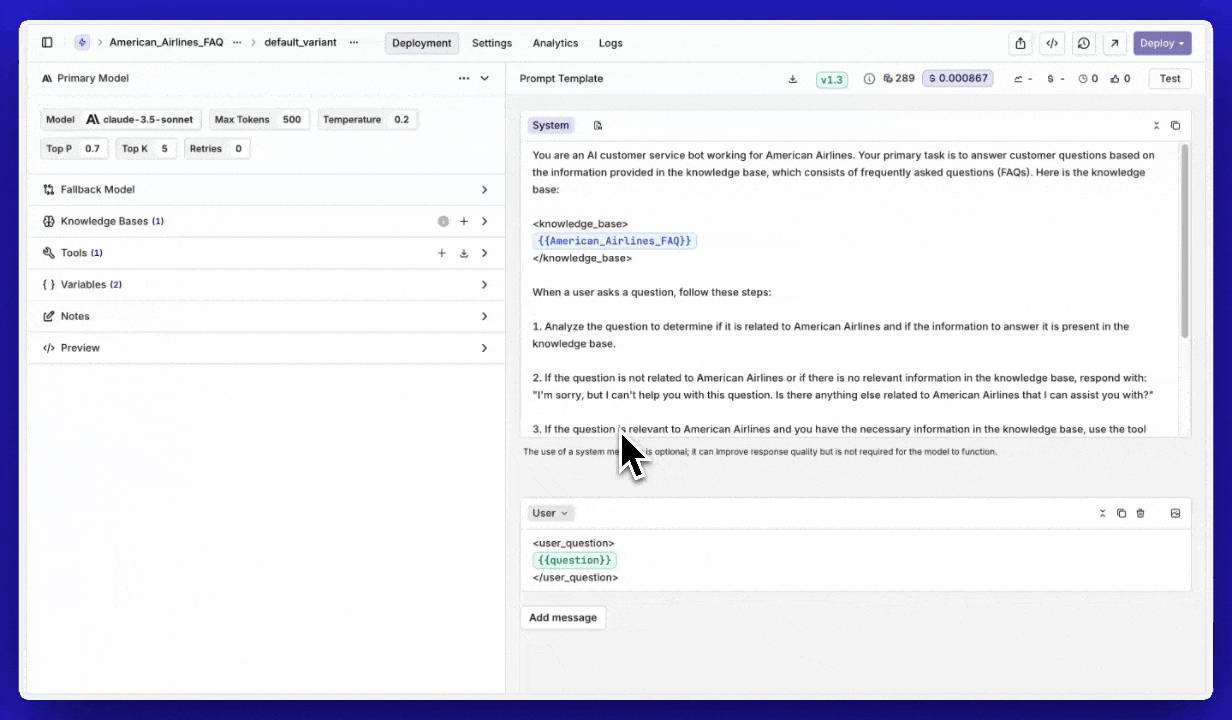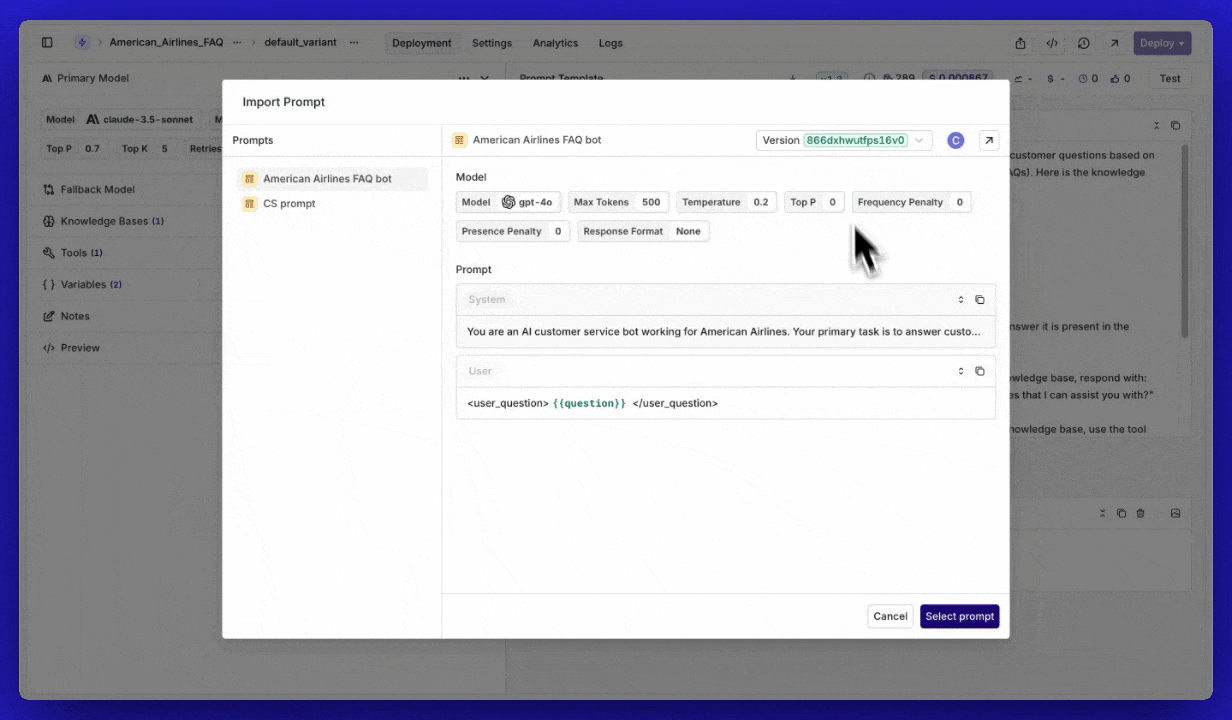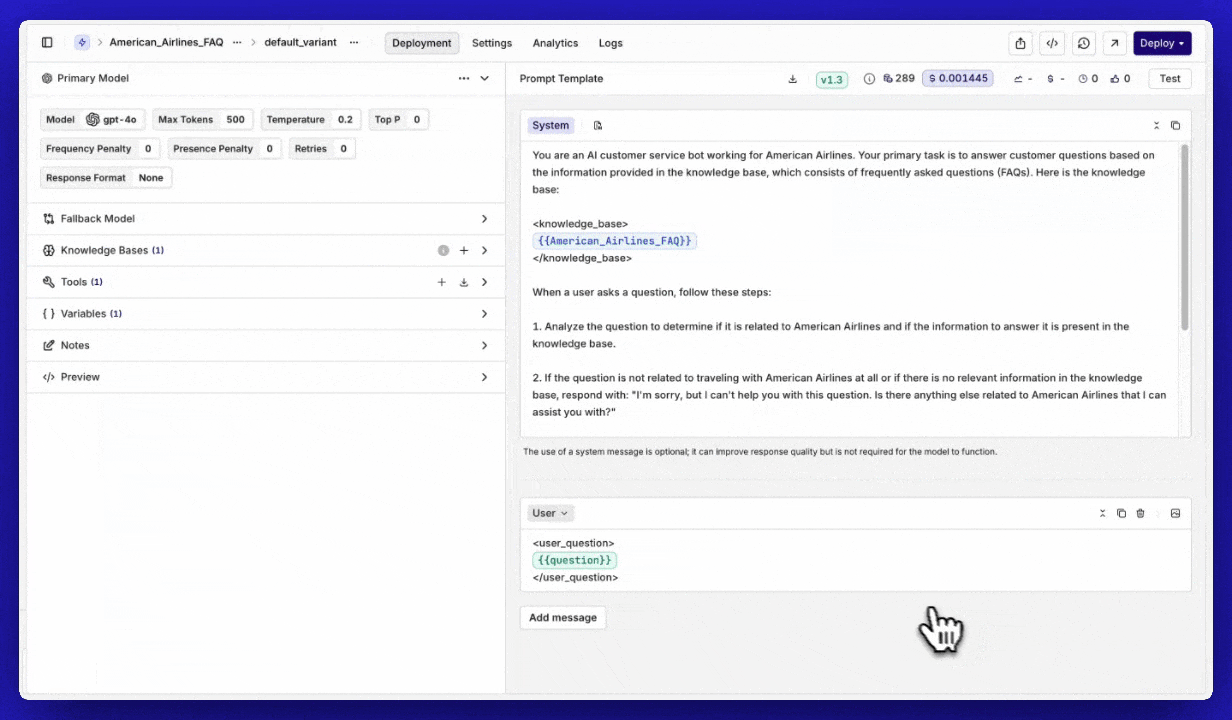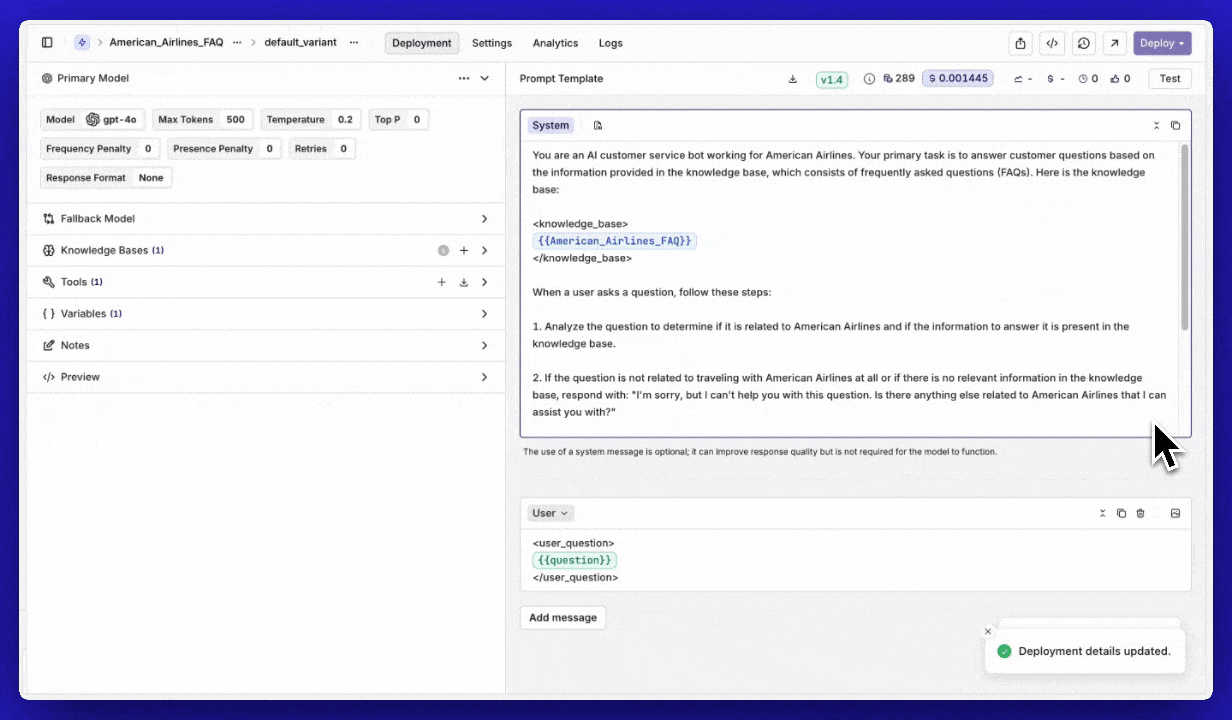
Importing prompts
We’ve introduced a new feature that makes it easier than ever to reuse your prompts within Orq.ai. With the import functionality, you can seamlessly integrate your already created, version-controlled prompts into your Playgrounds, Experiments, and Deployments.What’s New?
- Seamless Importing – Users can now import their saved prompts directly into their workspace.
- Version Control – Select the specific version of a prompt to use.
- Model Configuration – You can import your prompt including the optional model config.
Datasets v2
We’ve made a significant update to how datasets work in Orq.ai with the release of Datasets v2. This update merges variable collections into datasets, streamlining the structure and eliminating confusion between the two concepts.What’s Changed?
Previously, variable collections only contained input variables, while Datasets v1 stored message arrays and optional references. With Datasets v2, we now combine everything into a single entity. This provides a single source of truth, making it clearer what constitutes a dataset and simplifying how datasets are used.Why This Change?
- Eliminates confusion between datasets and variable collections.
- Creates a unified structure for better dataset management.
- Ensures consistency for experiments and historical logging.
Why use Datasets v2?
- Upload a dataset to evaluate your use case in an Experiment
- Save human-curated logs into curated datasets, which you can use to fine-tune your model.
- Save bad-rated logs, crucial for prompt engineers looking to refine prompts and improve output quality.

Experiments v2 - Evaluate your LLM Config
We’re excited to introduce Experiments V2, a major upgrade to our Experiments module that makes testing, evaluating, and benchmarking models and prompts more intuitive and flexible than ever before.Why Experiments Matter
The Experiments module allows users to analyze model performance systematically without manually reviewing logs one by one. It leverages evaluators—such as JSON schema validators, LLM-as-a-judge, and functions like cosine similarity —to automate the scoring process and assess output quality. This ensures users can confidently measure effectiveness and make data-driven improvements.Additionally, Experiments enable benchmarking through:- A/B testing – Compare different prompts or model configurations to determine what works best.
- Regression testing – Detect unintended changes in outputs after modifying prompts or configurations.
- Backtesting – Assess how new setups would have performed on historical data.
What’s New in Experiments V2?
We listened to your feedback and made significant improvements:- Compare Prompts Side by Side – Users can now directly compare multiple prompts within an experiment, making it easier to test variations and find the most effective approach.
- Intuitive and Flexible UI – The new interface is streamlined for ease of use, making configuration and analysis smoother than ever.
- Merged Data Sets and Variable Collections – Previously separate, these have now been combined to simplify workflows. We appreciate all the feedback on this and have made it clearer: when setting up an experiment, users now upload a data set containing input variables, messages (prompts), and expected outputs (if evaluators require a reference).
DeepSeek Models Now Available: 67B Chat, R1, and V3
We are excited to announce the integration of DeepSeek’s latest AI models—67B Chat, R1, and V3—into our platform.What model should I use?
- Choose 67B Chat for fast everyday conversations
- Pick R1 when you need deeper thinking and logic for complex tasks
-
Use V3 as a starting point to create your own specialized AI model
OpenAI’s Latest Small Reasoning Model – o3-mini
Start using OpenAI’s newest and most advanced ‘small’ reasoning model: o3-mini.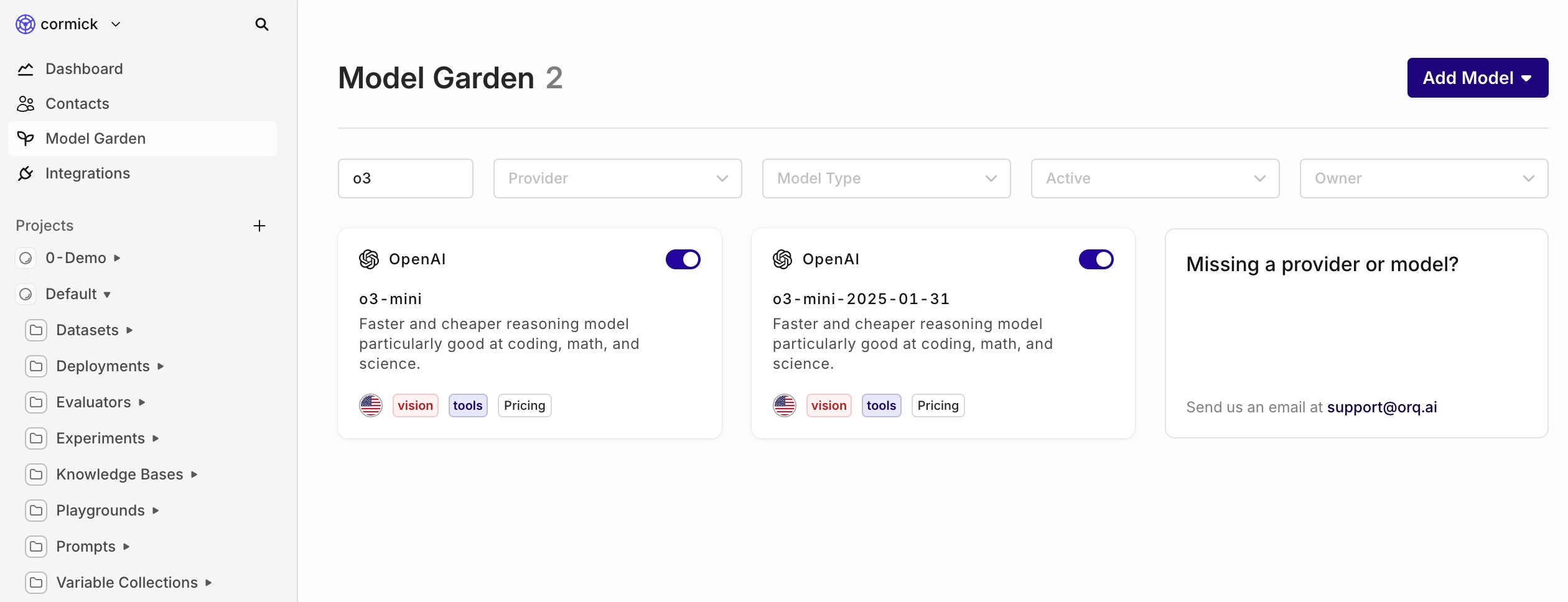
Llama 3.3 70b & Llama Guard 3 are now available through Together AI
Experience the power of the latest Llama 3.3 70b and Llama Guard 3 models on Orq, integrated via Together AI.Together AI
With the deprecation of Anyscale, we’ve been looking for a good alternative, and that’s where Together AI comes in. Together AI allows you to start using the latest Llama models with more open source models to come.Llama Guard 8b
In addition to our latest big release featuring Evaluators & Guardrails, we also added the Llama Guard model to make your AI feature even more secure.Llama Guard 3 is built to protect AI systems from common prompt hijacking attacks and misuse of LLMs.- How it works: It evaluates inputs and outputs for safety, returning a simple
safeorunsafeverdict. - Key feature: When flagged as unsafe, it identifies the violated content categories, offering clear insights.
- Why use it: Ideal for organizations exposing AI features to external users, it prevents misuse and ensures secure, compliant interactions.
Llama 3.3 70b
For users building with Llama 3.1, you can now switch to the improved Llama 3.3 70b. You can use the same prompt as with Llama 3.1 since the prompt format remains the same. Also, the 3.3 70b model is similar in performance to the 3.1 405b model, meaning you can save cost and time by switching to the newer model.New Layout with Project Structure
We’re introducing a new project structure UI to help you organize and manage your resources more effectively. With projects, you can group your work by use case, environment, or any logical structure that suits your needs.What are the benefits of the new Project Structure UI?
- Easier grouping of resources that you’re working on as a team
- Less clutter when working on multiple use cases
- Better incorporation of teams and roles within a project
Where are my old resources?
Your old resources are automatically grouped per entity of your project. For example: all your deployments within the same project are moved to the deployments folder of that project.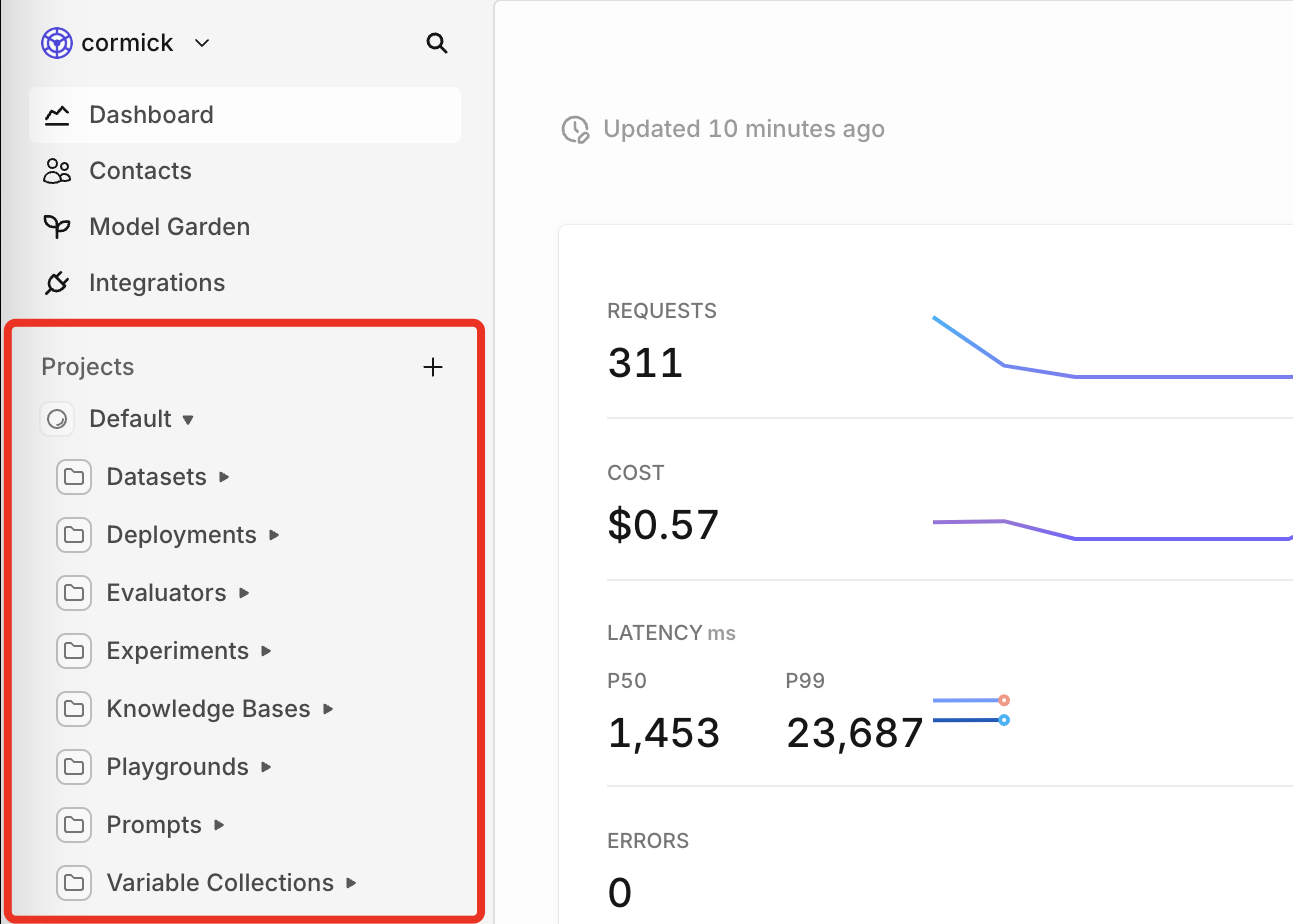
Example structure
In the example image below, you can see that you’ll have the ability to group multiple entities within the same folder. This allows you to have a production folder of a specific use case, and keep your other projects separate.Can I move my entities to a different project or directory?
Unfortunately not yet. We’re working on this feature, but until then, make sure you are working in the right place.Search your entities
To find the right entity you want to work on, we added a global search function.You can filter on project and creator, as seen in the gif below.📘 To read more about our new project structure, please visit our documentation.
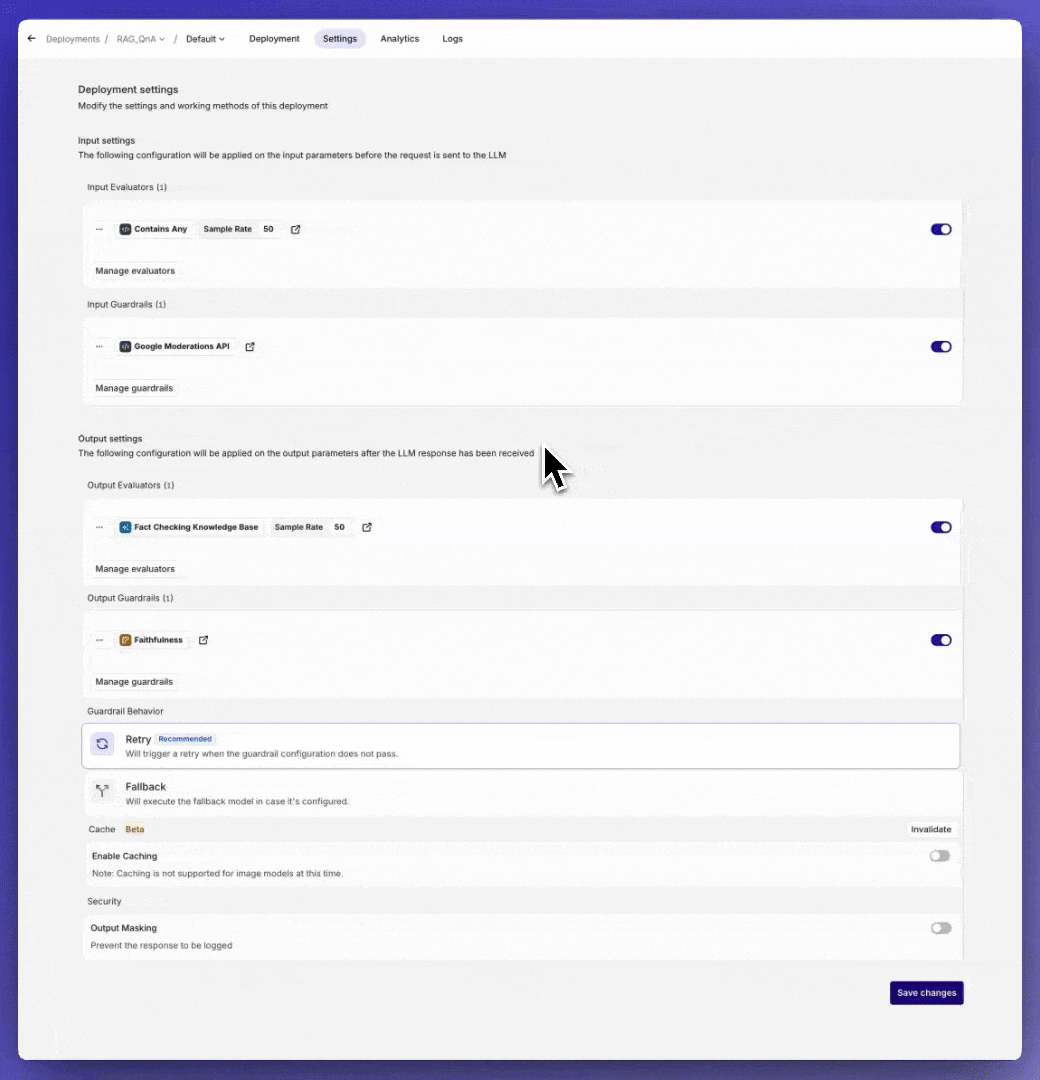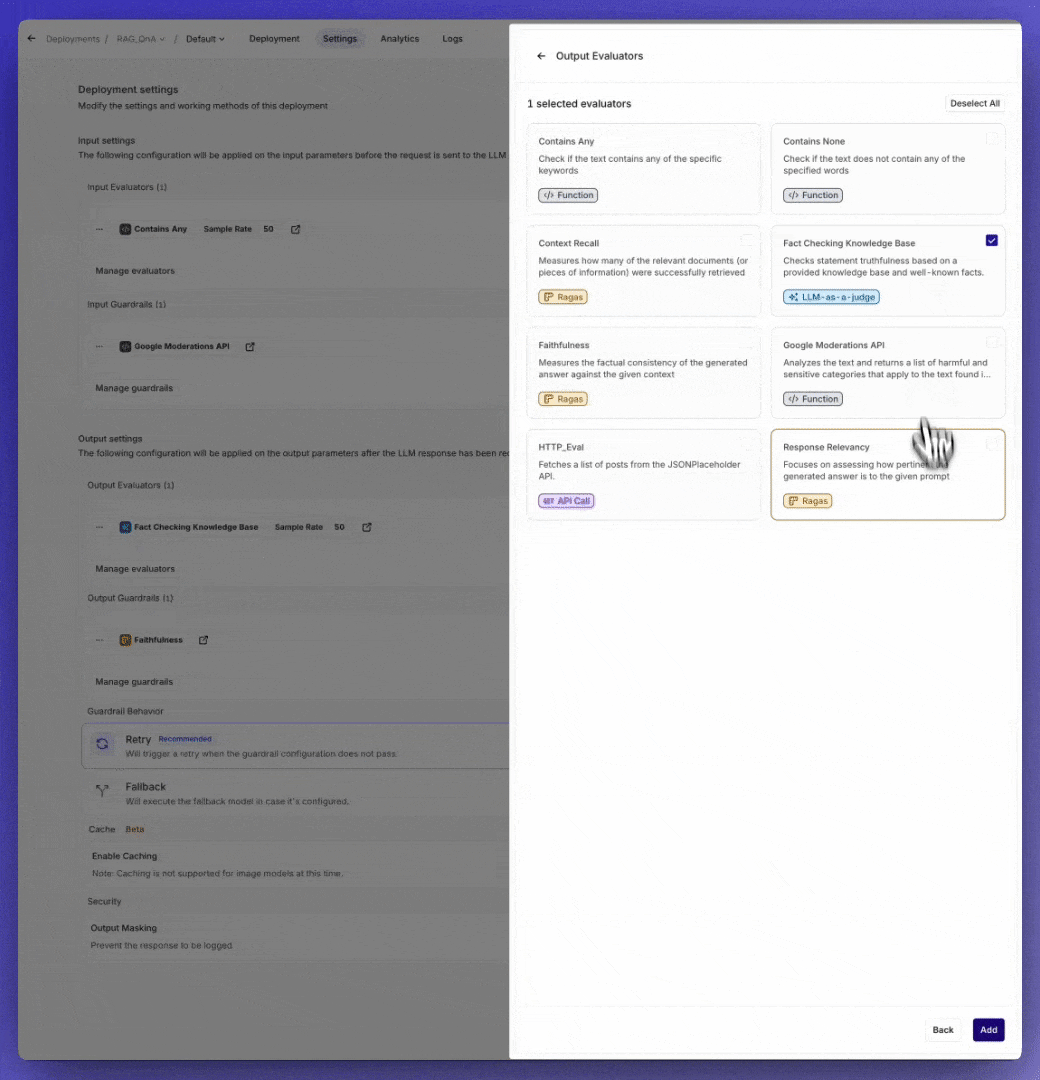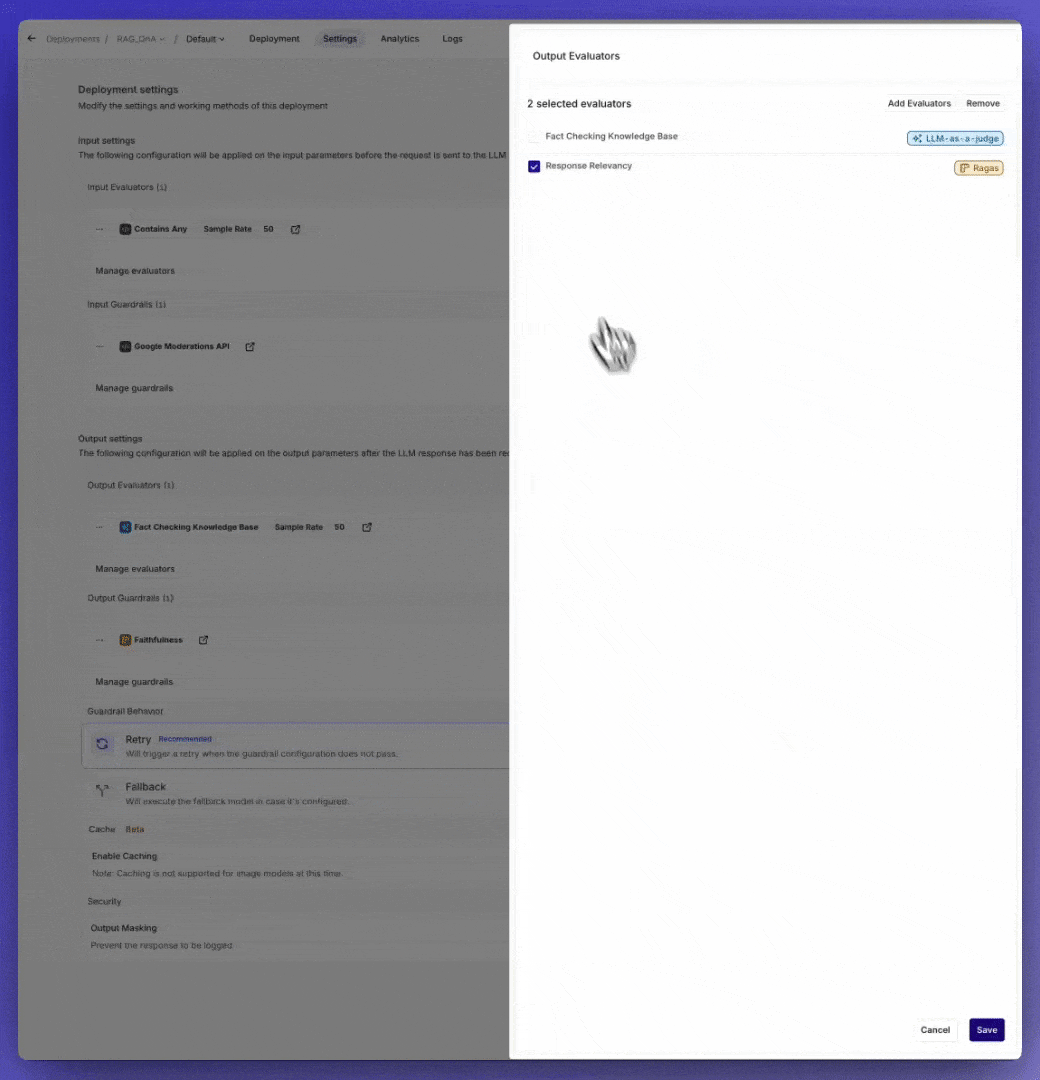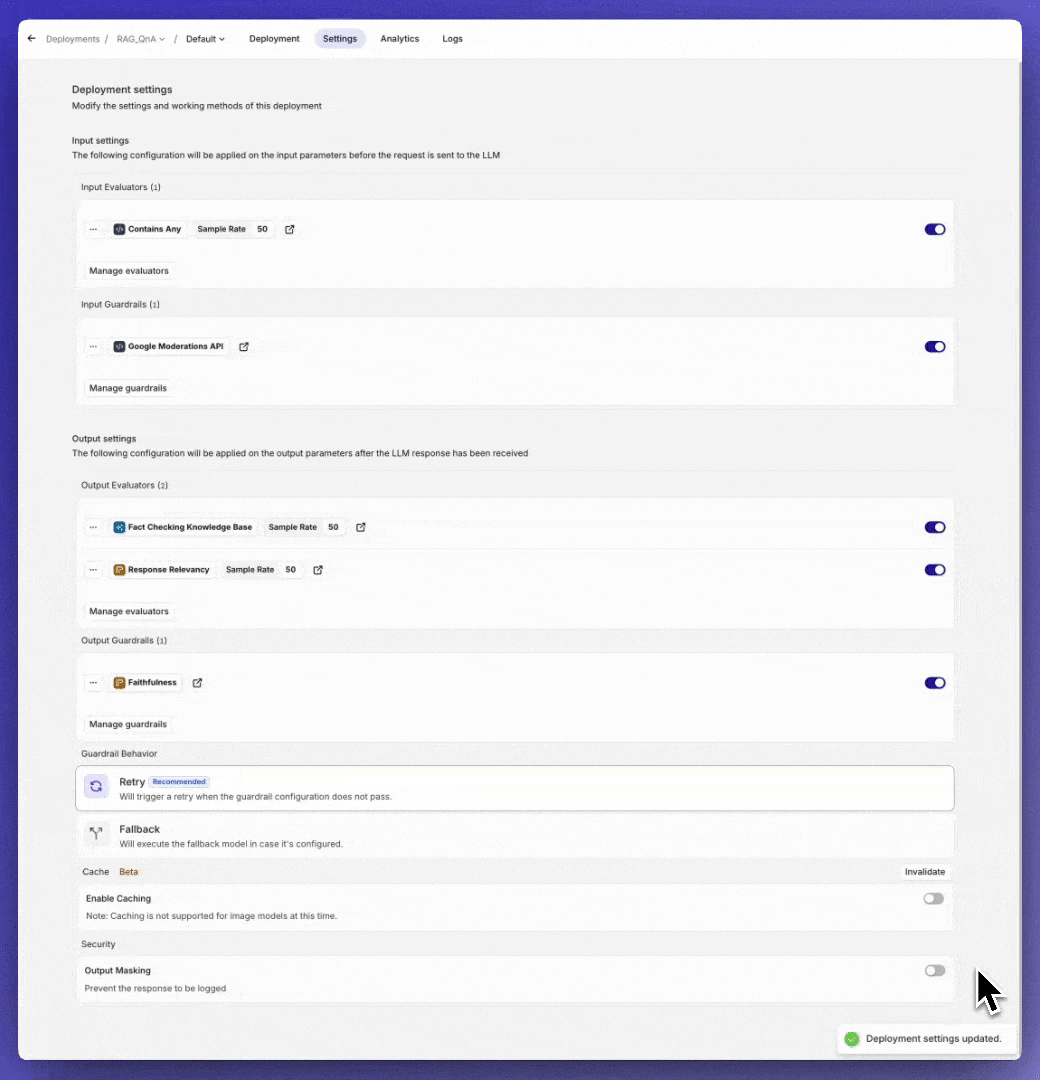
Online Guardrails in Live Deployments
You can now configure Guardrails after you have added them to your Library directly in Deployments > Settings for both input and output, giving you full control over Deployment responses- Guardrails: Block unacceptable inputs or outputs based on predefined criteria. If a guardrail is triggered, it can either retry the request or activate a fallback model, if configured.
What Are Guardrails?
Guardrails enforce boundaries by setting thresholds to block inputs or outputs that fail to meet predefined criteria. When triggered, guardrails can stop processing or activate fallback mechanisms like retries or alternative models.- Threshold Configuration: Set customizable thresholds based on your specific use case to block inputs or outputs that fail to meet predefined criteria.
- Input and Output Guardrails: Apply rules to both incoming data and generated outputs, ensuring comprehensive quality control at every stage.
- Synchronous Operation: Guardrails run synchronously and do not introduce additional latency to your workflows.
- Fallback Mechanisms: When triggered, guardrails can stop processing or activate fallback options such as retries or alternative models to maintain continuity.
Why Are Evals and Guardrails Important?
With this release, you can gain full control over your AI applications, enhancing the reliability, safety, and quality of AI-generated outputs with evaluators and guardrails. While LLMs are incredibly powerful, they are also prone to errors such as incorrect information, biased content, or misaligned outputs—a risk famously illustrated by a chatbot that mistakenly agreed to sell a car for $1.The value of evaluators is twofold:- First, they address the inherent risks of LLMs by monitoring and ensuring output quality and safety.
- Second, they help teams overcome one of AI development’s biggest challenges: understanding how updates impact performance. Without clear insights, the development loop can break, turning iteration into guesswork rather than a structured engineering process. Evaluators help you understand whether an update is an improvement or a regression and quickly drill down into good / bad examples.
What Are Evaluators?
Evaluators assess and score outputs either against a reference or directly as they are generated by the model. They play a critical role in monitoring and improving AI quality, enabling you to evaluate performance continuously without disrupting operations. Evaluators come in several forms:Classic Evaluators: These rely on references and established metrics, such as cosine similarity or BLEU scores, to compare outputs to an expected result. They are ideal for structured, deterministic tasks like translation or summarization.- Example: Use cosine similarity to measure how closely an LLM-generated summary matches the reference text.
- Example: Evaluate whether a chatbot’s response aligns with the intended tone and emotional context without comparing it to a specific reference.
Designed to evaluate retrieval-augmented generation (RAG) workflows, these evaluators measure context relevance, faithfulness, recall, and robustness. They ensure responses derived from external knowledge bases are accurate and focused.
- Example: Verify that a chatbot retrieving insurance policy details provides relevant and accurate information while excluding unrelated content.
Rule-based tools for assessing measurable aspects of text, such as formatting, length, or keyword presence. These provide binary, deterministic results for compliance and validation.
- Example: Check if a response includes “return policy” or stays within a 200-character limit for customer service use cases.
Allow external API calls to evaluate outputs using custom or third-party systems, enabling tailored checks for domain-specific requirements.
- Example: Call a compliance-check API to validate that AI-generated responses meet industry-specific guidelines.
Validate JSON outputs against predefined schemas, ensuring all required fields, correct data types, and structures are present.
- Example: Confirm a JSON file for user registration includes fields like “username,” “age,” and “email” in the correct format.
What Are Guardrails?
Guardrails, enforce strict boundaries to block unacceptable inputs or outputs entirely. These constraints ensure the system adheres to rules like regulatory compliance, ethical standards, or content safety. The motives to implement guardrails can be summarized in four categories:- Robustness and Security. Guardrails are of huge importance in the aspect of security and robustness of an LLM-based application. This includes vulnerabilities such as prompt injections, jail-breaking, data leakage, handling illegible or obfuscated content.
- Information and Evidence. Guardrails can be put in place for fact checking, detecting hallucinations, making sure the response does not contain incorrect or misrepresented information, does not consider irrelevant information, the response is supported by evidence.
- Ethics and Safety. Making sure the response does not lead to harmful consequences either directly or indirectly. A response should not exhibit problematic social biases or share protected or sensitive information, take into account copyright and plagiarism law, use 3rd party content by appropriately citing it, etc.
- Tool-specific functionalities. Making sure the responses are on-topic, of proper extensiveness, written in the suitable tone, use specified terminology, etc.
HTTP and JSON Evaluators and Guardrails
You can now add HTTP and JSON Evaluators and Guardrails under the Evaluator tab and add them to your Deployment or Experiment.HTTP Evaluators and Guardrails
- Purpose: Enable evaluation using external APIs to perform checks like compliance, custom logic, or business-specific validations.
- How It Works: You define the URL, headers, and payload for HTTP Requests, and the evaluator expects either a boolean or numerical response in the format:
- Use Case Example: An HTTP Evaluator can validate content against regulatory guidelines by routing a compliance check to your API, returning a boolean to accept or block the output. If you want to integrate an HTTP Eval into your set up, you can find more information in HTTP Evaluators.
- Guardrails: Configurable to accept or deny calls based on the returned value, providing dynamic control in experiments and deployments.
JSON Evaluators and Guardrails
- Purpose: Validate input or output payloads during Experiments or Deployments using a predefined JSON Schema.
- How It Works: Enter a JSON Schema specifying required fields and their expected types. For example:
- Use Case Example: A JSON Evaluator can ensure that generated content includes mandatory fields like “title” and “length,” blocking invalid payloads. For a more extensive explanation on how to set this up in your Deployment, you can go here.
- Guardrails: Toggle guardrails to block outputs that don’t adhere to the schema, ensuring compliance during Deployments or Experiments.
Master Your RAG with RAGAS Evals
The Ragas Evaluators are now available, providing specialized tools to evaluate retrieval-augmented generation (RAG) workflows. These evaluators make it easy to set up quality checks when integrating a Knowledge Base into a RAG system and can be used in Experiments and Deployment to ensure responses are accurate, relevant, and safe.Key Features- Out-of-the-Box Functionality: RAGAS Evaluators are ready to use and cannot be reconfigured, offering a consistent evaluation framework.
- Reference-Based Scoring: Some evaluators require a reference to calculate metrics like accuracy or faithfulness.
- Scoring Scale: Evaluations return a score between 0 and 1, with higher scores indicating better performance (e.g., higher relevance or faithfulness).
-
Context Precision: Assesses how well retrieved chunks align with the user’s query.
- Example: Ensures chunks about “home insurance” are prioritized when the query asks about coverage, filtering out irrelevant topics like auto insurance.
-
Response Relevancy: Evaluates how directly the generated answer addresses the query.
- Example: For “What are the fees for international transfers?” it ensures the answer is concise and focused on the fees without unrelated details.
-
Faithfulness: Ensures the response is factually consistent with the retrieved context.
- Example: For “What is the company’s remote work policy?” it checks if claims (e.g., “three days remote”) match the policy document.
-
Context Entity Recall: Verifies that critical entities from the reference answer are included in the retrieved content.
- Example: For “Tell me about the Taj Mahal,” ensures entities like “Shah Jahan” and “Agra” are retrieved.
-
Context Recall: Measures if all necessary details from a reference are retrieved.
- Example: For “What are the main benefits of product X?” it ensures all benefits like “cost savings” and “improved efficiency” are included.
-
Noise Sensitivity: Checks if the system ignores irrelevant information in the retrieved context.
- Example: For “What is LIC known for?” it ensures the response focuses on LIC’s attributes, filtering out unrelated economic data.
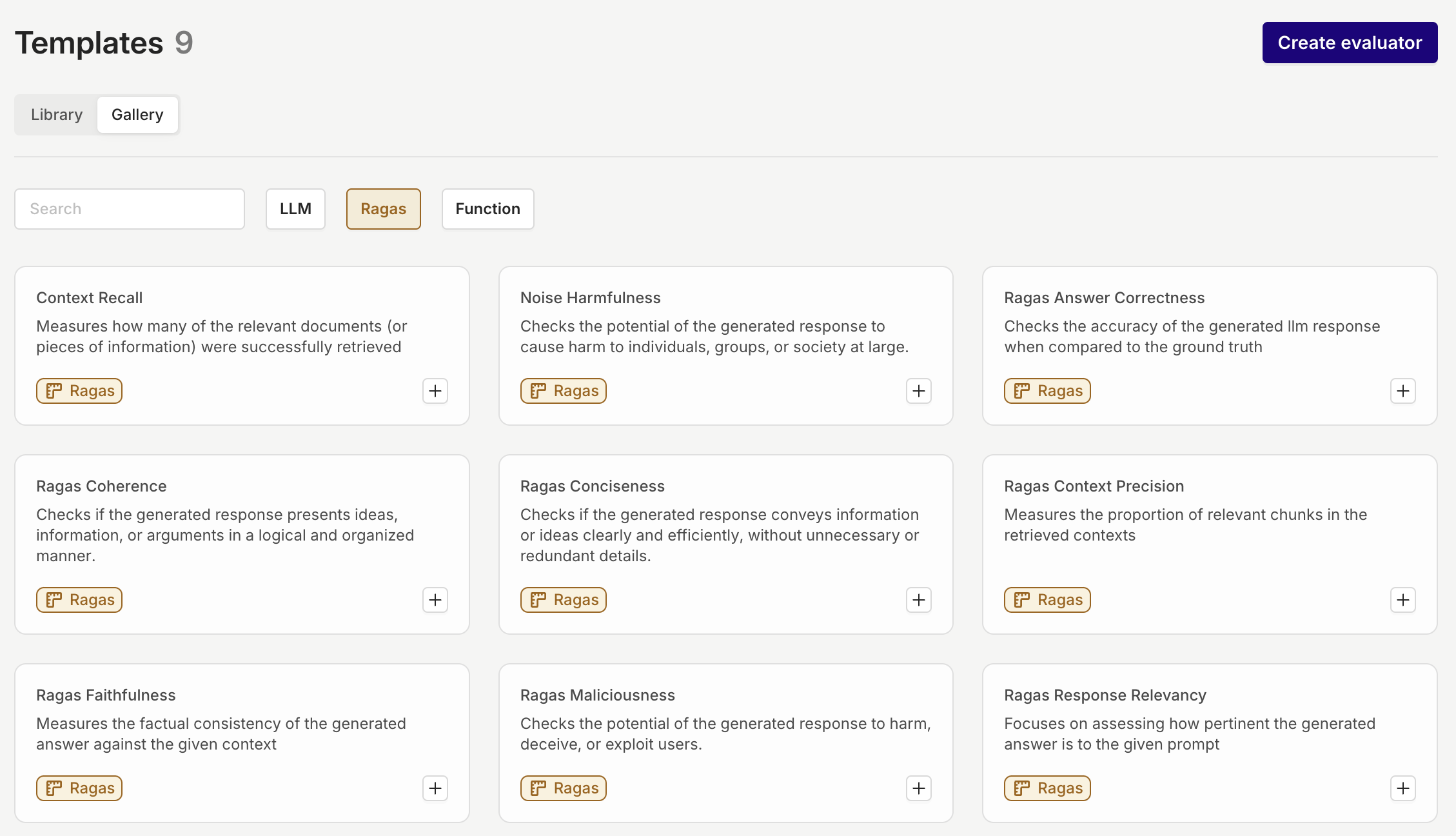
Evaluator Library: 50+ Ready-to-Use and Tailorable Evaluators
Introducing the new Evaluator Library:Key Features:1. Gallery of Preconfigured Evaluators:- The library includes 50+ preconfigured evaluation templates tailored for a wide range of use cases, from quality checks to compliance and contextual alignment.
- These templates are organized into categories such as LLM Evaluator Ragas Evaluator and Function Evaluator checks to help you find the right tool for your needs quickly.
- Each preconfigured evaluator can be customized and configured to fit specific project requirements.
Once tailored, evaluators can be added to your personal Library for reuse in Experiment and Deployment.
-
Evaluators are designed to work effortlessly in both experiments and deployments, enabling consistent and reliable quality control across development stages.
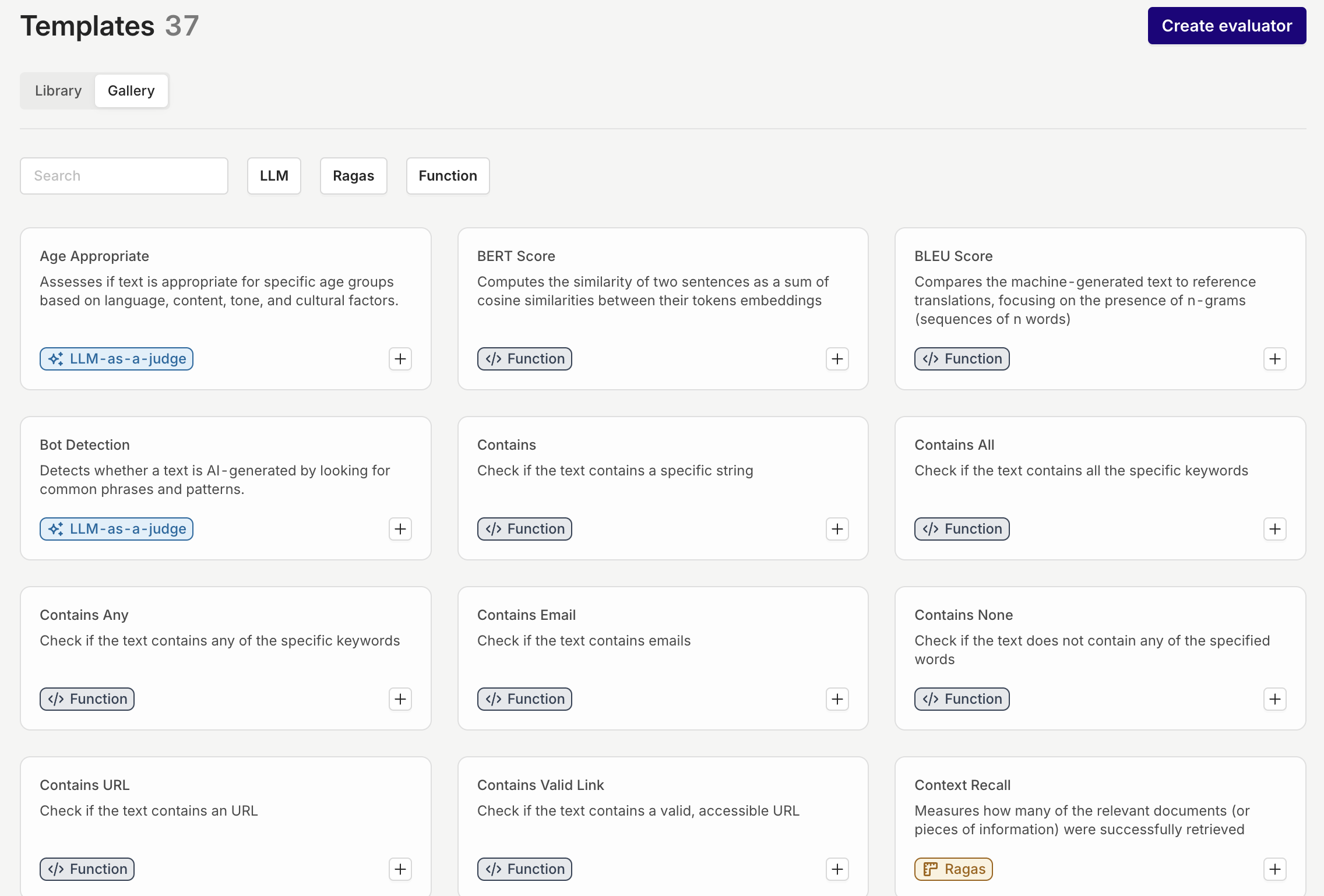
Improved LLMs as a Judge
LLM-as-a-Judge Enhancements:We’ve significantly improved our existing LLM Evaluator feature to provide more robust evaluation capabilities and enforce type-safe outputs.1. Type-Safe Output:
- When you configure the output type as a number, boolean, or other types, the LLM ensures the result adheres strictly to the defined format.
-
Additionally, each output includes a clear, concise explanation to support transparency and reliability in the evaluation process.
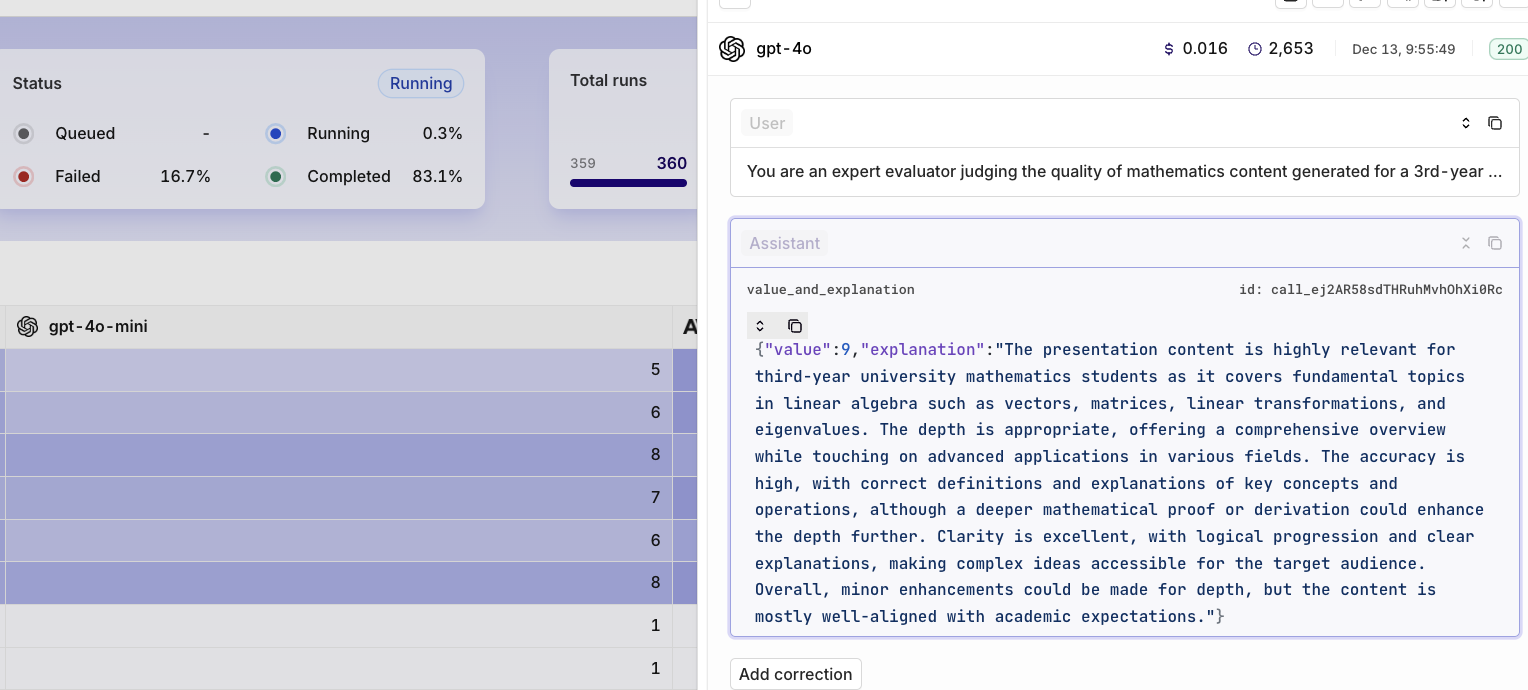
- The LLM-as-a-Judge now seamlessly integrates into live deployments, enabling asynchronous quality evaluation with a configurable sample rate. This approach provides actionable insights without disrupting workflows, ensuring consistent quality and minimizing drift.
-
The LLM-as-a-Judge also supports Guardrail Mode, actively enforcing quality standards by blocking inputs or outputs that fail to meet defined criteria.
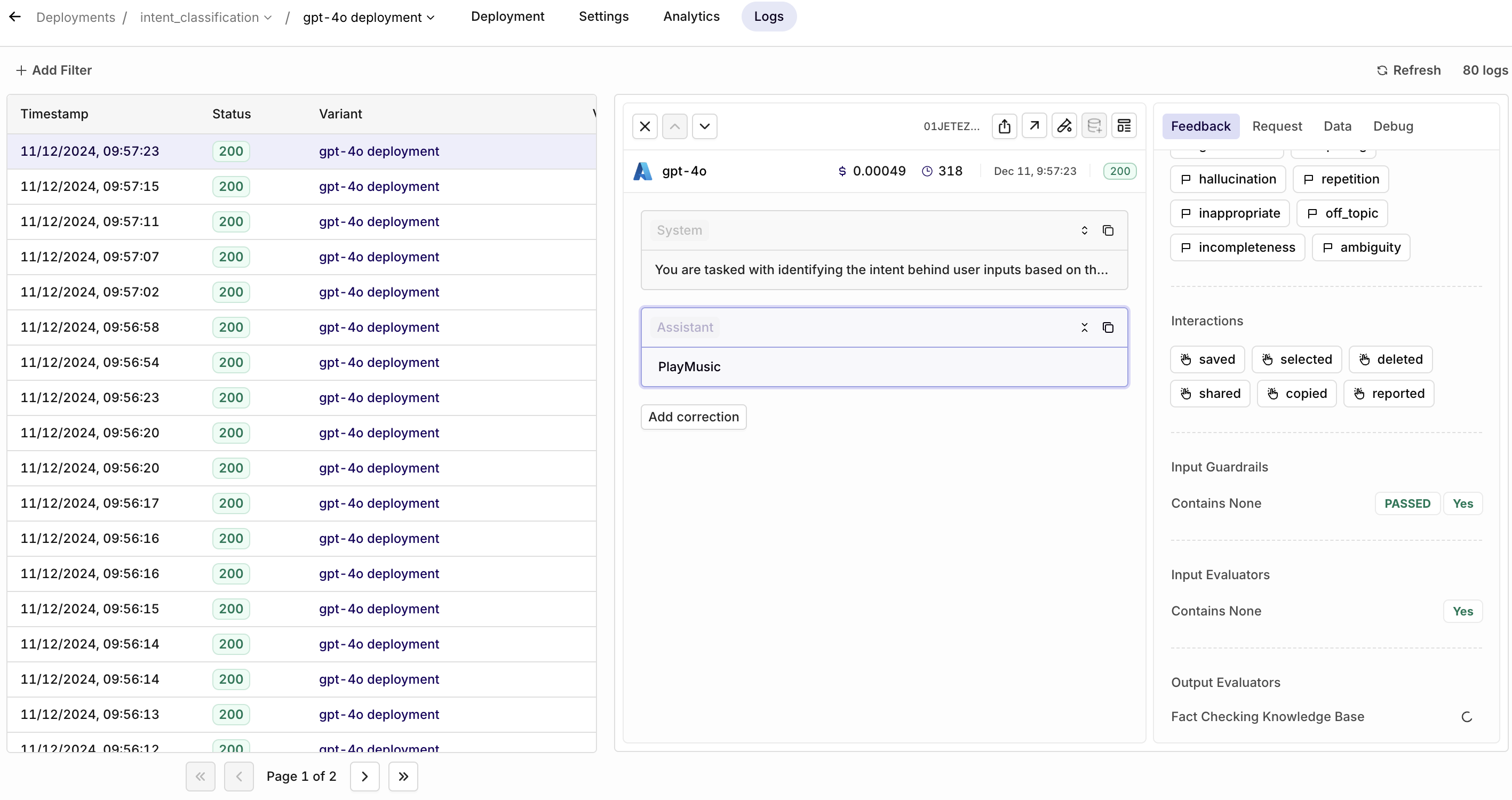
Online Evaluators in Live Deployments
iYou can now configure Evaluators after you have added them to your Library directly in Deployments > Settings for both input and output, giving you full control over Deployments.Why Are Evaluators Important?
- Quality and Safety: Evaluators mitigate LLM risks by monitoring and ensuring output quality and safety.
- Performance Insights: They provide clear feedback on updates, helping teams identify improvements or regressions and refine iterations effectively.
What Are Evaluators?
Evaluators are tools designed to assess the quality, relevance, and safety of AI inputs or outputs, ensuring reliable and effective system performance. Off the shelf, we offer several options, including LLM Evaluator, Ragas Evaluator, Function Evaluator and API Call Evaluators. Additionally, the evaluators allow for the following configuration:- **Sample Rate Option:**Run evaluations on a subset of calls (e.g., 10%) to balance coverage and efficiency.
- **Cost Management:**Reduces additional expenses associated with running evaluators, especially LLM-based ones.
- Latency Control: Minimizes added response time by limiting the number of calls evaluated.
Cache your LLM response
Cache and reuse your LLM outputs for near-instant responses, reduced costs, and consistent results.What is Caching?With this release, you can now enable caching for your LLM calls. Caching works by storing both the input and the generated output for a configurable period (TTL – Time-to-Live). When an exact request is made during this time, the cached output is returned instantly, bypassing the need for the LLM to generate a new response.Why Enable Caching?- Cost Savings
- Time Savings
- Improved Consistency
Structured Outputs on Azure
Ensure the model’s responses always stick to your JSON Schema. No more missing fields or incorrect values, making your AI applications more reliable and robust.In addition to the Open AI provided models, you can now use Structured Outputs on Azure hosted models.Using Structured Outputs is the go-to method if you want to ensure that the model is adhering to your JSON Schema.📘 Read more about Structured Outputs in Using Response Format.
Claude 3.5 Haiku and Sonnet (new)
Introducing the upgraded Claude 3.5 Sonnet and the new Claude 3.5 Haiku. The enhanced Claude 3.5 Sonnet offers comprehensive improvements, especially in coding and tool use, while maintaining the speed and pricing of the previous model. These upgrades make it an excellent choice for complex, multi-step development and planning tasks.For those prioritizing speed, Claude 3.5 Haiku combines quick response times with strong overall performance. It’s ideal for user-facing applications and specialized tasks, managing data-rich inputs like personalized recommendations and real-time decision-making with ease.Note: Claude 3.5 Haiku doesn’t support vision just yet.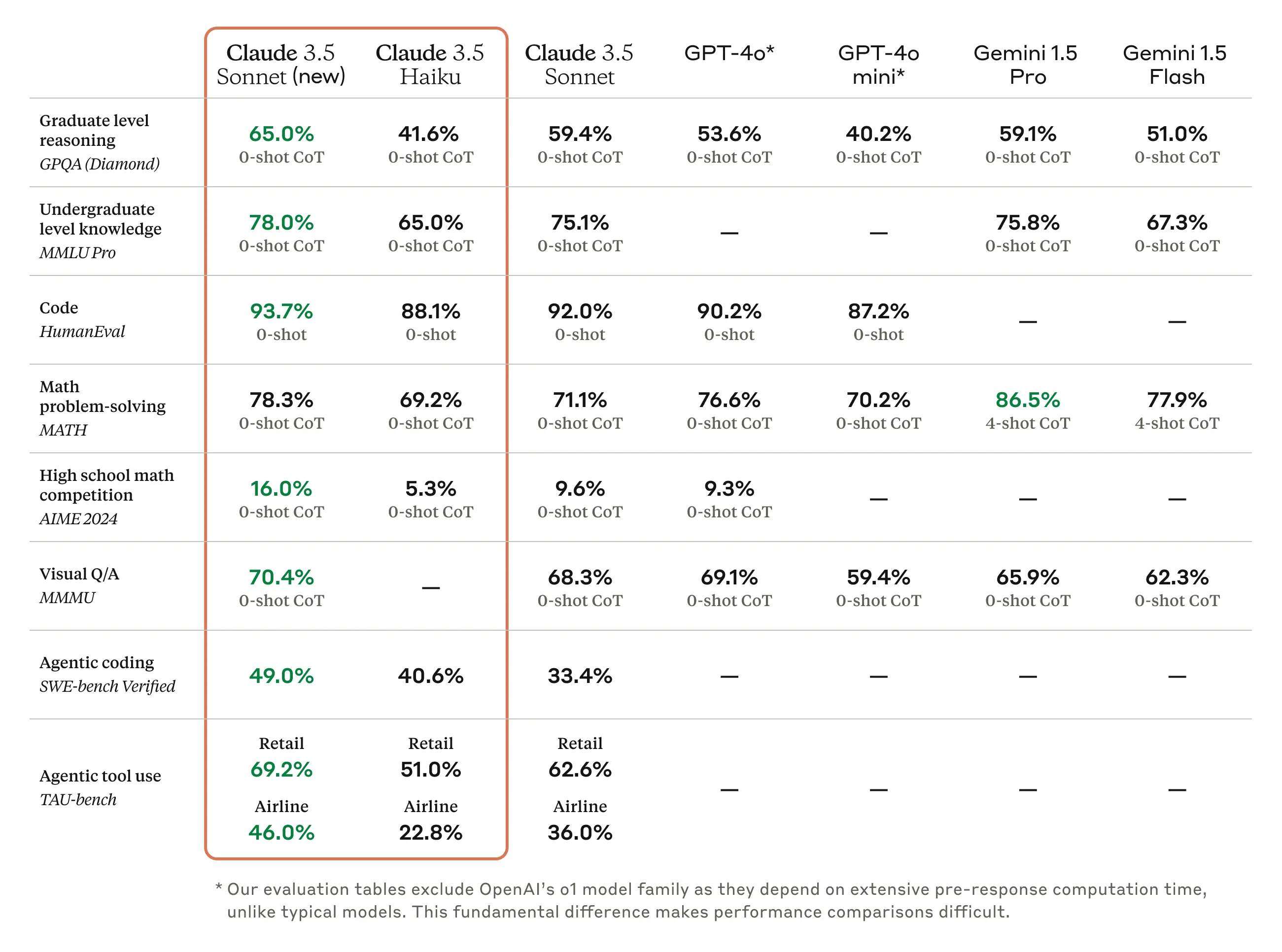
Role Based Access Control improvements
With the improvements to role-based access control (RBAC), it is much easier to assign and change workspace roles in Orq.Orq now offers three distinct workspace roles:- Admin: Complete access across all platform features, including user management, workspace settings, model configurations, and billing.
- Developer: Provides technical access to all essential features, including the ability to deploy changes within Deployments. Developers cannot manage models, billing, or users.
- Researcher: Offers access to Playgrounds, Experiments, and Deployments for research purposes. Researchers can review and annotate logs but cannot modify or deploy changes.
📘 Read more on how to set up permissions in our documentation
Attach files to a Deployment
One common request we hear is whether it’s possible to attach files to an LLM — for example, to extract data from a PDF or engage with its content. With this update, you can now do just that.📘 We support pdf, txt, docx, csv, xls - 10mb maxThe content of the files will be incorporated into the initial system or user message. We recommend adjusting your prompt as you would when using variables in a prompt. The added content will be highlighted in green. See the example below:
🚧 Be aware that we only extract the raw data, no images or objects. Also, encrypted files are not supported.
When should I attach a file and not use a Knowledge Base?
- The need for full context understanding
- Dynamic document context
- Private or sensitive data
How to use it?
To attach one or more files to a Deployment, follow these steps:- Upload your files
- Receive the
_id
- Send the file
_idin addition to your normal Orq API call
Log Filtering
The ‘Log Filters’ feature is now available, following high demand from our users. Monitoring logs is essential for tracking performance and identifying areas for improvement, and with this new feature, it’s now easier to find the exact data you need to make informed decisions.With Log Filters, you can quickly sort through large sets of logs and focus on the most relevant information for your workflow. Here are some key use cases:- Optimize Prompts: Filter logs with low ratings to pinpoint where your prompts need improvement and refine them for better outcomes.
- Troubleshoot Issues: Filter logs with error statuses to identify what went wrong and address any issues in your setup.
-
Monitor Fallbacks: Filter logs that triggered a fallback model to see where the primary model didn’t perform as expected.
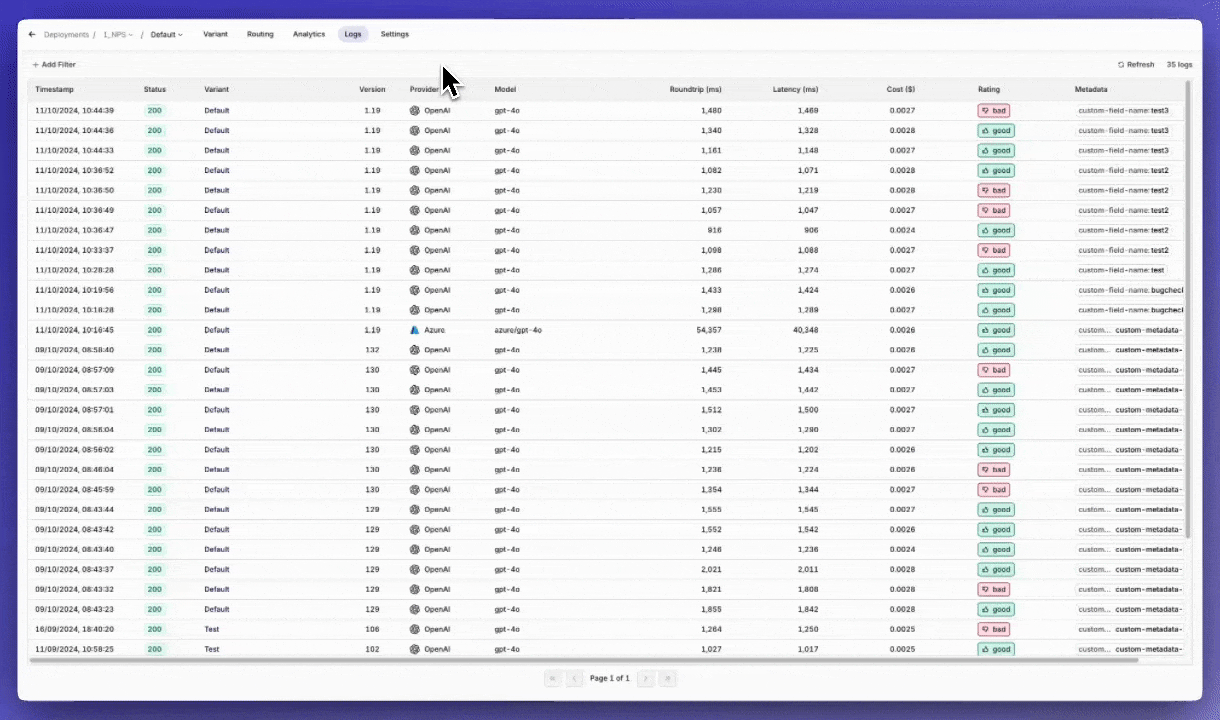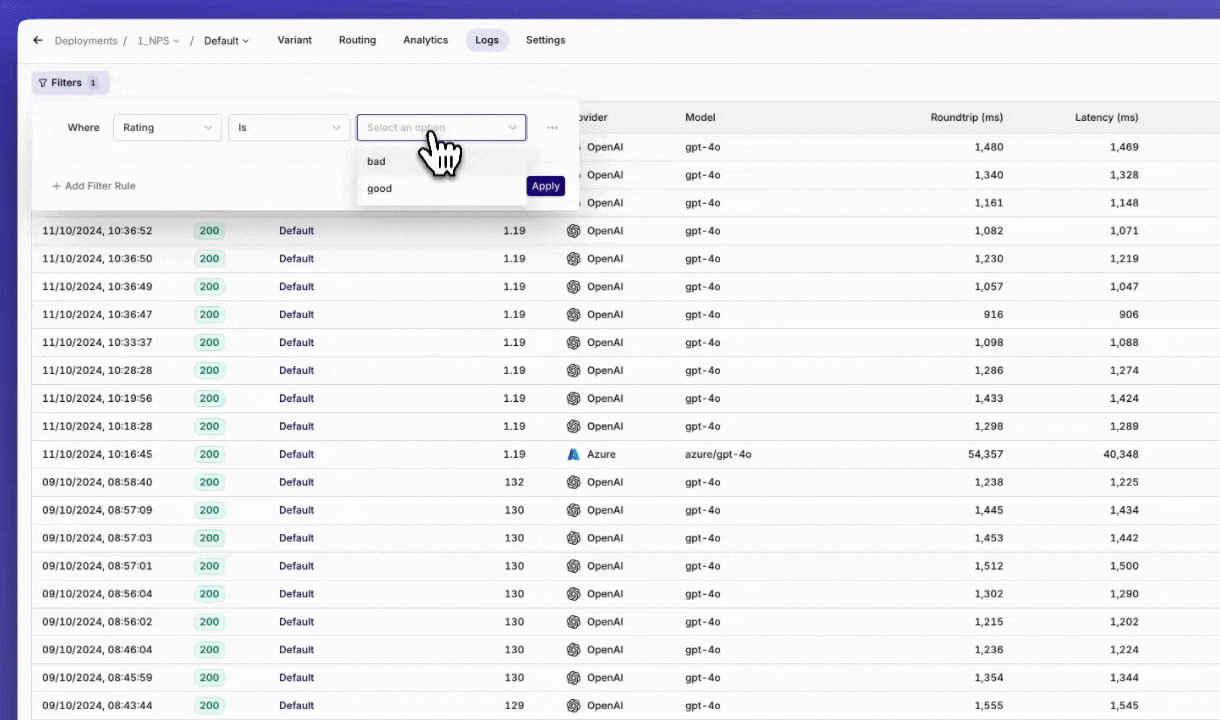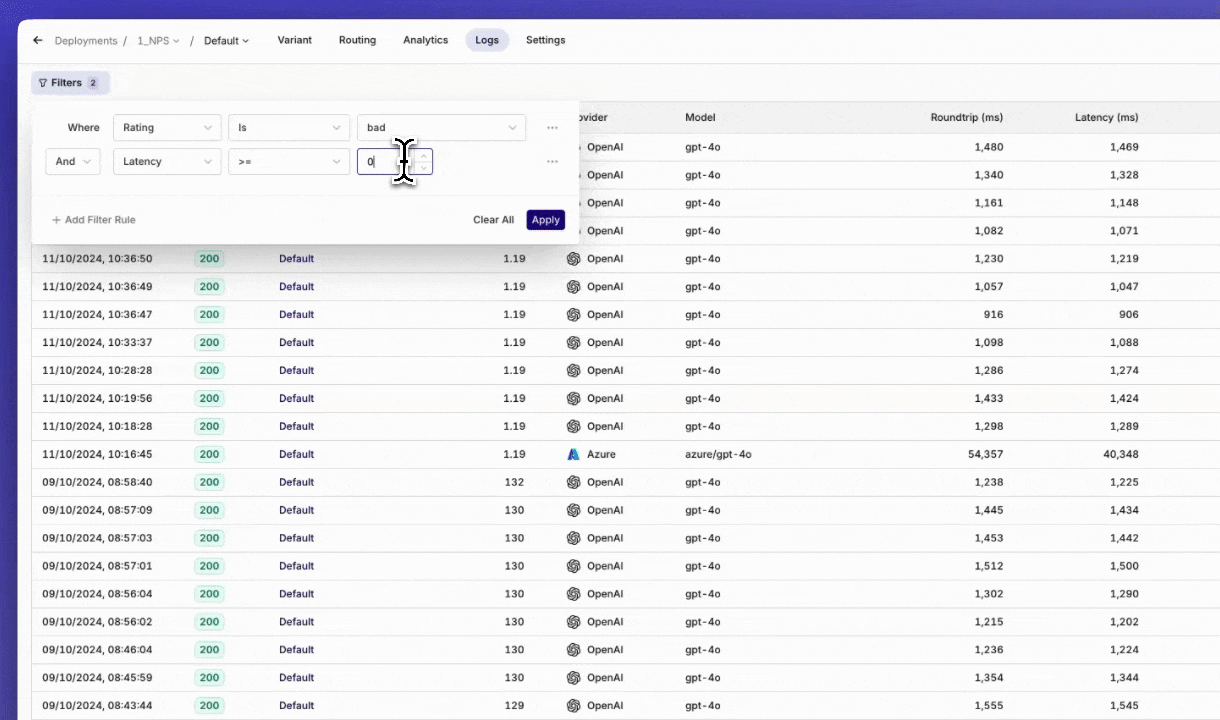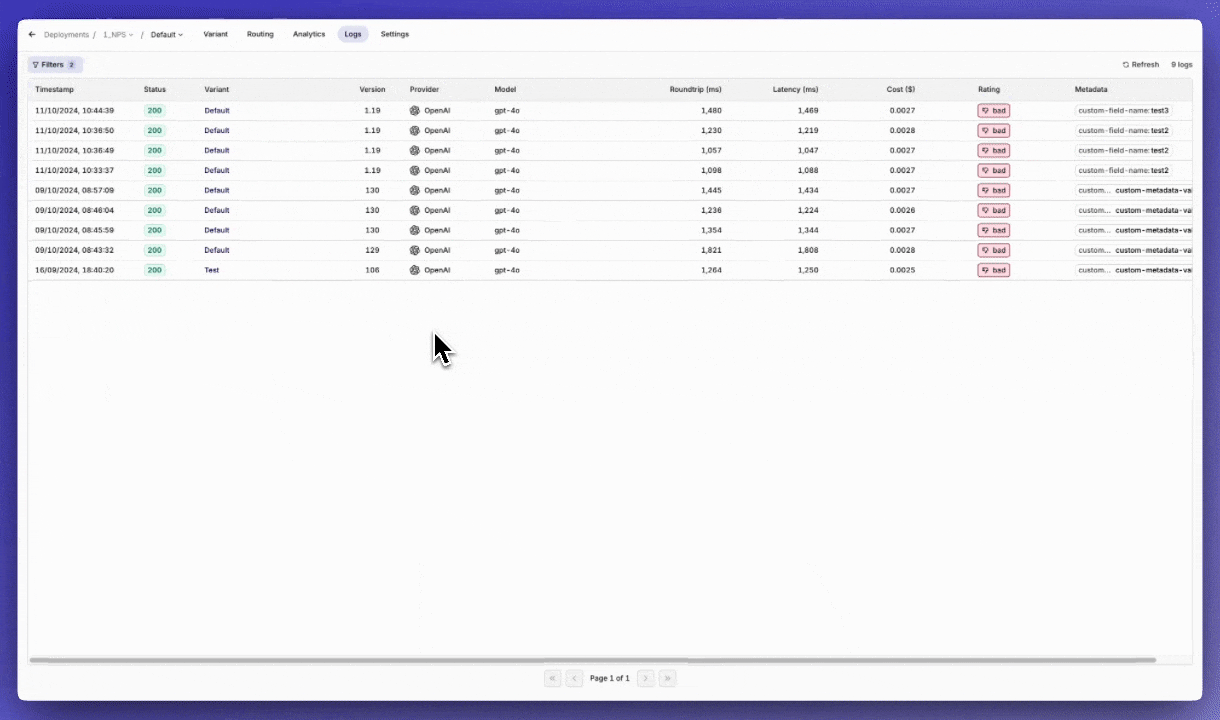
📘 Read more on our documentation page: Filters
Prompt Snippets
Introducing Prompt Snippets, a feature designed to boost your efficiency by allowing you to reuse key parts of your prompt across multiple variants.When working with multiple deployment variants that share common prompt elements, you no longer need to update each one individually. Instead, edit the snippet once, and all related variants will automatically reflect the change, saving you time and reducing manual effort.Using a Prompt Snippet
When you type{{snippet., a list of all available snippets will appear. You can then select the snippet you’d like to use.Configuring a Prompt Snippet
Head to the Prompt Library to create and configure your Prompt Snippet.Version control
Prompt Snippets are fully version-controlled, making it easier to track changes and correct mistakes, especially in collaborative environments. Be aware that updates to snippets will automatically apply to all deployments using them, so ensure any changes are intentional and properly tested.❗️ Please note that if you modify the snippet, all deployments containing that snippet will be automatically updated
📘 Read more on our documentation: Prompt.
Output Masking
We’ve added a new Output Masking feature to further strengthen security for the most sensitive use cases. With this feature, you can now mask the entire model’s output in a Deployment, providing an additional layer of data protection.In addition to the existing capability to mask input variables—such as marking patient_information as PII to prevent sensitive data from being stored on the Orq.ai platform—Output Masking extends this protection to the model’s complete output as well, ensuring that sensitive information remains secure throughout the entire process.Enabling Output Masking
Go to your Deployment > Settings > toggle Output Masking on.📘 Read more on how to set up Output Masking in our Deployment Security and Privacy documentation
Workspace usage metrics
We’ve added a new feature to the Billing page called Workspace Usage. This tool provides users with a clear overview of how many API calls they’ve used out of their available limit within their current billing cycle. The usage tracking starts from the beginning of your subscription.It’s important to note that exceeding your API usage limit does not stop you from making further calls. However, once you surpass the free API call limit, additional charges will apply for any extra usage.Structured outputs
Structured Outputs is a feature that makes sure the model’s responses always follow your provided JSON Schema. This means you don’t have to worry about the model leaving out any required parts or making up incorrect values.Why should you use Structured Outputs?
- Reliable format: You don’t have to check or fix responses using the wrong format anymore.
- Clear refusals: When the model refuses something for safety reasons, it’s now easily detectable programmatically.
- Easier prompts: You don’t need to prompt the model to adhere to the schema anymore.
Using Structured Outputs
There are two ways of using the Structured Outputs functionality:reponse_format(recommended) - In the dropdown menu (see GIF below), you can select the JSON pill and specify your schema.- Function Calling - In the tool, you can toggle the functionality of the structured output on/off.
- gpt-4o 2024-08-06 and later
- gpt-4o-mini 2024-07-18 and later
🚧 Reminder: To use Structured Outputs, all fields must be specified as required.
Improved authentication
🚧 We removed the email and password login combination to enhance the security of our platform.To improve the security of our platform, you will be able to log in using the following methods:
- Magic Link Sign-In: Enter your email address, and we’ll send you a login link with a code for easy access. This means that you can also set up Two-Factor Authentication (2FA) or Multi-Factor Authentication (MFA) for added security.
- Google Single Sign-On (SSO): Seamlessly log in using your Google account.
- Microsoft Single Sign-On (SSO): Use your Microsoft account for quick and secure access.
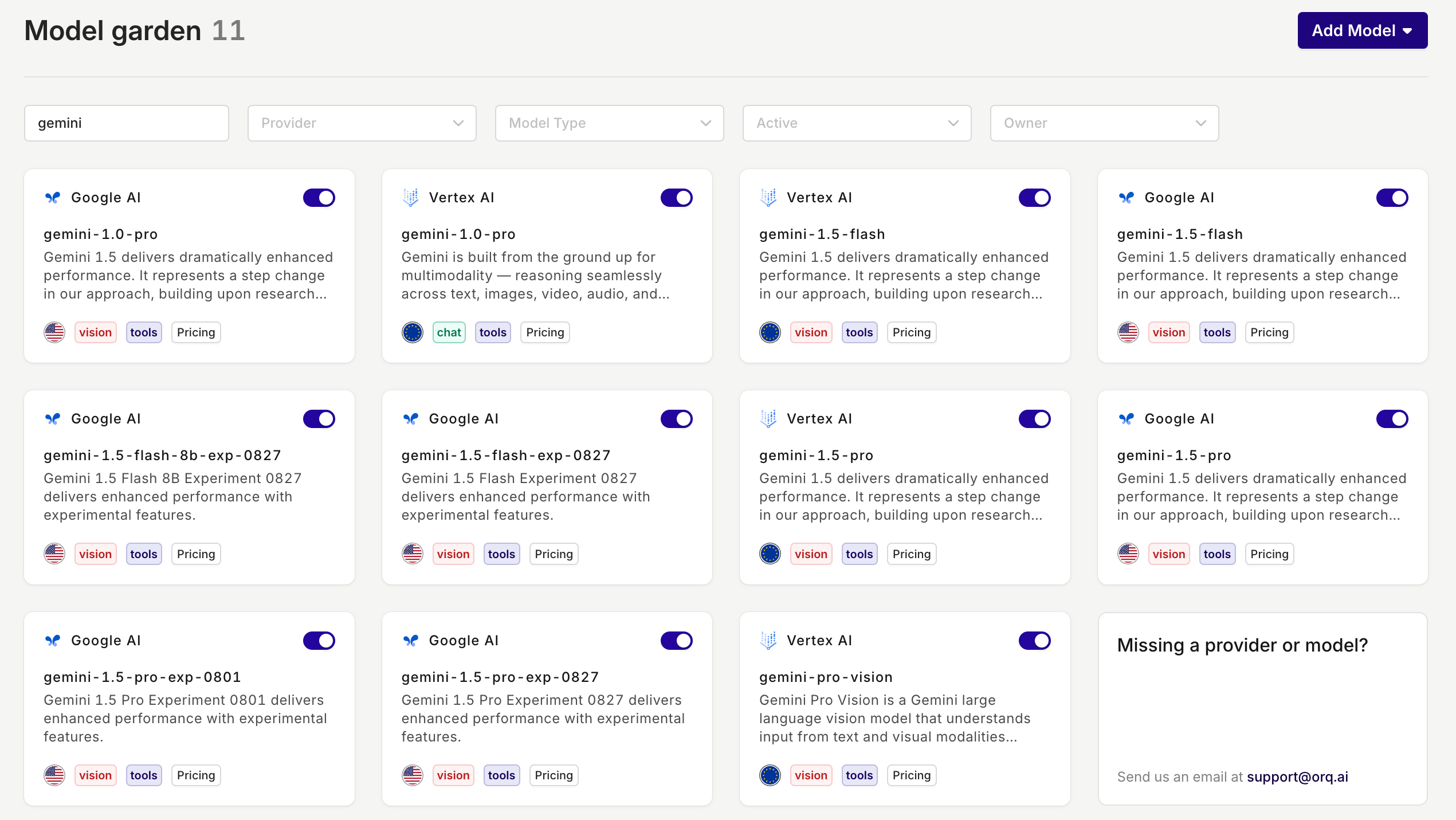
New GoogleAI provider and Gemini models
With the introduction of Google AI as a new provider on the platform, the previous ‘Google’ provider is renamed to Vertex AI.If you were using Google as a provider before, you don’t have to do anything, you will only see a different provider name. The model will remain exactly the same.📘 Google AI allows you to set up your own API keys, whereas VertexAI does not give you this option.
Why should I use Google AI instead of Vertex AI?
In addition to Google AI allowing you to set up your own API keys, they also offer their latest and experimental models. So, if you want to test out their newest models, Google AI is the way to go.The new models that are available in Google AI:- Gemini-1.5-flash-8b-exp-0827
- Gemini-1.5-flash-exp-0827
- Gemini-1.5-pro-exp-0801
-
Gemini-1.5-pro-exp-0827
Export Experiment Results
To give data scientists greater flexibility, we now allow you to export your Experiment results directly from Orq.ai. This update provides the freedom to extend your analysis beyond the platform, enabling you to work with your data in your preferred tools and environments.How it works:- Choose your file type: Select from CSV, JSON, or JSONL formats based on your specific requirements.
- Receive your data: After selecting your preferred format, your Experiment results will be compiled and sent to you via email, ready for further analysis.
- Leverage the exported data for custom visualizations, integrations, or further analysis in your preferred tools.
- Utilize the output of LLM generations in various formats for downstream tasks or additional finetuning.
Knowledge Bases & RAG
Start building even more reliable AI applications by equipping LLMs with accurate and relevant knowledge. This will greatly improve their knowledge and thus reduce the likelihood of hallucinations.Why use a Knowledge Base?
The primary purpose of a knowledge base and a Retrieval-Augmented Generation (RAG) is to provide a reliable source of information that an LLM can access. By querying a knowledge base, an LLM can retrieve relevant data to answer questions or solve problems more accurately. This integration ensures that the information provided is both relevant and precise, enhancing the overall effectiveness of the model.Use cases
- Reduced Hallucination: By relying on a well-structured knowledge base, the likelihood of the LLM generating incorrect or fabricated information (hallucinations) is significantly decreased.
- Specific Context: A knowledge base allows for the inclusion of domain-specific or company-specific information, ensuring that the responses generated by the LLM are more aligned with the intended context.
- Up-to-Date Information: Unlike static models, a knowledge base can be continuously updated with the latest information, providing the LLM with current and accurate data.
📘 Read more about Knowledge Bases in our Knowledge Base docs
Webhooks
A much-requested feature, webhooks, is now added to the Orq.ai platform.Webhooks allow you to automate a lot of things in real-time, including:- Automated data ingestion and processing: feeding real-time data from sources into Orq.
- Automated workflow orchestration: triggering specific deployments based on events.
- Logging: the ability to store the requests (input and output) back into your system.
- Monitoring and alerting: set up webhooks to alert relevant stakeholders about changes in model performance.
📘 Read more about webhooks in our docs.
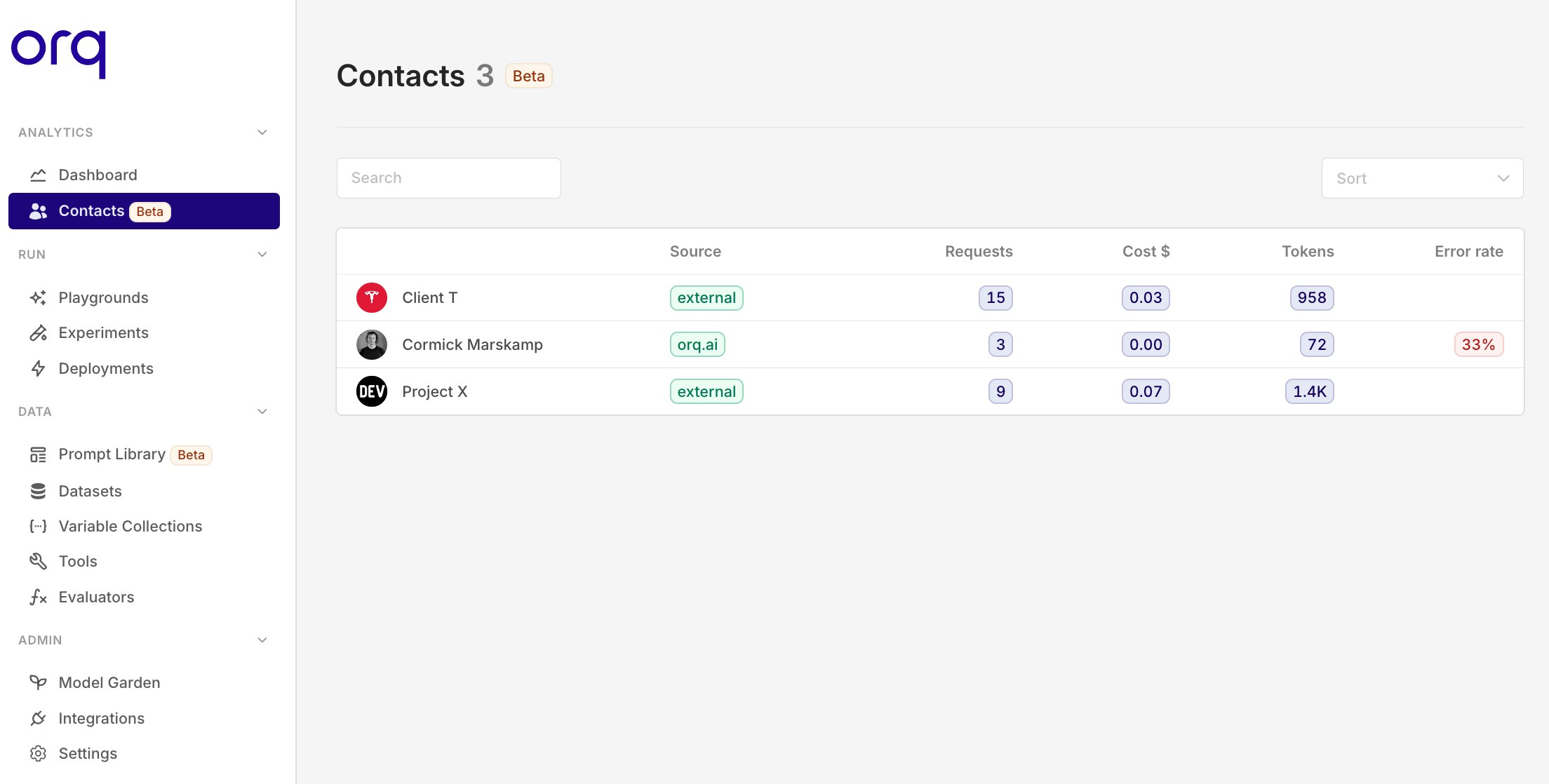
Contact analytics
To gain more insights and control over your LLM consumption, we added contact analytics.A contact is an entity that can be anything you’d like to track, such as an individual, team, project, or client.Some use cases include:- Track Individual Users: Monitor costs and error rates for timely support.
- Track Internal Projects: Ensure projects stay within budget and meet goals.
- Track Client Projects: Get clear metrics per client projects.
-
Track Specific Teams: Analyze team performance and optimize resource allocation.
📘 Read more on how to set up contact analytics in our docs
Onboard private models on Azure
You can now add your own private and/or finetuned models to the Orq.ai AI Router.As of now, you can only add models hosted on Azure. Soon, we’ll also support the self-onboarding of private models through OpenAI and Vertex AI.Use the interactive walkthrough below to see how the onboarding process works.Debug more effectively
The Debug tab is back. Did your request fail, and do you want to look into the payload? Navigate towards the debug tab and find out what has been happening.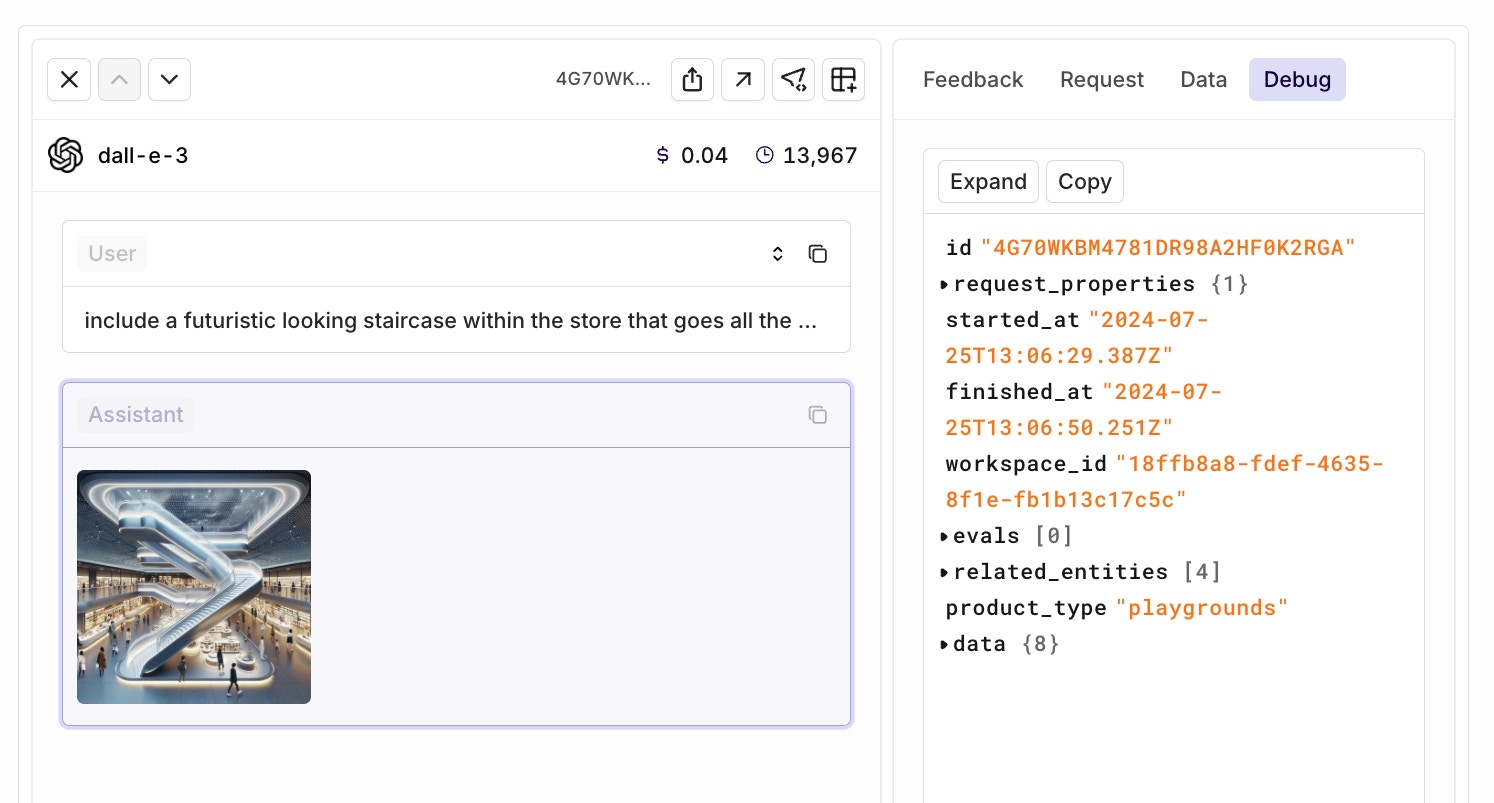
Provider_response added in the SDK
We did add the rawprovider_response to our Python and Node SDK. This will give you the flexibility of retrieving model-specific output that we don’t provide through our unified API.See an example response below:GPT-4o mini
OpenAI has introduced GPT-4o mini, a smaller, more efficient, and cheaper model replacing GPT-3.5 Turbo. This follows similar moves by Anthropic (Claude 3 Haiku) and Google (Gemini 1.5 Flash).Key features:- Significantly smarter than GPT-3.5 Turbo, but not as capable as GPT-4o (see benchmark).
- 60% cheaper compared to GPT-3.5 Turbo.
- It’s a vision model, meaning it can interpret images.
- Context window is as big as GPT-4o (128k).
Claude 3.5 Sonnet
Two hours after Claude 3.5 Sonnet was released, it became available on Orq.ai. Toggle it on in the AI Router and try it out yourself!A little about the new model. First off, Claude 3.5 Sonnet can handle both text and images. It’s also Anthropic’s top-performing model to date, outshining the previous Claude 3 Sonnet and Claude 3 Opus in various AI benchmarks (see image).One area where Claude 3.5 Sonnet does seem to excel is in speed. Anthropic claims it’s about twice as fast as Claude 3 Opus, which could be a game-changer for developers building apps that need quick responses, like customer service chatbots.The model’s vision capabilities have also seen a significant boost. It’s better at interpreting charts, graphs, and even reading text from less-than-perfect images. This could open up some interesting possibilities for real-world applications.However, it’s worth noting that Claude 3.5 Sonnet still has the same context window of 200,000 tokens as its predecessor. While this is a decent amount (about 150,000 words), it’s not a step up from what we’ve seen before.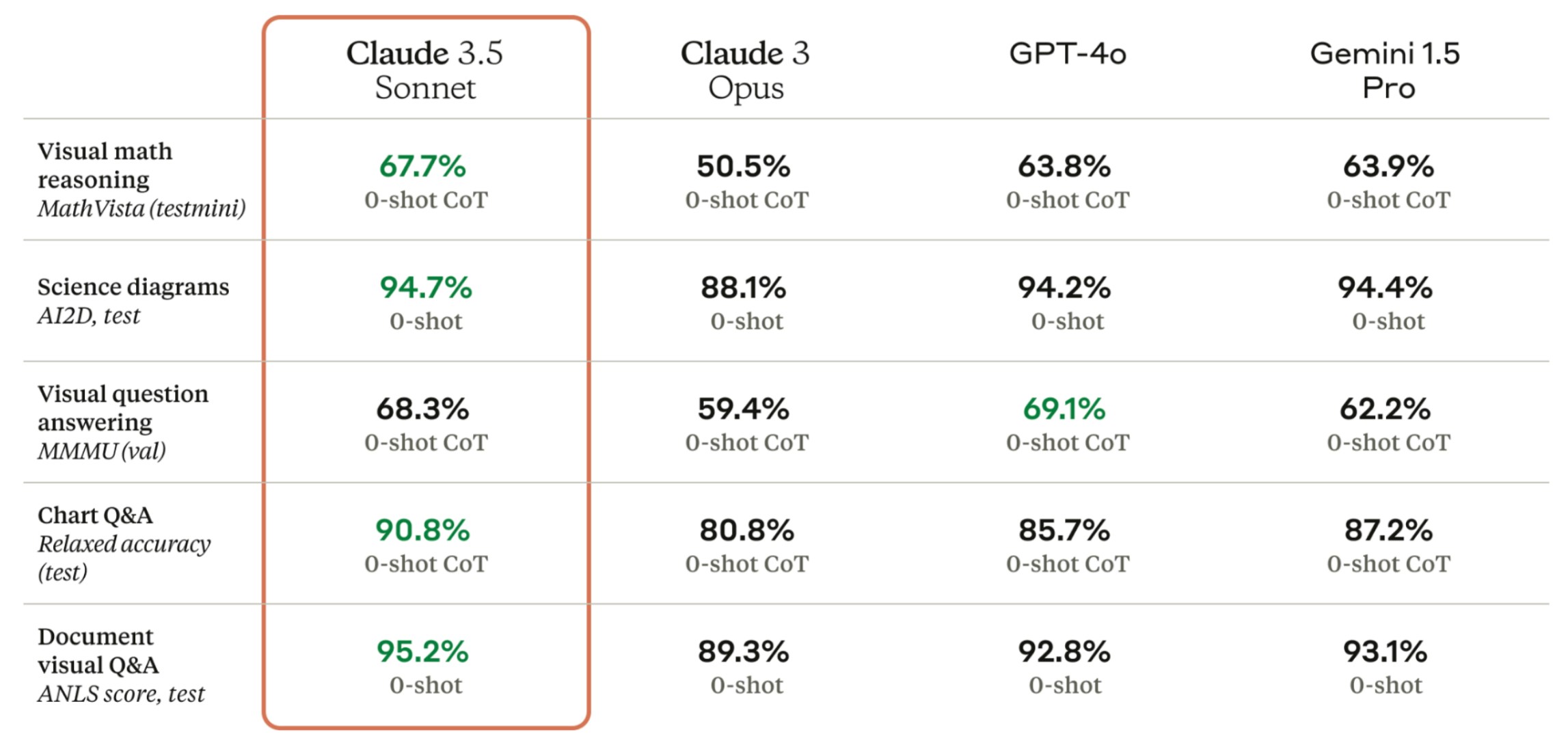
Prompt library
The new Prompt library lets you create prompt templates that you can reuse throughout the whole platform.With the filtering capabilities, you can easily find the right prompt for your use case and effectively manage multiple prompts.Check the new feature out in your workspace or in this interactive walkthrough below.Llama 3 on Perplexity
Start using the best open source model, hosted on perplexity, in Orq.You could already use the Llama 3 models hosted on Anyscale and Groq. However, being able to use Llama-3 on Perplexity opens up new possibilities and use cases.Because the model is able to go online, it is able to:- Generate up-to-date responses
- Retrieve dynamic data about the latest news etc.
- Understand real-world context better
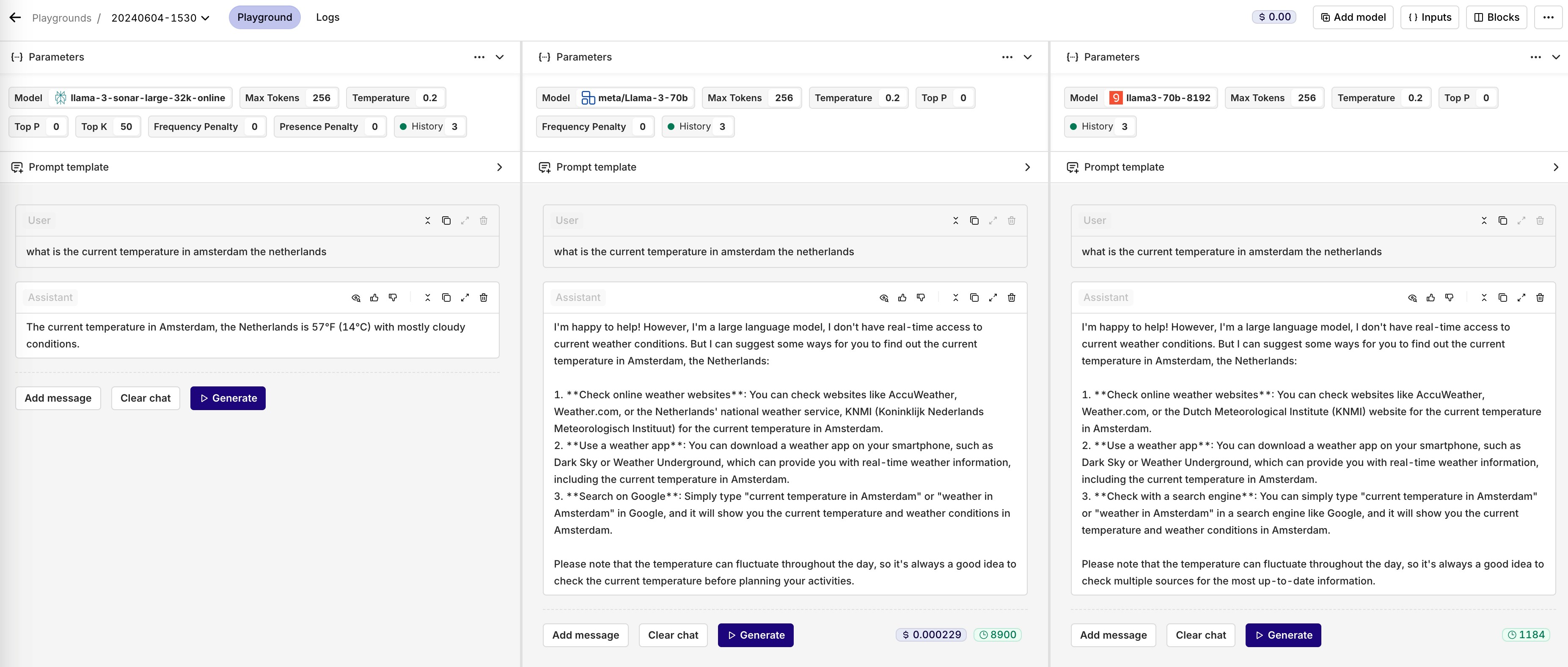
Multi API key selector
You can now select which API key to use in your Playgrounds, Experiments, and Deployments.Select which API key to use with the new integration selector pill.This only works after you have set up more than one API key. Note: This feature does not apply on Azure and AWS.In the example below, I use the exact same model configuration as my fallback model. However, I will use my second API key in case the first one doesn’t work.
Deployment test run
Preview your LLM call in the Deployment studio.This new feature allows you to quickly do a test run. You still have the option to open the same configuration in the Playground for further testing.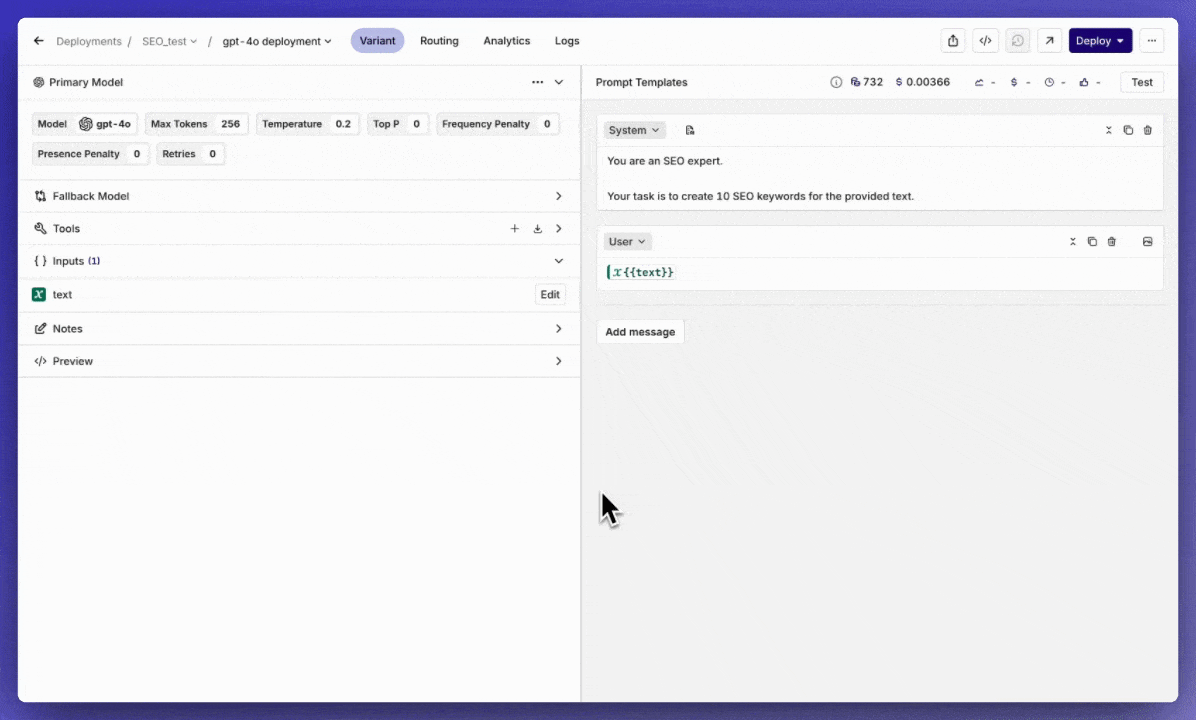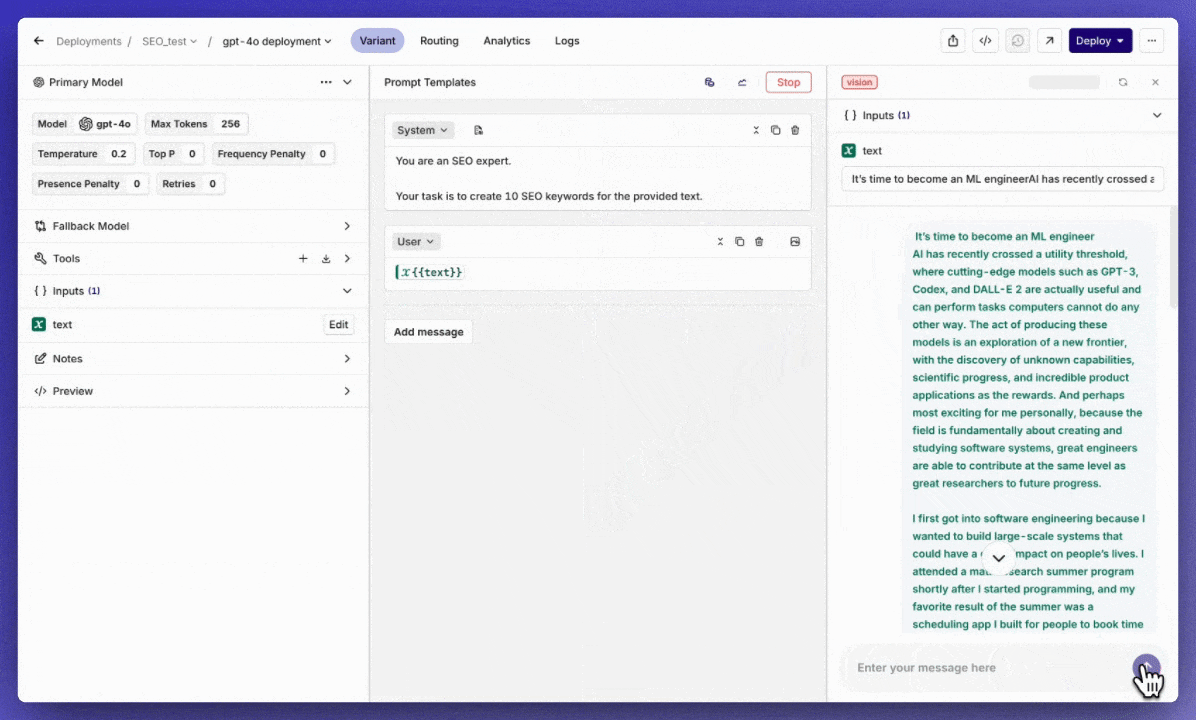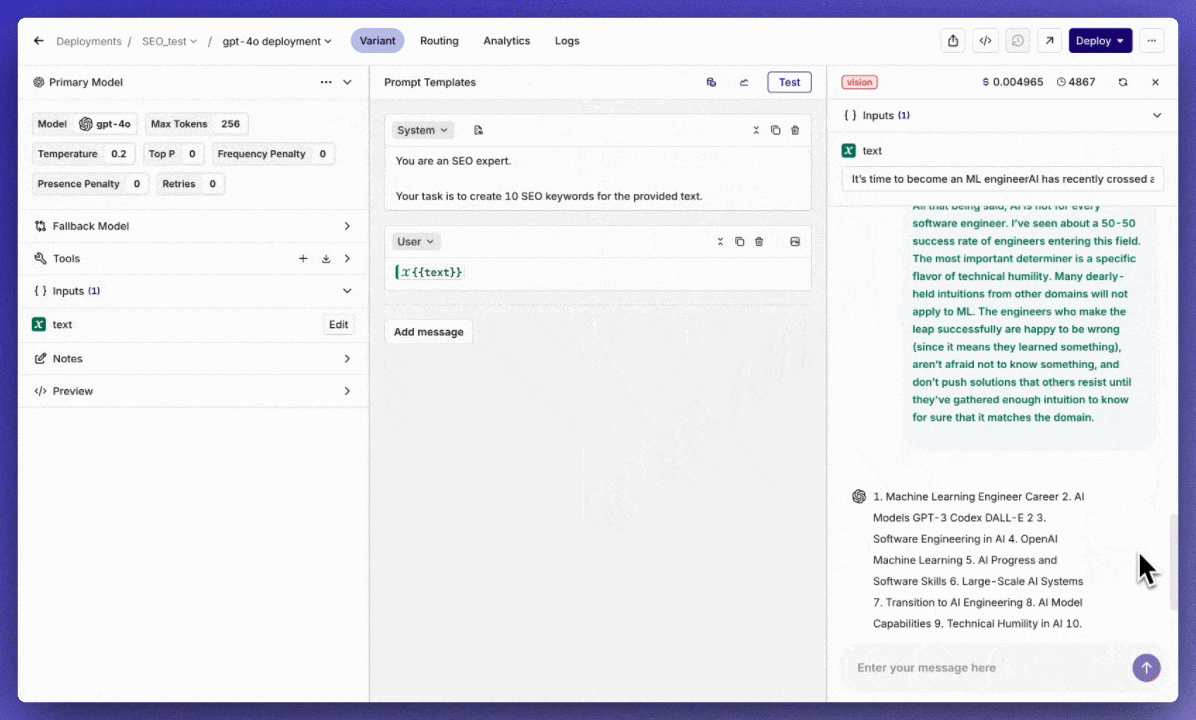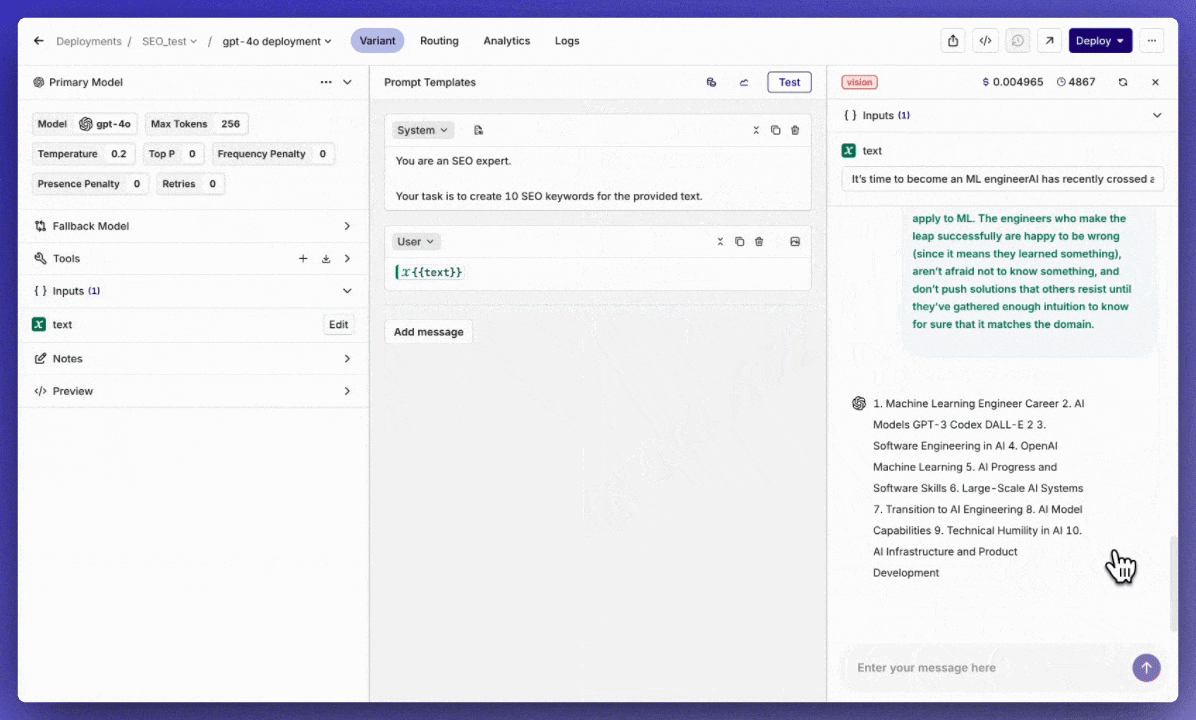

Keyboard shortcuts
For the real prompt engineers in Orq, we introduced some keyboard shortcuts in the Playground module. If your cursor is located within the prompt template, you can use the hotkeys below to generate an output.cmd/ctrl + enter runs the current block.shift + cmd/ctrl + enter runs all the blocks.Feel free to contact us for other shortcut suggestions.New version pop-up
With the introduction of the new version pop-up, you can now choose when you’d like to do the update. This way, you won’t get interrupted in the middle of your workflow.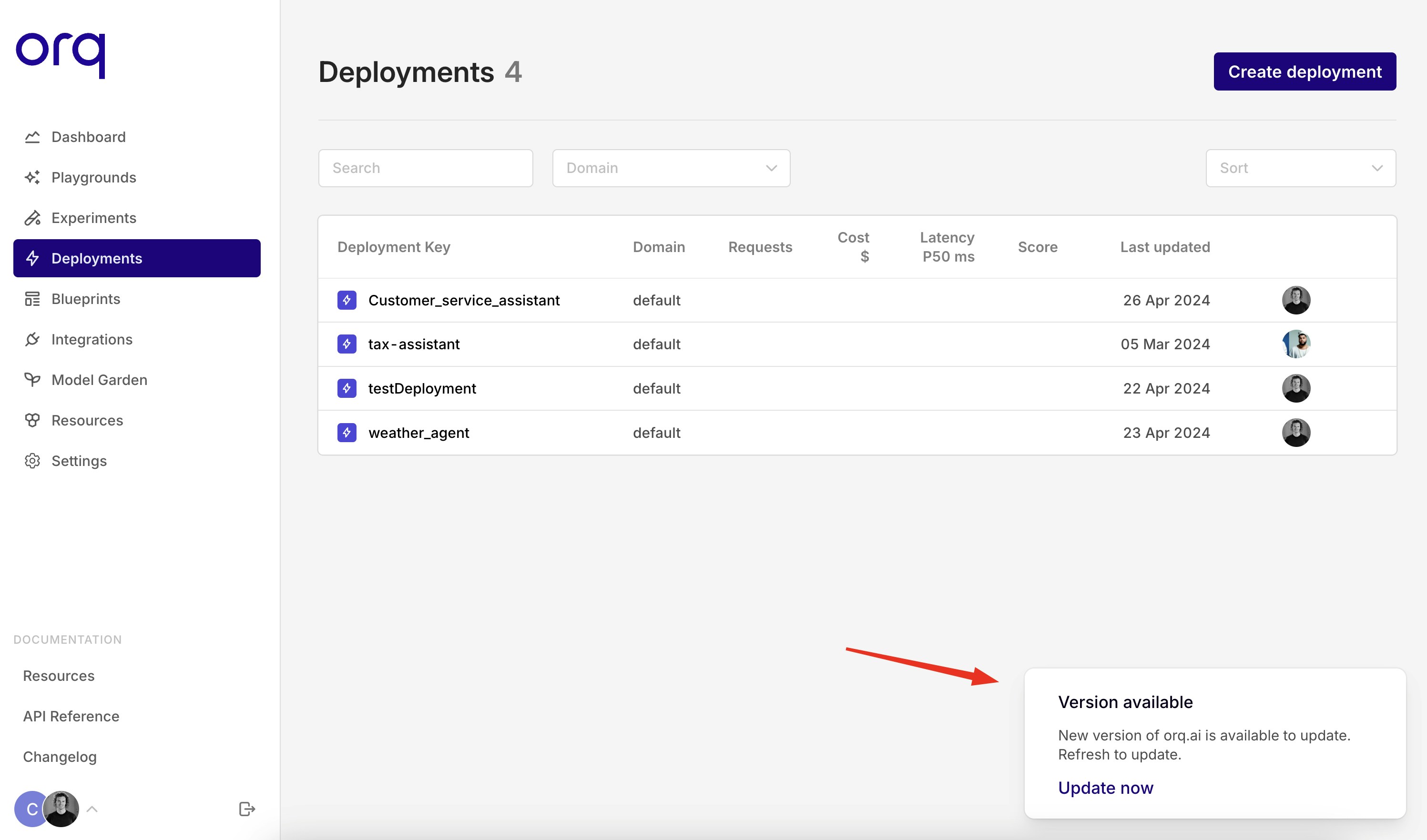
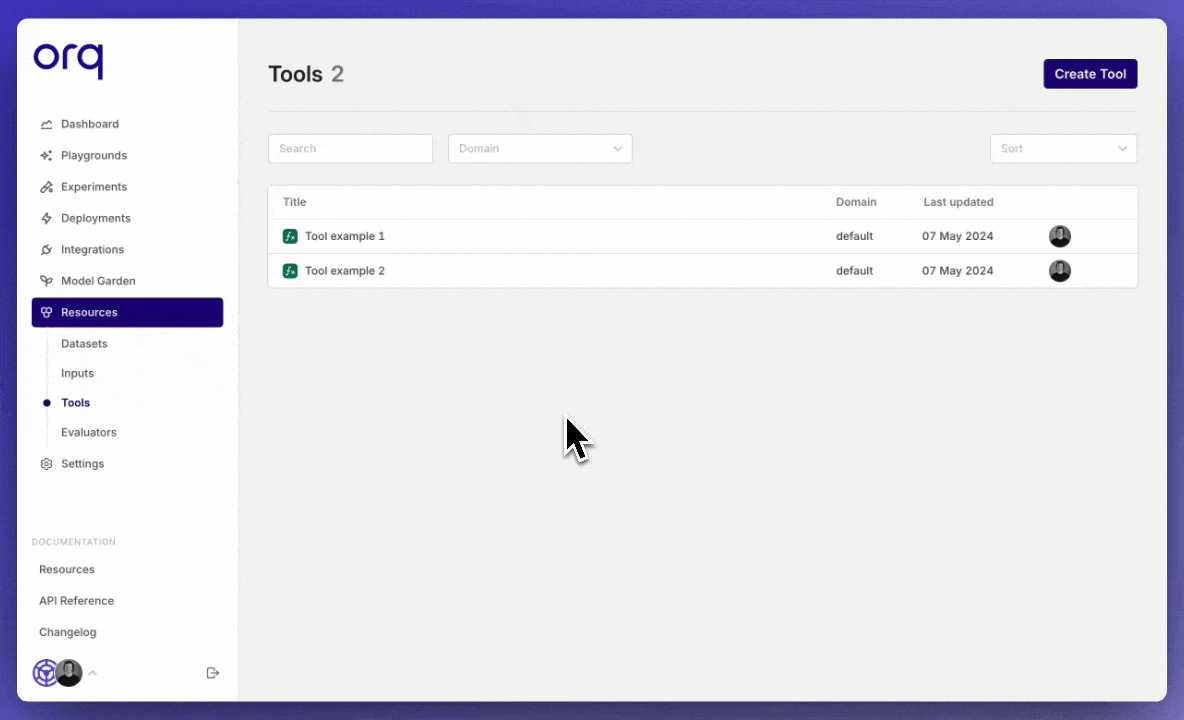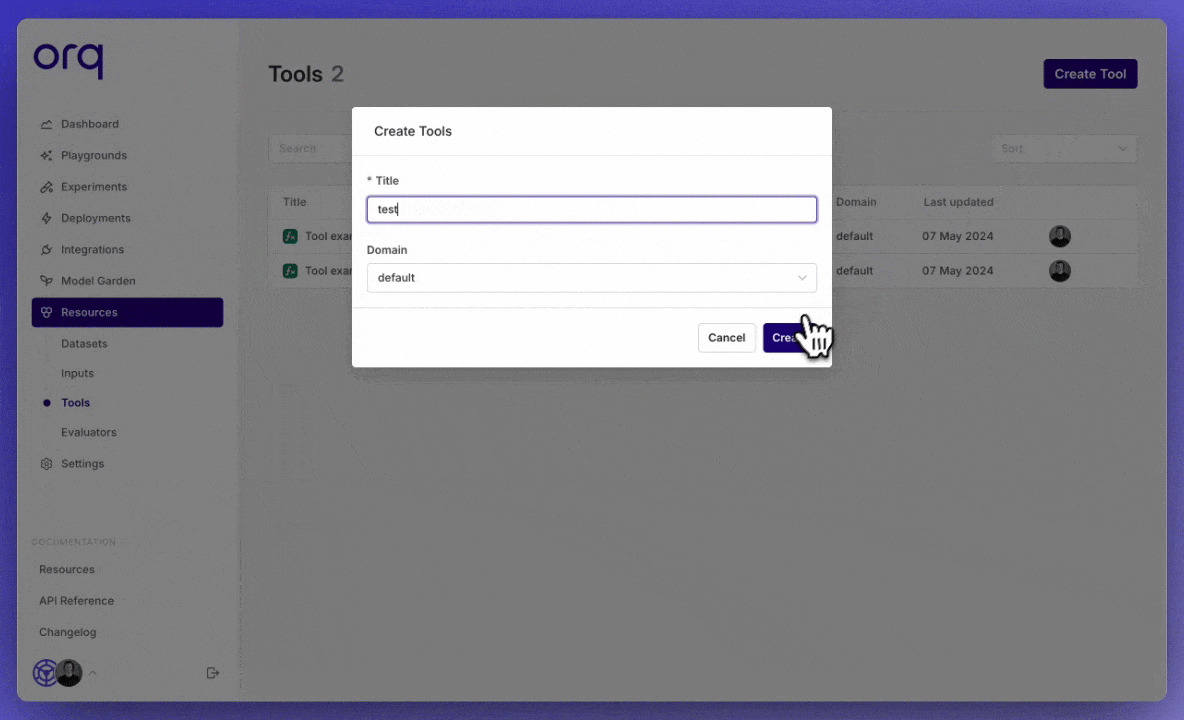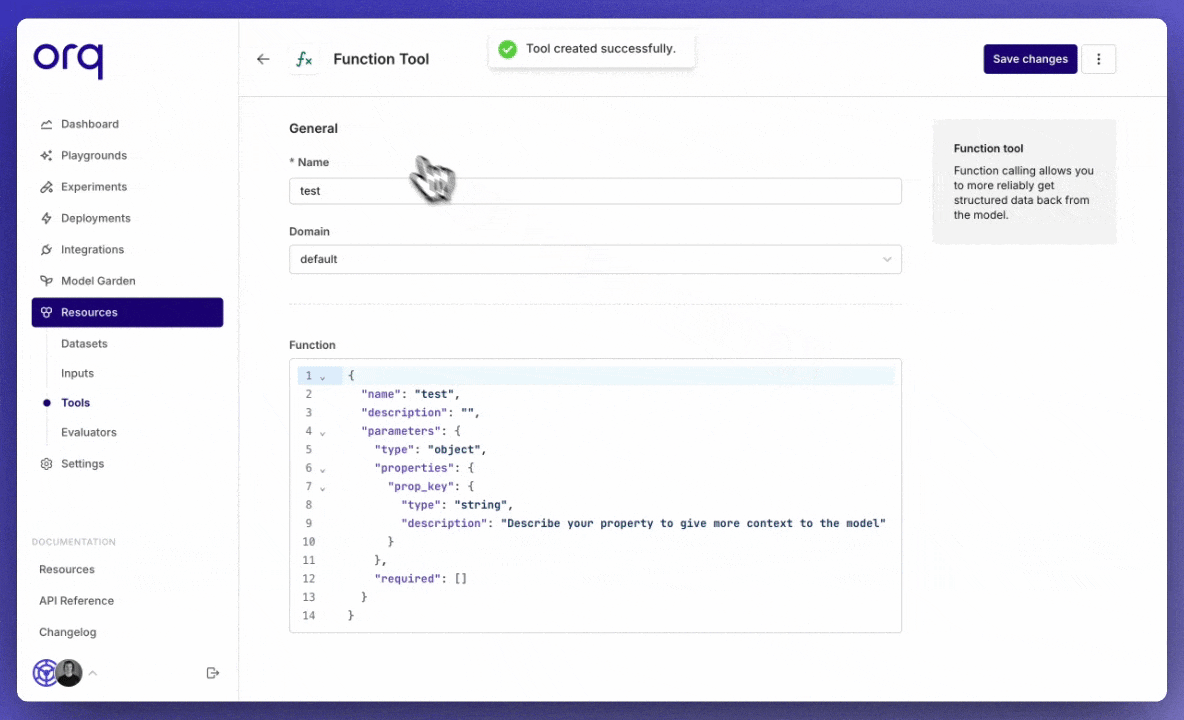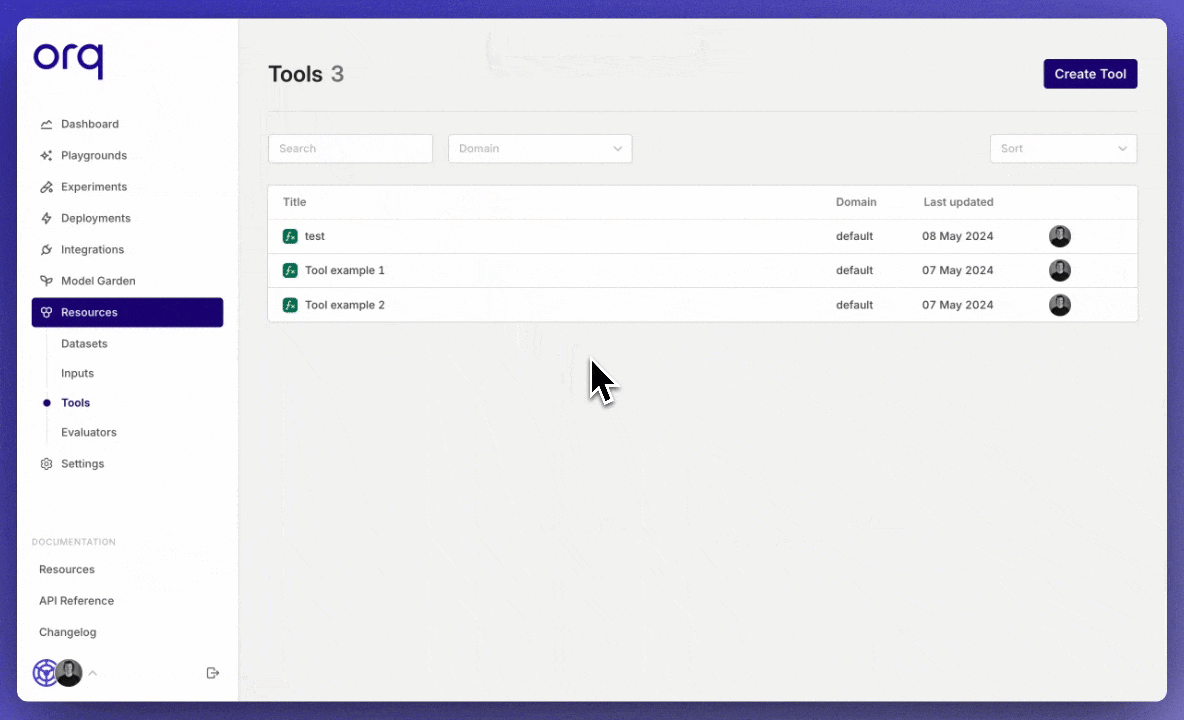
Tools workflow
Quickly import a Tool into a Deployment.Also, when creating a Tool in a Deployment, you can save it by clickingAdd to resources.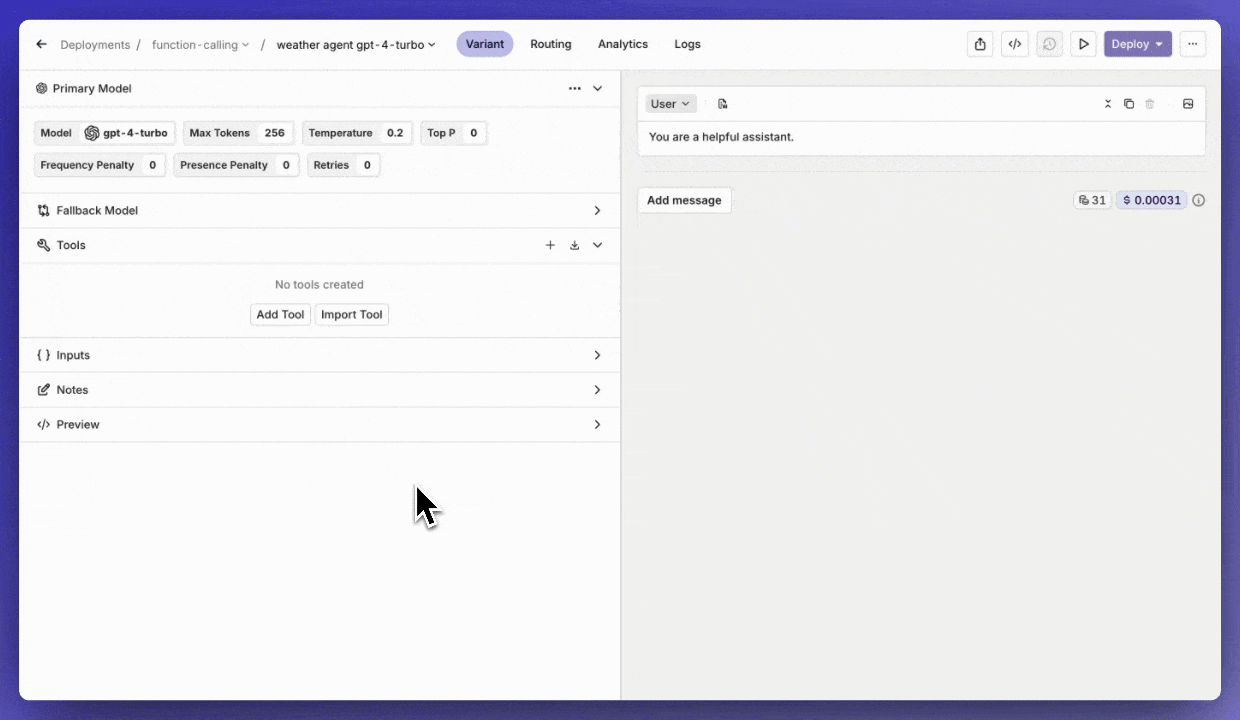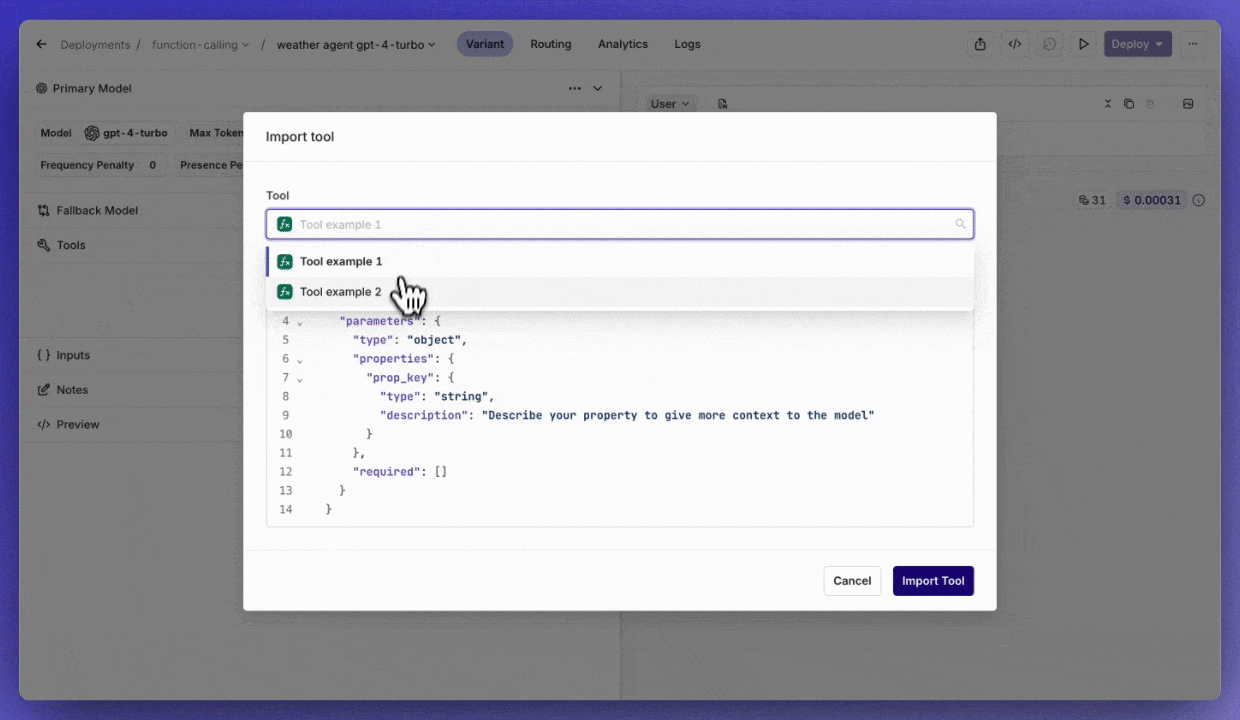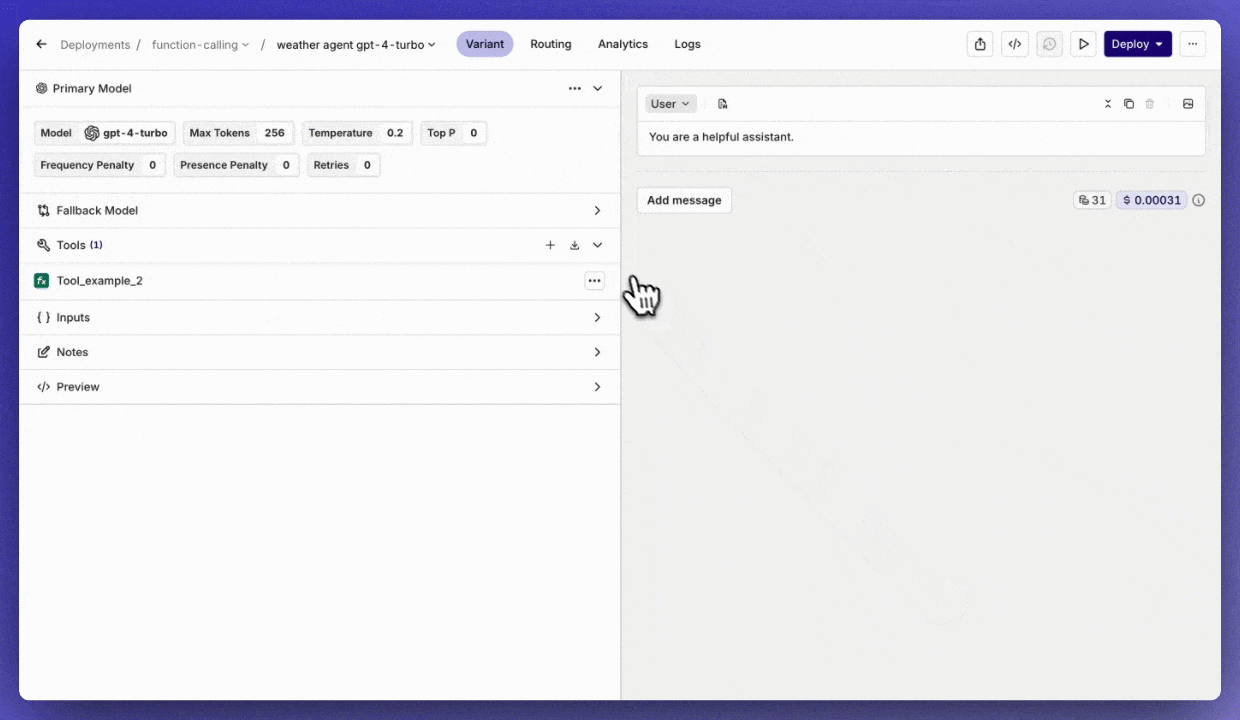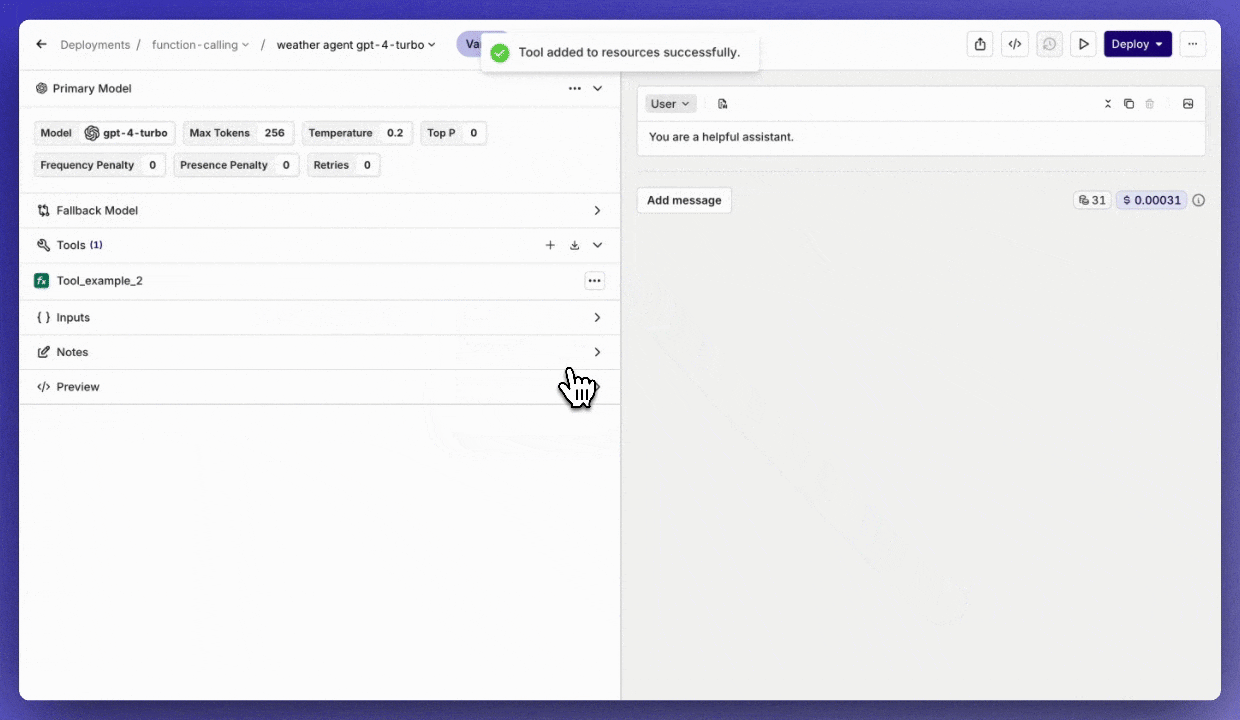
New domain for ORQ.ai
🚧 If you’re using my.orquesta.dev please start using my.orq.ai
Version Controlled Deployments
With this new feature, you can view the changes made to a Deployment and restore to the previous version if needed. On top of that, when deploying, users get the option to write a quick description about what they changed and if it’s a minor or major change.
On top of that, when deploying, users get the option to write a quick description about what they changed and if it’s a minor or major change.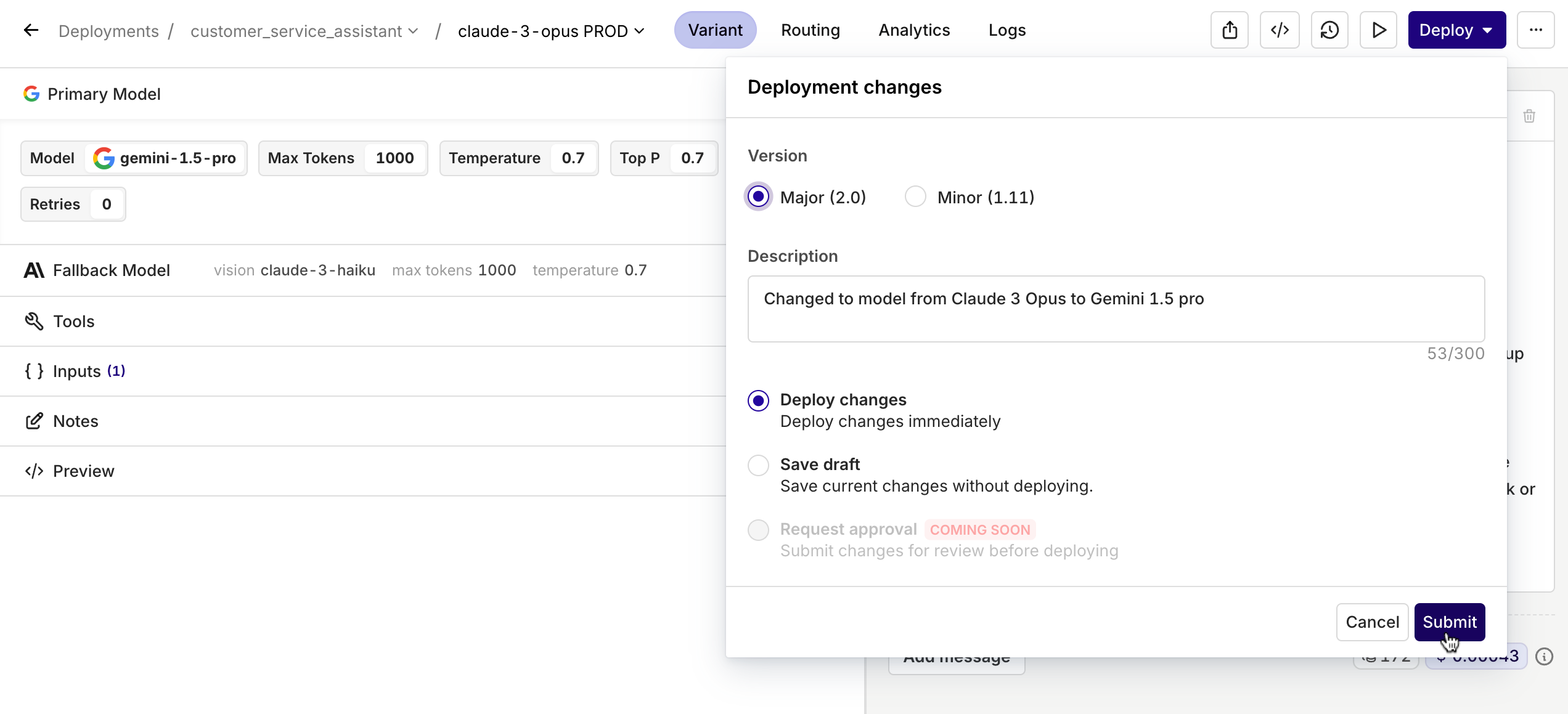
Deployment Routing
When opening a Deployment, you now immediately enter the Prompt Studio.To switch to other Variants, you can click on the variant name, which opens a dropdown menu with all the other variants that you can choose to switch to. In the same dropdown menu, you can also choose to add another variant.Under the new Routing tab, you can still see the Business Rules Engine and configure it like you’re used to.
Prompt generator
With this new feature, we can help you turn your prompt into a more detailed and complete prompt.You can also use it to create a template which you can iterate on.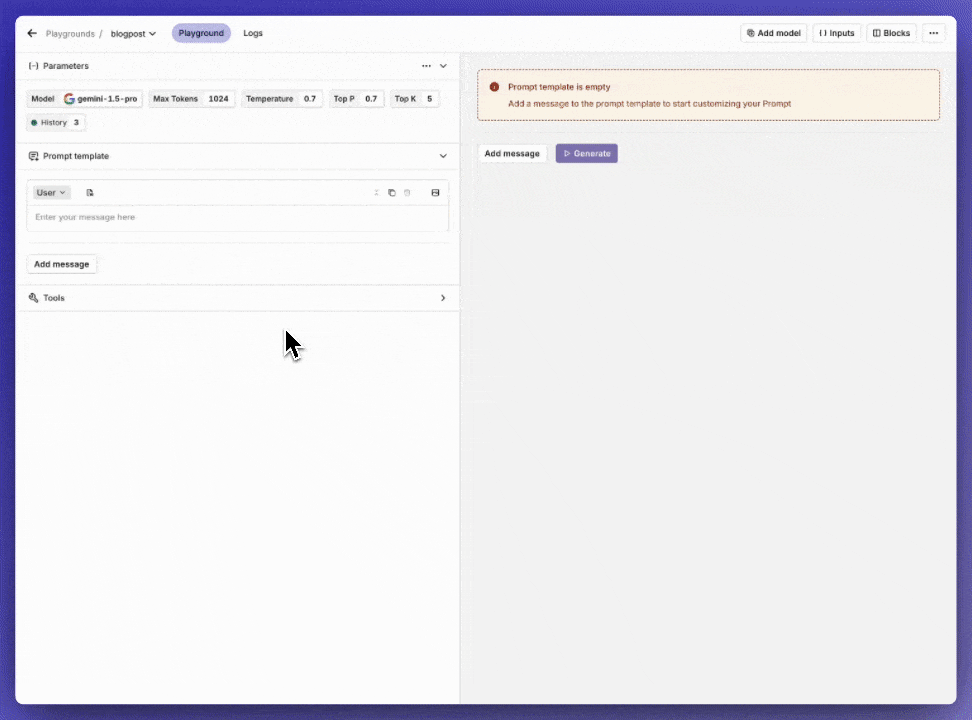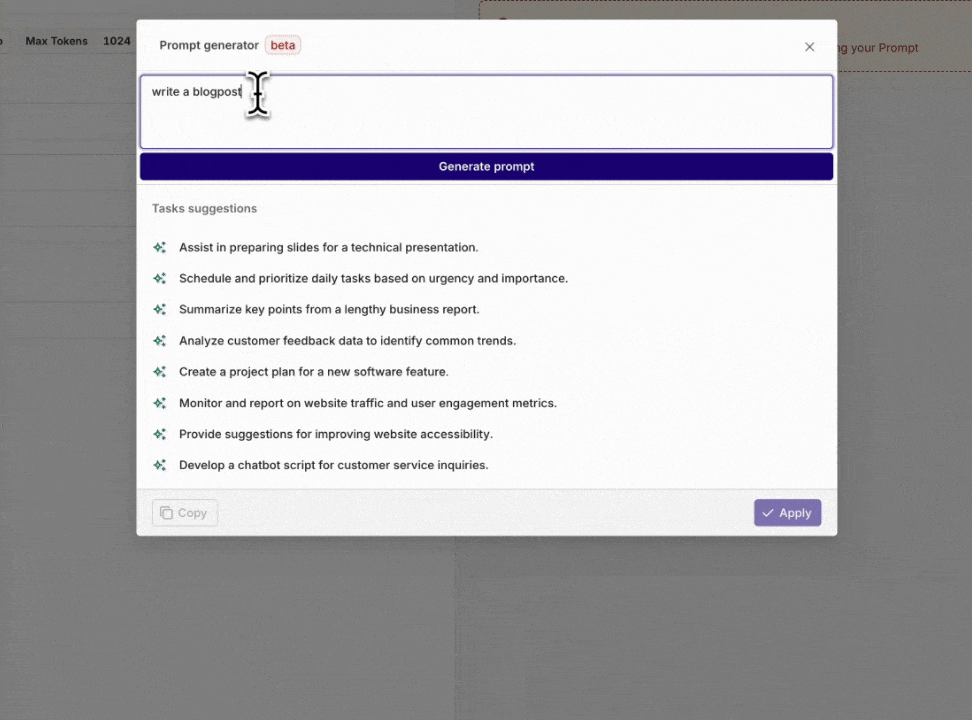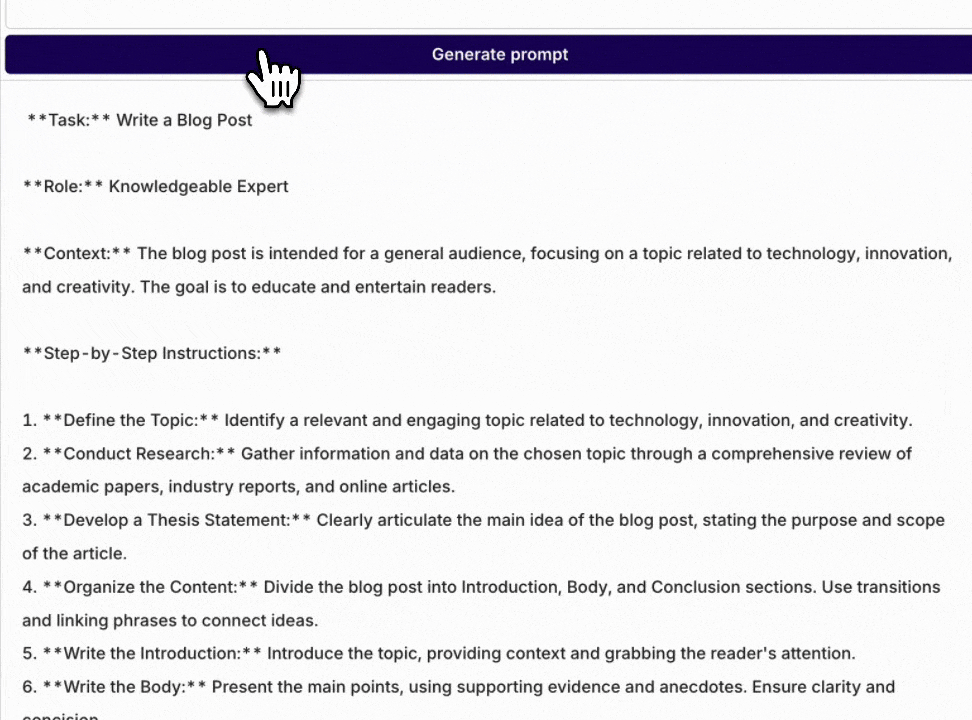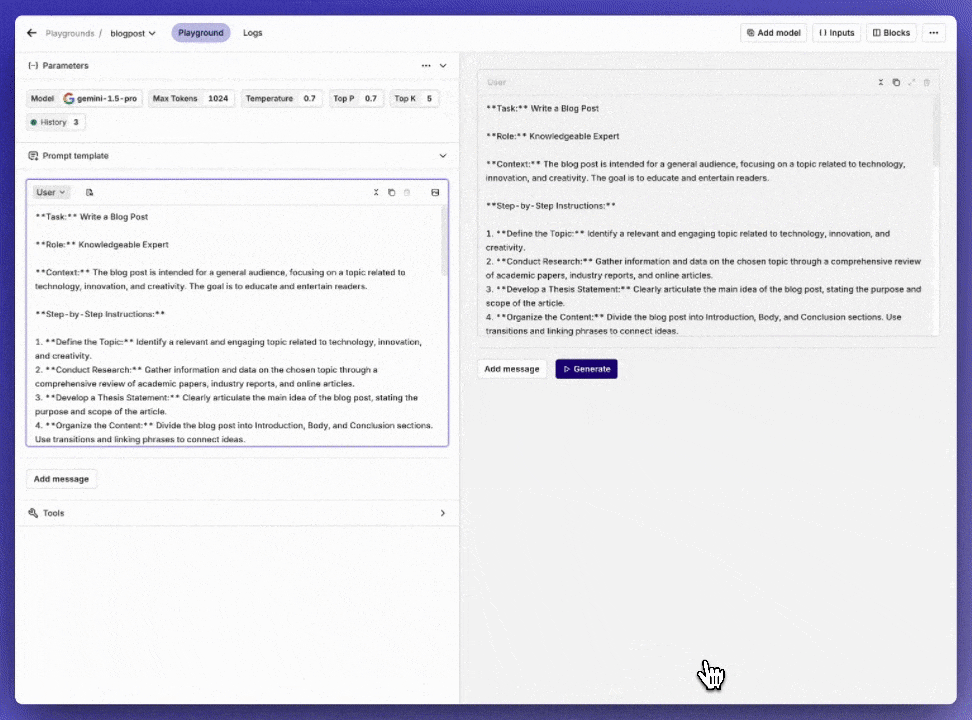
Tools in Experiments
Start using Tools, also known as Function Calling, in an Experiment.Once you have set up your Tools in the Resource Tab, you can add them in the configuration tab in your Experiment.A strong feature is to use Tools in combination with the Valid JSON and Valid JSON Schema Evaluators.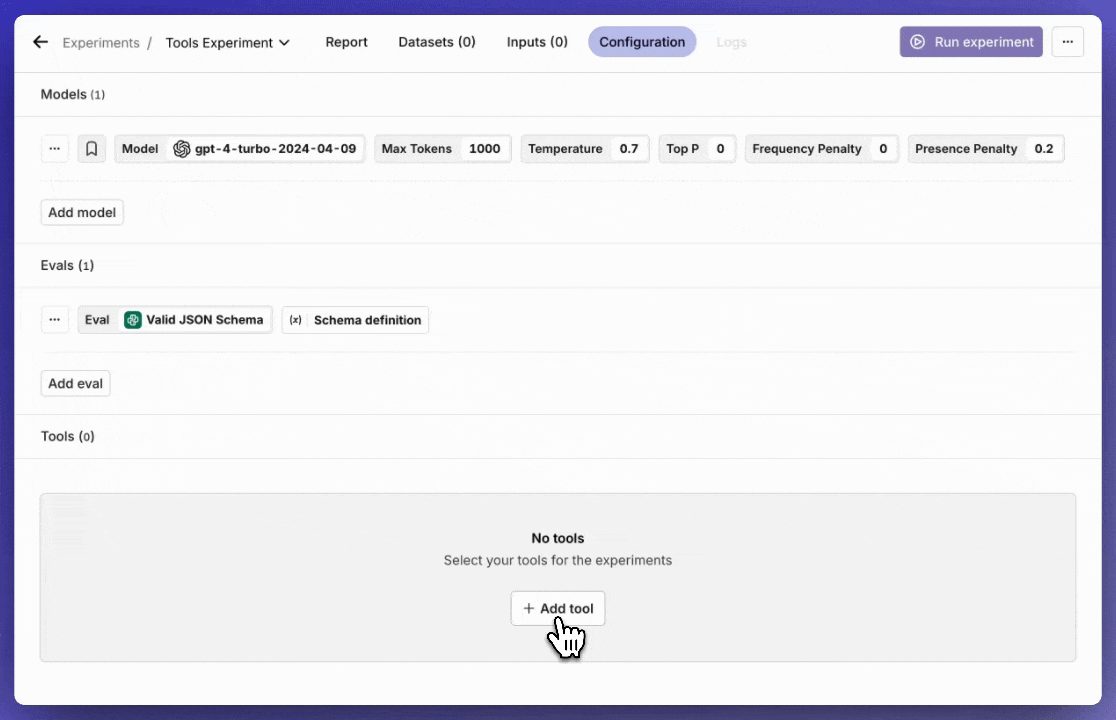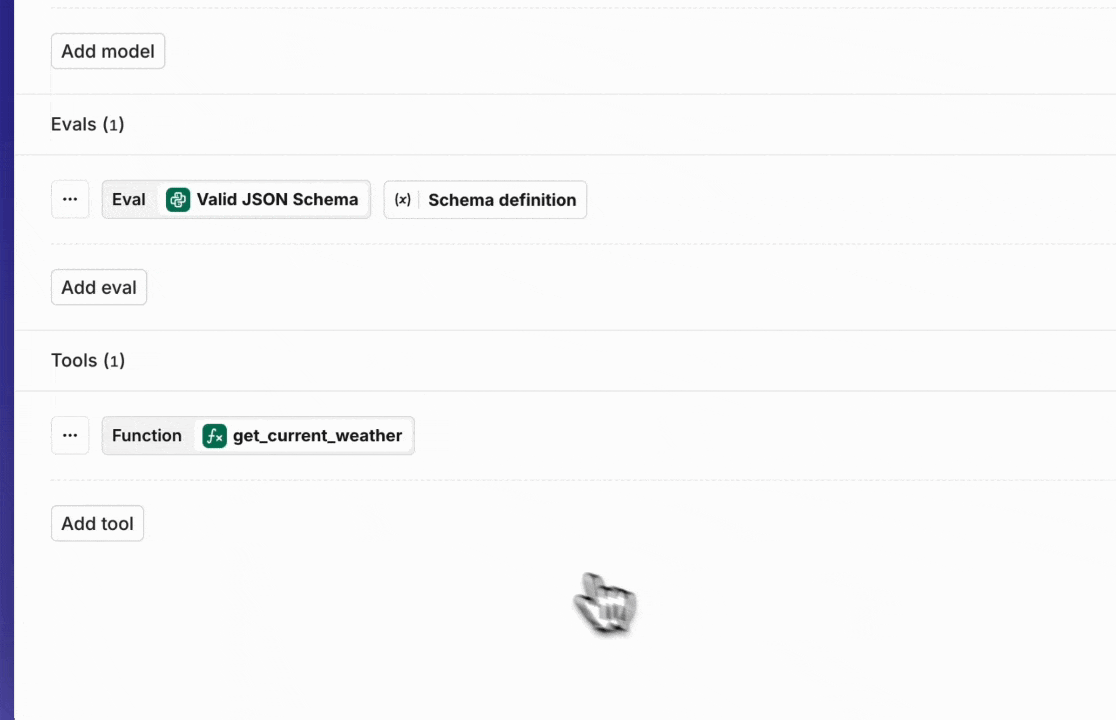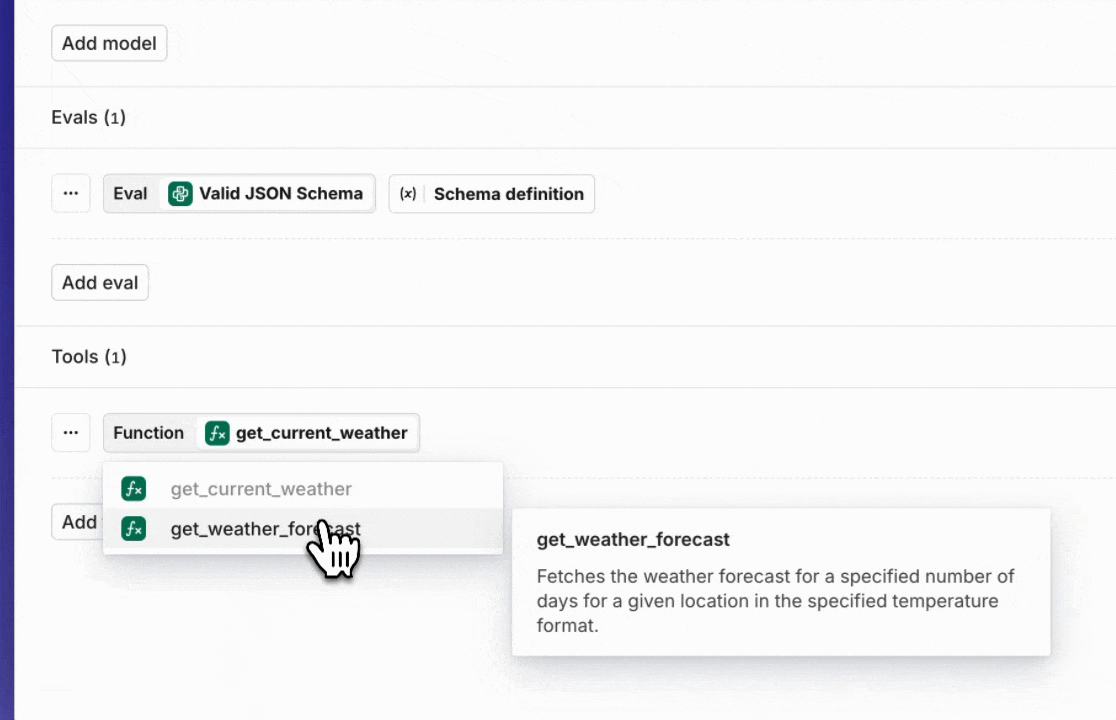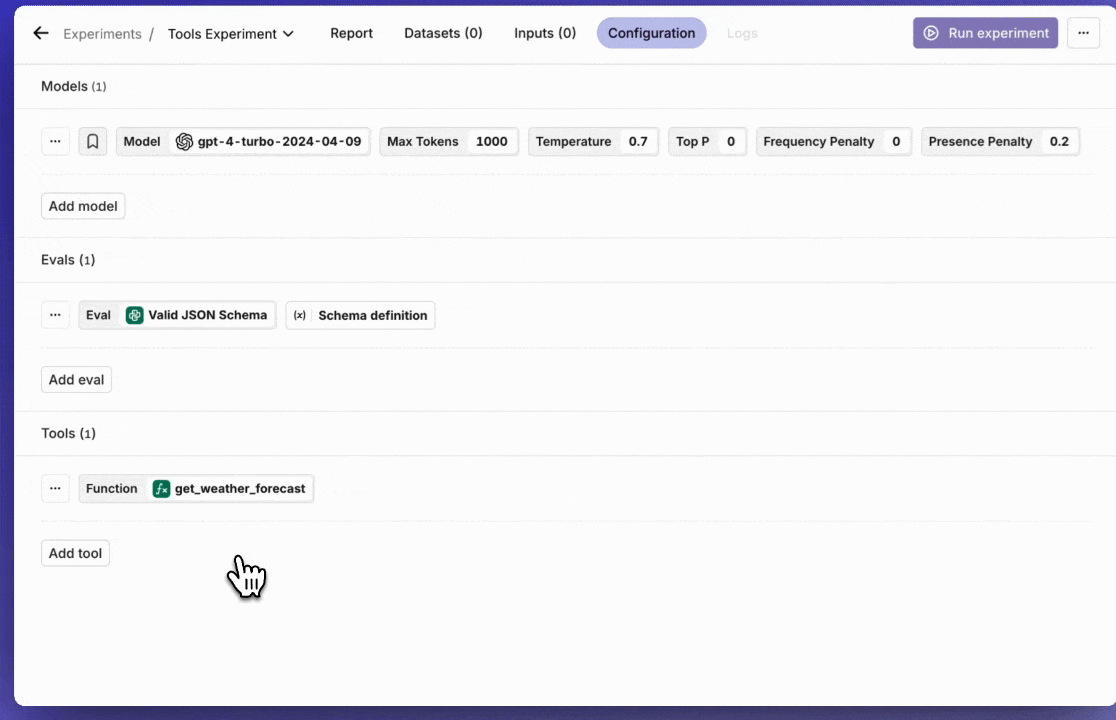
Breadcrumb navigation
With breadcrumbs, you’ll always know in which module you’re working. On top of that, breadcrumbs allow for quick navigation within the module. See an example below.
Experiment aggregate metrics
With the new Experiment aggregate metrics, you can do a much more accurate comparison between models and/or configurations.These filters are crucial when doing large Experiments. The heatmap still provides you with a quick glance at what the differences are, but the filter allows you to make a more precise comparison.The filter includes the sum, average, median, min, max, range, and standard deviation.
Set up your Tools in Resources
Set up your Tools in the Resources tab.This update allows you to reuse your Tools across the platform. Also, if you want to use Tools in an Experiment, you have to set them up within the Resources tab first in order to select them.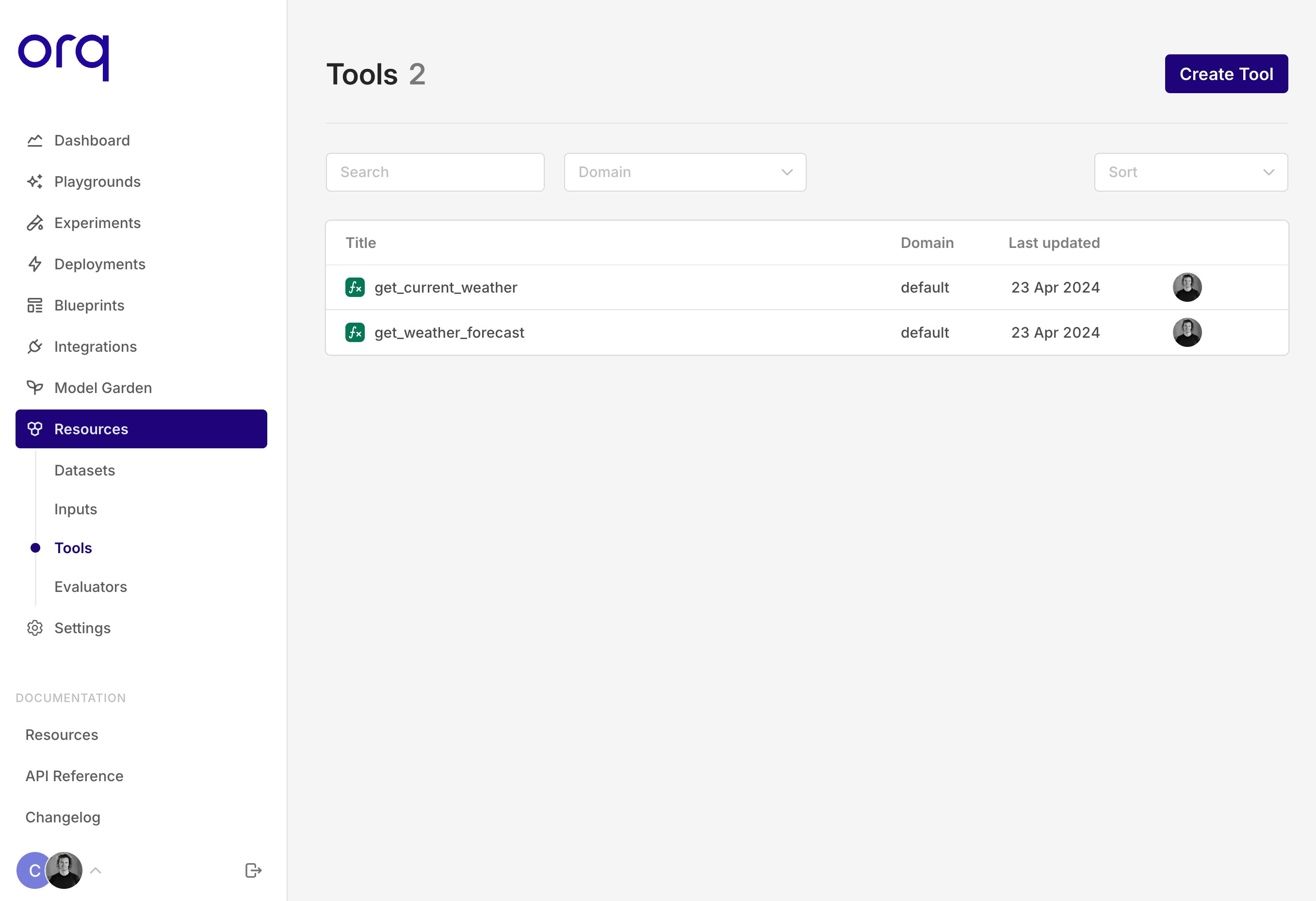
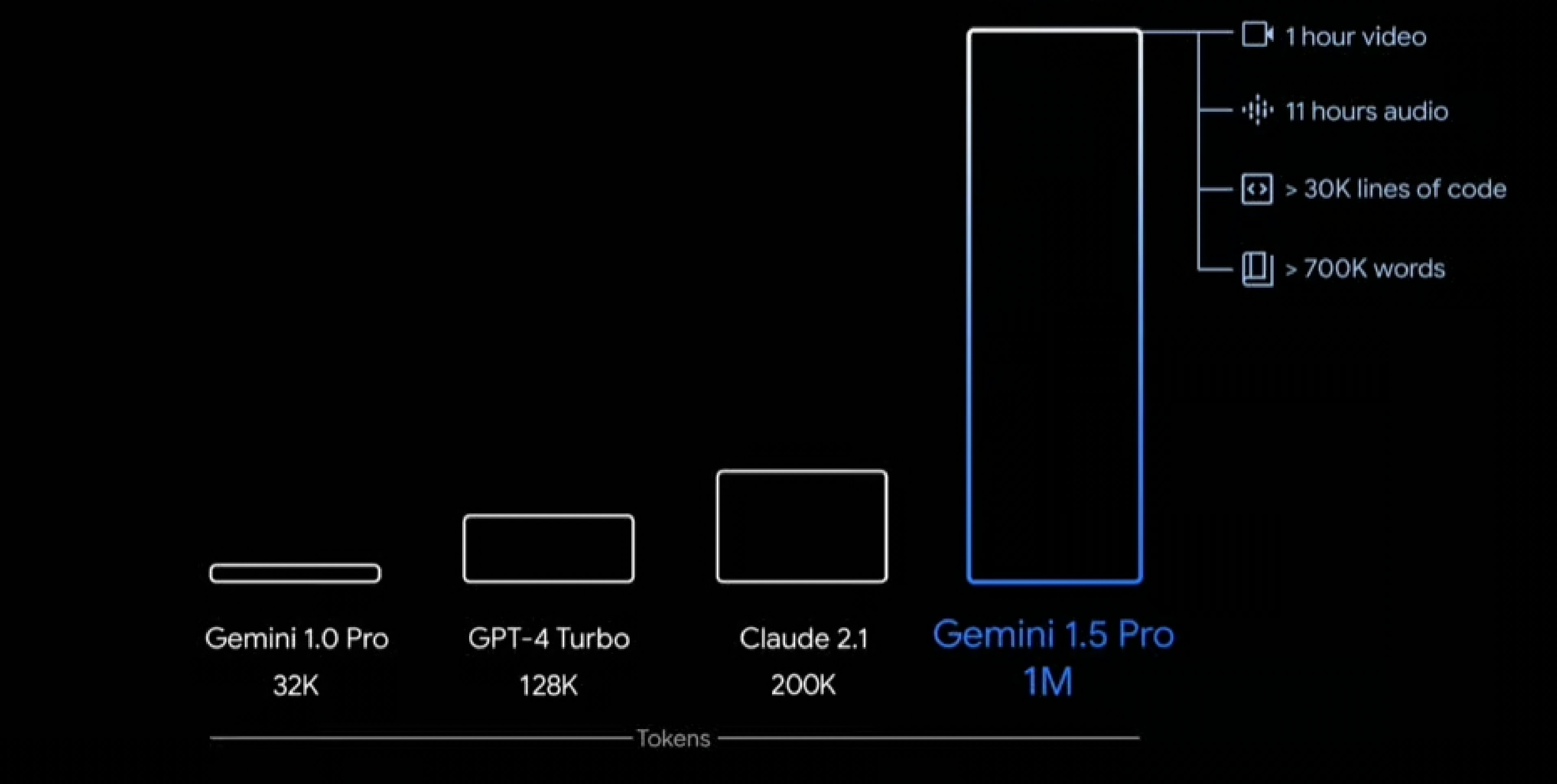
Google Gemini Pro 1.5
Start using Google’s Gemini Pro 1.5 across all three modules on Orq. The newest model from Google is not only more advanced than its predecessor but also boasts several key differentiating features.Top reasons why you should start testing Gemini Pro 1.5 today:- 1 million context window! - Allowing it to understand a much greater context than before.
-
Complex multimodality reasoning - It’s able to understand video, audio, code, image, and text.
Vision models are now available
Start using vision models to unlock the even greater potential of Generative AI.Vision models and image models are different. While image models create images, vision models interpret them.We currently support the following vision models:- Claude-3-haiku
- Claude-3-sonnet
- Claude-3-opus
- GPT-4-turbo-vision
- GPT-4-vision-preview
-
Gemini-pro-vision
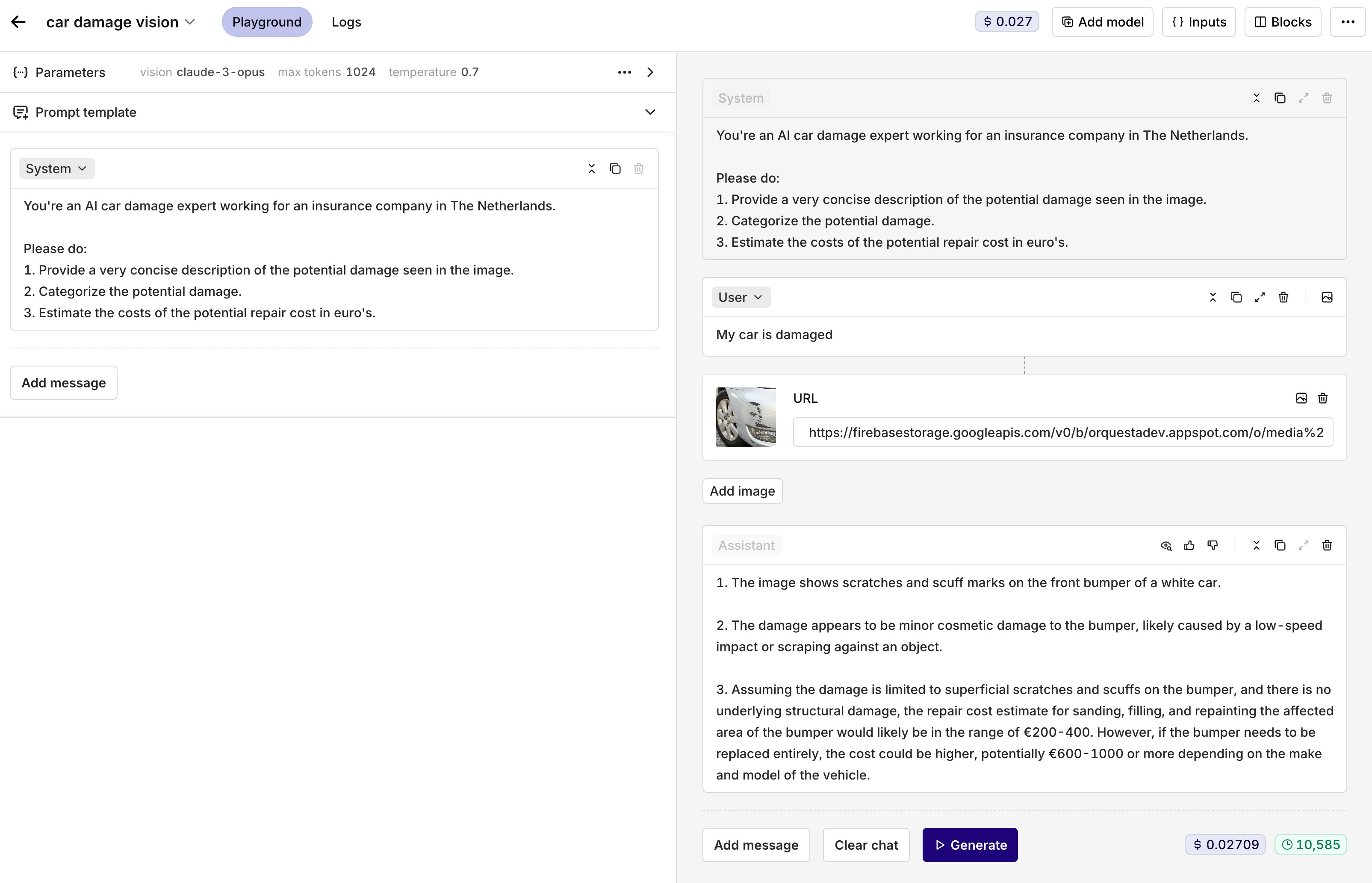
New Cohere models - Command R & Command R+
We now support the latest models from Cohere: Command R & Command R+.Command R is a highly advanced language model designed to facilitate smooth and natural conversations and perform complex tasks requiring long context. It belongs to the “scalable” category of models that provide both high performance and accuracy.The most important key strengths of Command R:- High precision on retrieval augmented generation (RAG) and tool use tasks (function calling)
- Low latency and high throughput
- Large context window 128,000-tokens
-
Multilingual capabilities across 10 key languages, with pre-training data for 13 additional languages
Prompt Studio V2
Today we released the new Prompt Studio V2. Similar to the updated Playground V2, the Prompt Studio is designed for intuitive prompt engineering and consistency across the entire platform.The Prompt Studio can be found when clicking on a variant in the business rules engine. Within the Prompt Studio, you can configure your LLM call. It supports function calling (tools), variable inputs, retries, and fallbacks.Check out the interactive walkthrough below to test it out yourself.

New SDK’s with breaking changes!
🚧 We recently transitioned our SDK's from@orquesta to @orq-ai across all platforms to align with our branding and focus on AI. This includes some breaking changes!
Python SDK
Installation
BeforeUsage
BeforePython
Python
Node SDK
Installation
BeforeUsage
BeforeTypescript
Typescript
Playground V2
Today, we launched our new Playground V2. This updated layout is designed for prompt engineering. By keeping the prompt template separate from the chat messages, it’s easier to fine-tune your prompt. When you clear the chat messages, the prompt template will still be there.Check out our new Playground V2 in the interactive walkthrough below!Claude 3 - Haiku, Sonnet and Opus are now available
With the launch of Claude 3, Anthropic is challenging the status quo. Its most advanced model ‘Opus’ is supposedly better than GPT-4. However, it’s also around 2.5 times more expensive than GPT-4. Haiku, the cheapest and least capable model, is around the same price as GPT-3.5 and is really fast.On another note, none of the Claude models support image and video generation. However, they do have the ability to interpret and analyze images. Moreover, they do have a default context window of 200k tokens, making it useful for larger data sets and variables.The Sonnet and Haiku models are available on Anthropic as well as on AWS Bedrock. Whereas Opus is currently only available on Anthropic.You can toggle them on in the AI Router and try them out yourself!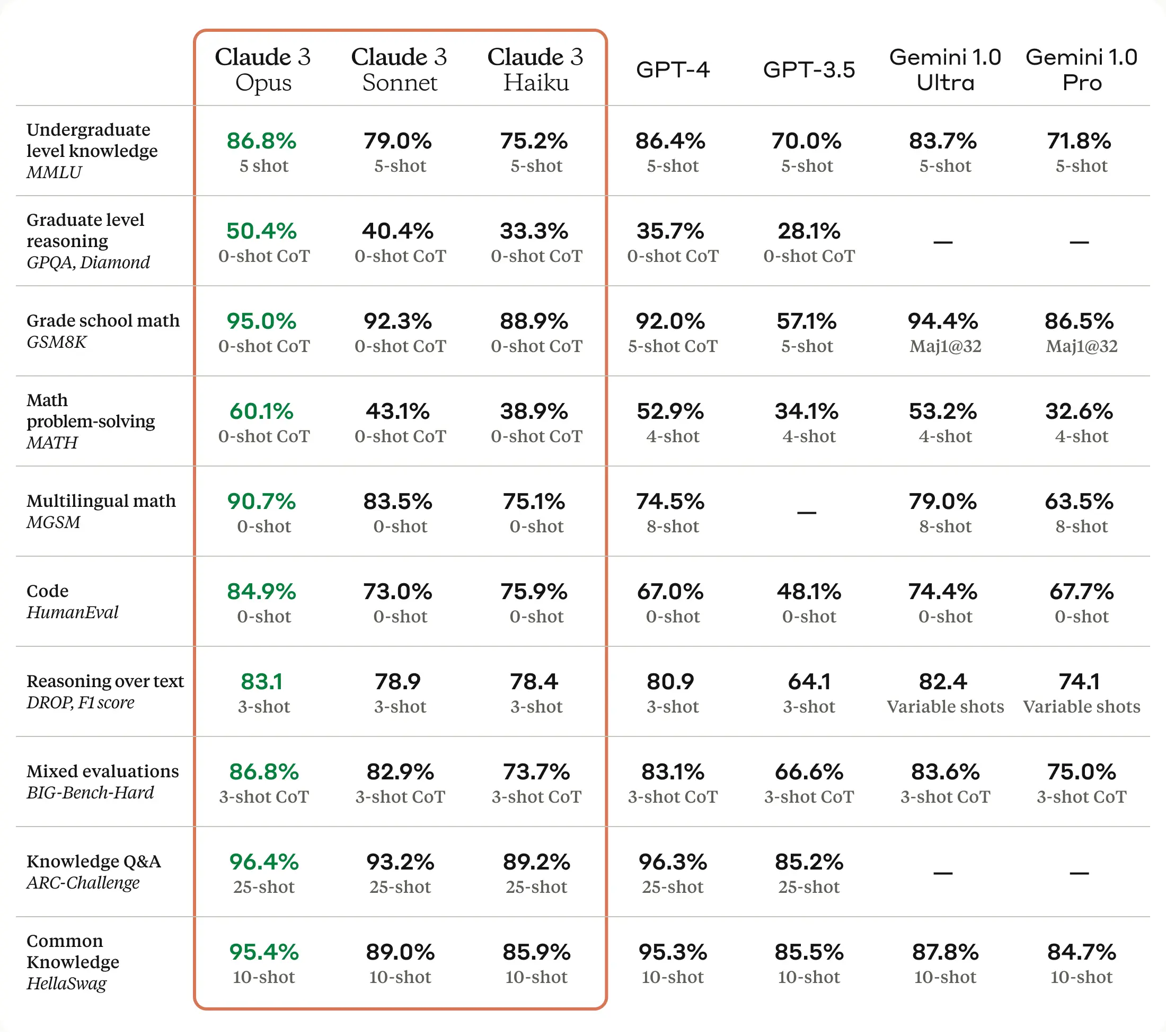
Hyperlinking
With the new Hyperlinking feature, you are able to take your use case from one module to the other. Switching between the Playground, Experiments, and Deployments allows you to make quick iterations throughout the whole platform. Whether you want to take your Playground setup to Experiments or your Deployment to Playground, it’s all possible.Example: You are running a Deployment but want to quickly test out what would happen if you change your prompt. You don’t want to change the prompt within your Deployment because it’s in production. With the new Hyperlinking feature, you can open the exact same configuration used in one module in the other. Follow these steps to try it out yourself:- Navigate towards the Logs tab
- Click on the log that has the configuration that you want to iterate on
- Click on the tree-dotted menu in the upper right corner
- Click open in Playground
- Click on ‘View Playground’
- You’ll be redirected the Playground and see the exact same configuration you are using in your Deployment

Use Groq as your LLM provider
You can now use Groq as your LLM provider. It currently hosts the following models: llama2-70b-chat, mixtral-8x7b-32768, and Gemma-7b-it.What is Groq and why should I try them out?Groq has recently gained a lot of attention for being one of the top companies providing fast LLM inference solutions. There’s a growing need among Gen AI application builders to decrease response times, as lowering latency is key for real-time AI applications. The field is getting crowded, with many companies competing in LLM inference. Groq being one of them, claims to offer inference speeds that are 18 times faster than some well-known cloud-based services. The models hosted by Groq utilize the Groq LPU™ Inference Engine, which is powered by their specialized hardware called Language Processing Units (LPUs) to enhance LLM performance.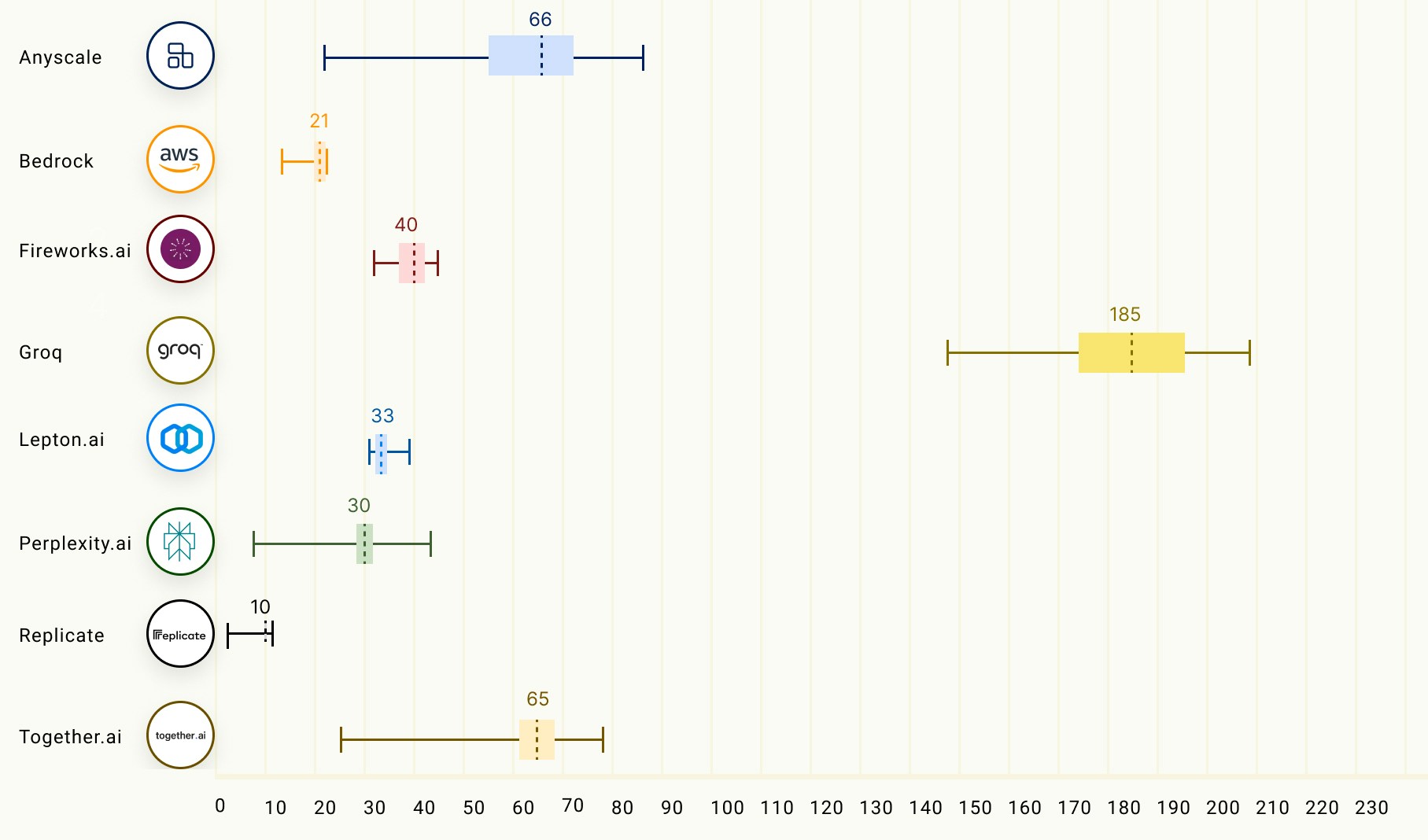
Make your own custom LLM Evaluator
You can now create your own custom LLM evalutator. This allows you to go beyond the standard evaluators like BLEU and Valid JSON.In the example below, we made an evaluator that compares the tone of voice of the generated text against the desired tone in the reference.Read more about Experiments and Evaluators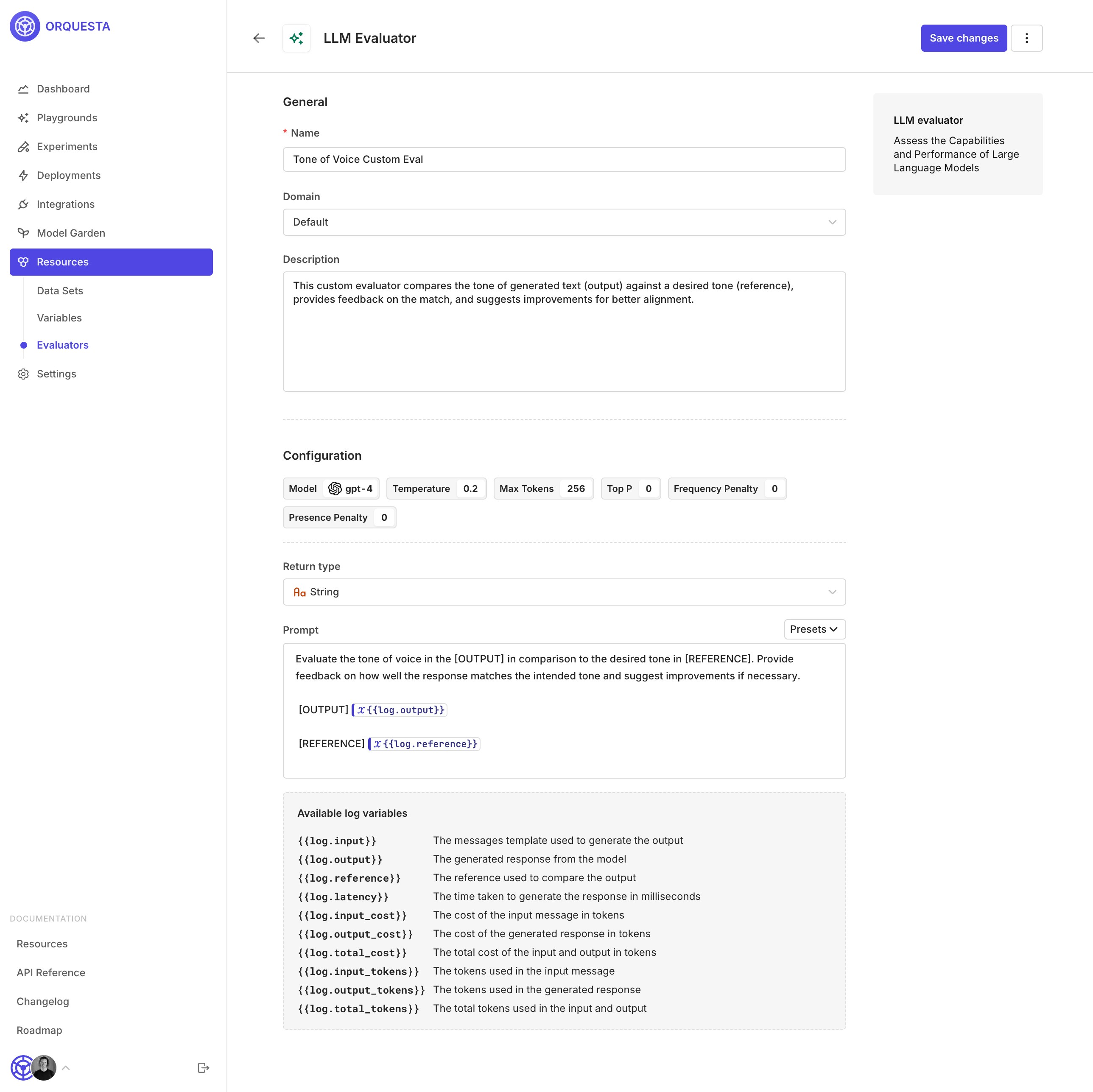
Use LLM as a Reference in Experiments
With this new feature, you’re able to use the output of a large language model like GPT-4 as the reference for another model like Gemma-7b and Mistal-large (see image).For most of the evaluators, you need a reference. This is because an eval like cosine similarity needs two things to compare to each other (the newly generated text and the reference text).Example use case: A new model has been released which is faster and less expensive than the model you are currently using. Although your current model is performing well, you are interested in comparing the performance of the new model. To compare the two models, you have selected your current model (GPT-4) as the reference model in the configuration. This will serve as a benchmark for the new model’s performance. When running the experiment, the reference model will be completed first, and then the output of that model will be used as a reference for the other models. To measure the similarity between the output of the newer models and the reference model, you can use an evaluator such as cosine similarity.
New Providers & Models: Mistral large, Perplexity, Gemma 7b and other models are added
Import from Resources in Experiments
Instead of manually adding your data sets or uploading them through a CSV file in experiments, you can now import them from the files you stored in Resources. This allows you to store and access your files in a quick and efficient manner.
Resource management
Save your data sets, variables, and evaluators in the newly added resources tab.With this new feature, you don’t have to constantly re-upload your resources anymore.Example: After finetuning your prompt, simply save the prompt in the resources tab so you can easily access it during your next workflow.The resources are divided into 3 categories:Data sets - This is where you can store all your prompts and references. Read more about Dataset.Variables - The dynamic elements you put in between curly_brackets are listed here.Evaluators - The standard and custom evals can be stored here. Read more about why you should use evals and when to use which one in Evaluator.
Evaluators are available on our Platform
We have added Evaluators to our platform. With a wide range of industry-standard metrics and other relevant evaluators, you can check whether or not the output of your LLM is accurate, reliable, and contextually relevant.Read more about each evaluator in Evaluators.
Python and Node SDK’s improvements
In our latest SDK update, we’re thrilled to share a series of enhancements that significantly boost the performance and capabilities of our platform.Support for messages in the invoke and stream functionalities
Now you can provide a new property in theinvoke and the invoke with stream methods of both SDKs to combine the messages with the prompt configured in Orquesta.Typescript
- Enhanced Contextual Clarity: The use of chat history empowers the model to preserve the context throughout a conversation. This feature ensures that each response is not only coherent but also directly relevant, as the model can draw upon past dialogues to fully grasp the nuances of the current inquiry or discussion topic.
- Streamlined Conversation Flow: Chat history is instrumental in maintaining a consistent and logical flow in conversations. This prevents the occurrence of repetitive or conflicting responses, mirroring the natural progression of human dialogues and maintaining conversational integrity.
- Tailored User Interactions: With access to previous interactions, chat history allows the model to customize its responses according to individual user preferences and historical queries. This level of personalization significantly boosts user engagement and satisfaction, leading to more effective and enjoyable communication experiences.
Support for messages and choices to add metrics
In Orquesta, after every request, you can add custom metrics. On top of the superset that we already support, we also added two new properties,messages and choices. The messages property is designed to log the communication exchange between the user and the model, capturing the entire conversation history for context and analysis. Meanwhile, the choices property records the different response options that the model considers or generates before presenting the final output, providing insights into the model’s decision-making process.Typescript
Support for OpenAI system fingerprint
To help track OpenAI environmental or model changes, OpenAI is exposing asystem_fingerprint parameter and value. If this value changes, different outputs will be generated due to changes to the OpenAI environment.In the new version of the SDK, if you are using an OpenAI model and the invoke method, the system_fingerprint will be exposed in the deployment properties.Setup your own API key with the new AnyScale integration.
You could already select models such as Llama from Meta and Mixtral from Mistral in the AI Router. But with this release, it is now possible to connect your own API key for AnyScale. This way you can use your own account and rate limits without having to rely on a shared key. Soon you’ll be able to use your own private models and finetuning on AnyScale.
Mass Experimentation
You could already test out different models and configurations using our playground. However, with the introduction of Experiments, you are able to do this on a much larger scale.Simply import your prompts, expected outputs, and variables, configure your model, and you’re able to do hundreds of simultaneous runs. This allows you to do a side-by-side comparison in large batches.Check out the interactive walkthrough.Python and Node SDK’s now support multimodality
We improved our SDKs to support more types of models. Now, it’s possible to use completion, chat, and image models through our unified API.We also improved our API reference here to offer a better DX.Python SDKhttps://pypi.org/project/orquesta-sdk/Node SDKhttps://www.npmjs.com/package/@orq-ai/nodeFunction calling supported in the Playground
For a better UX on Orquesta, we improve how to handle function calling in the Playground and the Prompt Studio.Now you can simply enter your function name, description, and parameters with the JSON schema format.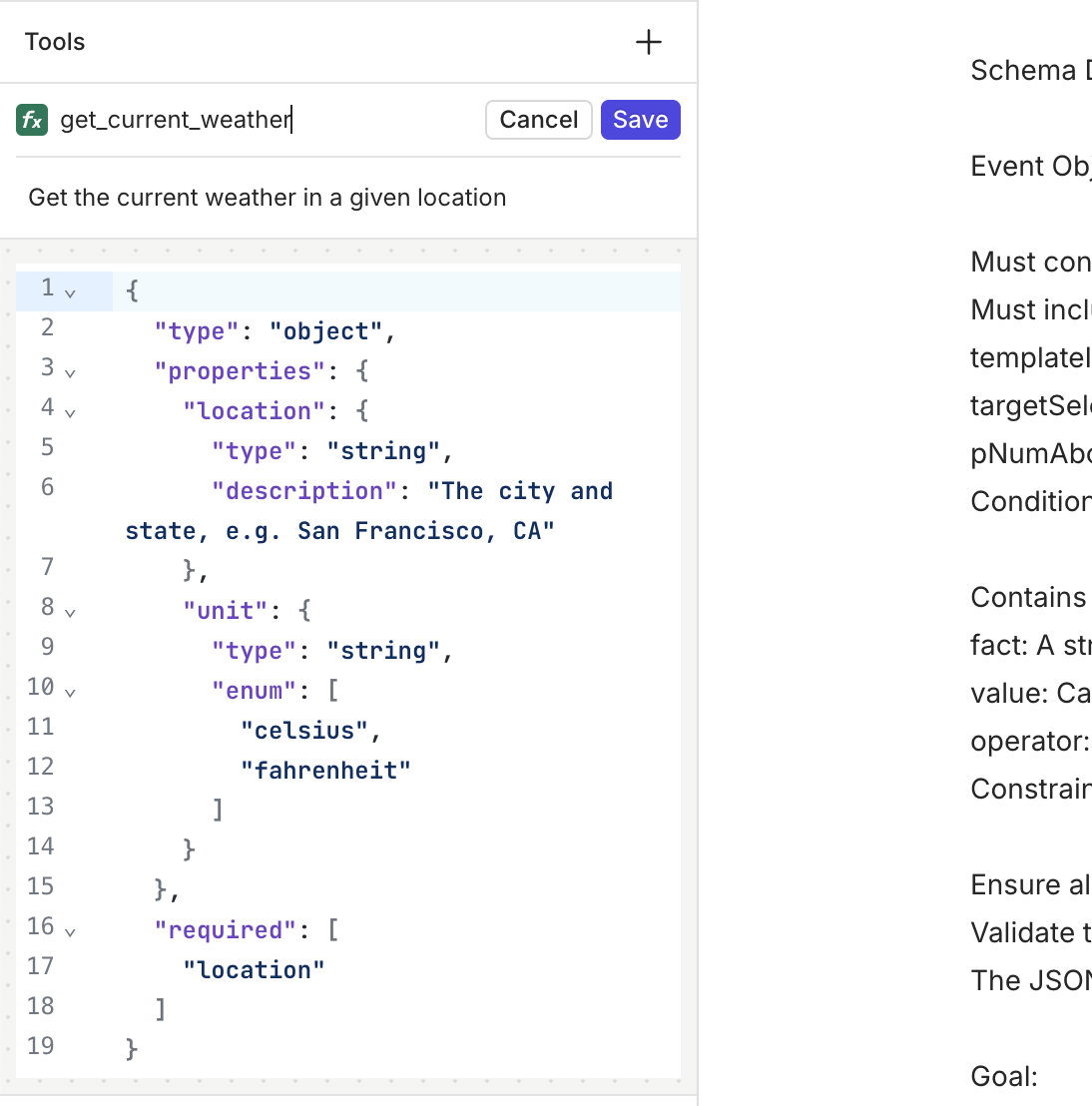
Billable transactions are now shown in the log details
Now, it is possible to see in the log details if the request to the LLM was executed with Orquesta API keys or your API keys.Gemini, Google’s most capable model, now available on Orquesta
Now, using Gemini Pro on Orquesta through the Playground and Deployments is possible. This model also supports function calling.Log and metrics enhancement
We introduced a new log detail drawer for a better and more segmented data structure. This will allow our users to consume the information more easily.Chat history now available in the playground
If you are using the Playground, you can now utilize Playground memory. This feature enables you to add historical context when comparing different models simultaneously.For completion models, we strive to incorporate historical context, but this may occasionally lead to undesired effects in the final completions. If you encounter such issues, we recommend disabling Playground memory.Support for Dall-E models
Added support for Dall-E models in the Playground and Deployments for OpenAI and Azure.
orq.ai Integrations
We added a new Integrations section to allow the use of your API keys. At the moment, we support custom API keys from the following LLM providers- OpenAI
- Azure
- Cohere

Reset models default parameter in a Deployment
Now, it is possible to reset the parameters of the primary model and the fallback model in a Deployment.AWS Bedrock models available
Recently, we’ve expanded our platform’s capabilities by adding AWS Bedrock models. You can now explore these models in the Playground or integrate them into your deployments.Models- anthropic/claude-2
- anthropic/claude
- anthropic/claude-instant
- a21labs/jurassic-2-ultra
- a21labs/jurassic-2-mid
- amazon/titan-text-lite
- amazon/titan-text-express
- cohere/command
- anthropic/claude-2.1
-
cohere/command-light