

The studio has a rebuilt sidebar that puts the active project at the center of navigation. Every entity list, search, and create flow is now scoped to the project being worked in, so switching context no longer means scrolling past everything in the workspace.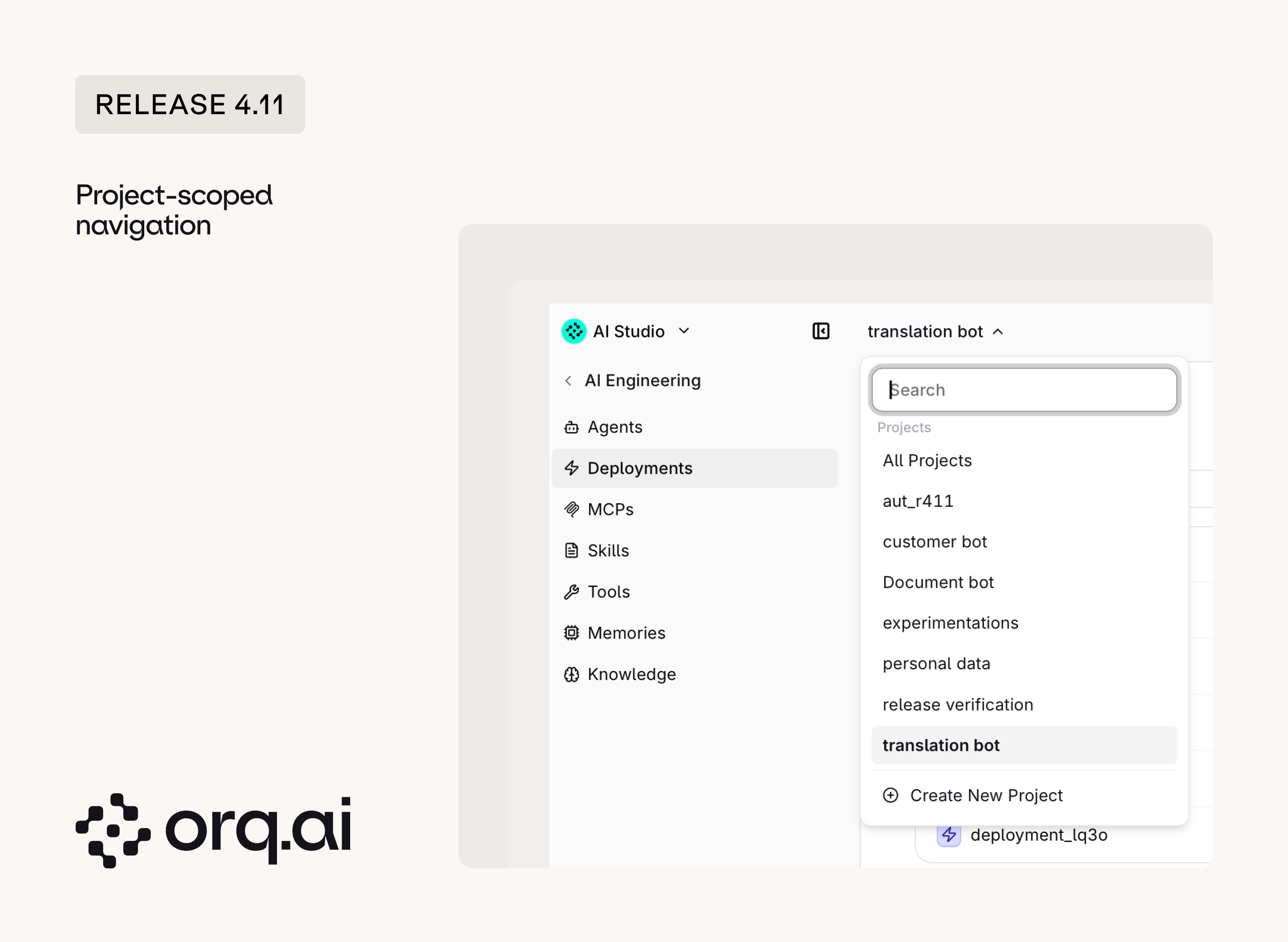
- Five-section sidebar: A collapsible sidebar groups the product into five sections, with drill-in navigation into each entity area.
- Project scope everywhere: Knowledge Bases, Memory Stores, Tools, MCPs, and API Keys tables filter to the selected project, with an All Projects view to accommodate existing customers’ way of working.
- Consistent entity tables: Every entity list adopts one table pattern with matching search and filters.
Existing customers can enable the new project view from Feature Preview in their profile.
Budgets are now a first-class entity in Orq.ai. Set cost, token, or rate limits on any part of the workspace, track live consumption, and stop traffic automatically once a limit is reached. Only Admins can create and edit Budgets.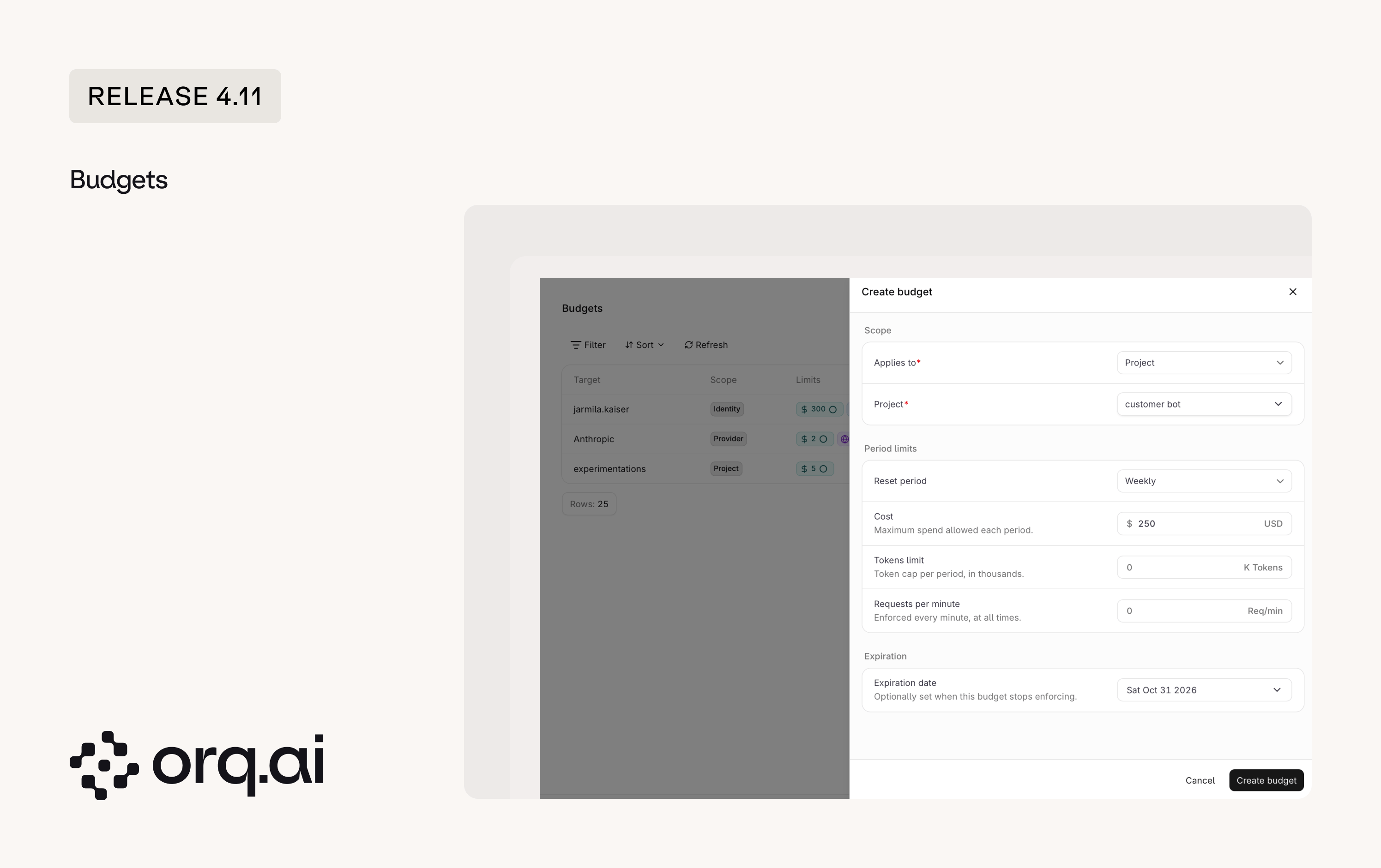
- Six scopes: Attach a budget to a workspace, project, Identity, API key, provider, or model.
- Three limit types: Cap by cost in USD, token count, or requests per minute. Set one or combine them.
- Reset periods: Reset daily, weekly, monthly, or yearly, or set a one-time lifetime cap.
- Expiration date: Optionally set an expiry, after which the budget no longer applies.
- Consumption visibility: Every budget shows live usage and utilization, with status icons on the limit pills and a cost metrics tooltip.
- Budgets API: Create, list, update, and delete budgets programmatically at
/v2/budgets, automated with the new Management API keys. - Available in both products: Budgets are available in both AI Studio and AI Gateway under Settings.
Manage budgets from the UI or the API. See the Budgets guide.
Orq.ai can now redact personally identifiable information before requests reach the provider, then restore the original values in the response returned to the caller. Redaction runs as a request-scoped plugin on the router endpoints, so the provider only ever sees placeholders while the caller still gets the real values back.
- PII redaction: Detected PII is replaced with placeholders before the provider sees it, and the original values are restored on the way back.
- v3 router endpoints: Runs across the v3 router endpoints.
/v3/router/responses,/v3/router/chat/completions, and/v3/router/completionsredact and restore text;/v3/router/embeddings,/v3/router/rerank, and/v3/router/images/generationsredact the input. - Where it applies: Available for direct router requests and Agents today.
- Workspace and request level: Admins can enforce PII redaction at the workspace level. Request-level redaction is also supported and can be equally or more strict than the workspace setting.
Set up PII redaction and see how it aligns with data compliance in the PII redaction guide.
A new class of organization-level API keys manages workspace configuration, separate from the data-plane keys used to call models and Agents. Automate setup and governance without minting keys that can touch production traffic.
- Management API keys: Organization-level keys for configuration management, kept separate from data-plane keys.
- Scoped and governed: Keys can be scoped to API key and Budget creation. Restricted to the Admin role in both the UI and the API.
Create and scope keys in the Management API keys guide.
- Enterprise SSO, provider-agnostic: Enterprise SSO now supports both OIDC and SAML across the UI and API.
- Memories: A new UI for creating and managing memories in Memory Stores.
- Annotations: Human Review is now Annotations, with its own sidebar menu and table view. Add annotations in the annotation queue, in Experiments, through the API, or directly on Traces.
- Broader framework tracing: Tracing audits and improvements landed for CrewAI, OpenAI Agents, LangGraph, LangChain, Mastra, Pydantic AI, and LlamaIndex.
- MCP setup timing in Traces: MCP connection and tool-discovery calls now appear as their own spans in the Traces timeline, so slow runs caused by MCP overhead are easy to spot.
- Incremental streaming on the gateway: The AI Router supports incremental streaming for lower time-to-first-token.
- Traces tool and eval output: Tool responses render correctly, Python Evaluator output renders on the Trace, and Skills used as snippets now appear in Logs and Traces.
- Webhooks redesign: Webhooks move to a rebuilt UI with optimistic updates and are now available in AI Gateway settings.
- Threads in Traces: A navigable thread-view sidebar in Traces makes it easier to step through multi-turn conversations.
- Provider-level context caching: Context caching is applied at the provider level for supported providers on the Responses API, cutting cost and latency on repeated context.
- Multi-region and JSON support: Multi-region Gemini endpoints are supported, and Cerebras models gain JSON mode.
- OpenAI image generation streaming: Streamed responses are supported for OpenAI image generation.
New additions to the Model Garden across Anthropic, AWS Bedrock, Google Vertex, Google AI, Moonshot AI, and Z.ai. Browse details on the Supported Models page.
- Tool-level cache_control: The Responses API no longer silently ignores tool-level
cache_control, so provider caching applies as configured. - Tool responses in Traces: Tool responses now render reliably in the Traces view.
- Automations spans: Spans from automations are no longer dropped from the queue or datasets.
- Reasoning effort on API-created Agents: Reasoning effort set on Agents pre-created through the Responses API is now kept when the agent runs.
- Versioned custom tools: Agents with custom tools invoked by a specific version label no longer fail.
- SDK response consistency: Several v2 SDK read paths now return consistent, correctly typed responses, fixing validation errors across datasets, datapoints, files, skills, projects, and evaluator versions.
- Experiments stability: Cosine similarity and Evaluator runs no longer get stuck, and skill-variable, Knowledge Base, and model-column errors in the compare screen are fixed.
The v2 Agent endpoints are being retired. Migrate to the v3 Agents API to keep integrations running once v2 is switched off.
- Affected endpoints:
/v2/agents/{key}/responses,/v2/agents/{key}/task,/v2/agents/run,/v2/agents/stream-run, and/v2/agents/{key}/stream-task. - Why v3: The v3 Agents API is OpenAI SDK compatible and built on the
/v1/responsesendpoint, with cleaner run and streaming semantics. Built with learnings from v2 and rewritten in Go for better performance. - Migrate early: Move to v3 to avoid interruptions once v2 is switched off.
Reach out to support@orq.ai for help mapping current v2 calls to v3.