






Introduction
orq.ai exposes an API to manipulate Evaluators. These APIs are used to manage Evaluators programmatically. In this page we’ll see the common use cases for creating, and fetching Evaluators through the API.Prerequisite
To get started, an API key is needed to use within SDKs or HTTP API.To get an API key ready, see Authentication.
SDKs
Node.js
Python
Creating an Evaluator
To create an Evaluator we’ll use the Create an Evaluator API call. We then need to decide what type of Evaluator we’ll create:HTTP Evaluator
Here is a valid payload to create an HTTP evaluator:To learn more about building HTTP Evaluators, see Creating an HTTP Evaluator.
JSON Evaluator
Here is a valid payload to create a JSON evaluator:Make sure to correctly escape the JSON Schema payload.
To learn more about building JSON Evaluators, see Creating a JSON Evaluator.
LLM Evaluator
Here is a valid payload to create an LLM evaluator:To learn more about building LLM Evaluators, see Creating an LLM Evaluator.
Python Evaluator
Here’s a valid Python Evaluator:
Use \n to indicate newlines in code.
To learn more about building Python Evaluators, see Creating a Python Evaluator.
Guardrail Configuration
For each Evaluator payload you can also define a guardrail payload looking as follows and add it into the creation payloadCalling the API
Here’s an example end-to-end API call and response:Listing Evaluators
To list evaluators we’re using the Listing Evaluators API. We’re making the following call:Using Evaluators
Calling an Evaluator from the Library
We’ll be calling the Tone of Voice endpoint: Here is an example call:The query defines the way the evaluator runs on the given output.
The value here holds result of the evaluator call following the query
Calling a custom evaluator
It is also possible to call a custom-made Evaluator made on orq using the API. You can fetch the Evaluator ID to send to this call by searching for Evaluators using the Get all Evaluators API. Then you can run the following API call: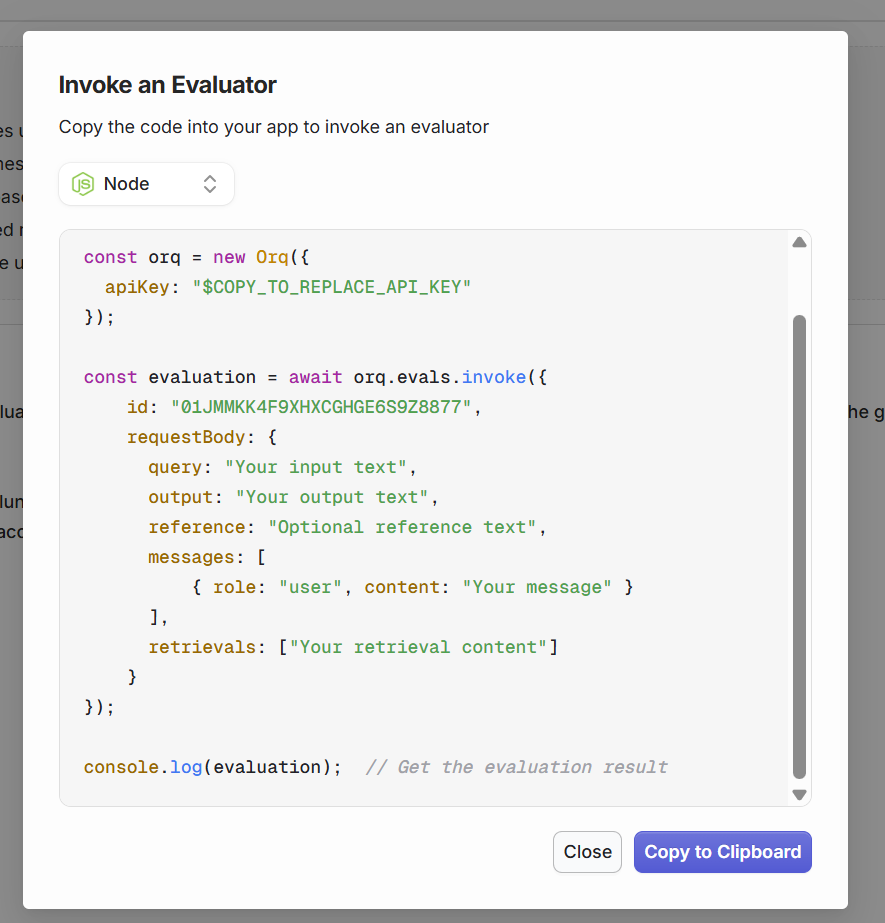
Guardrail Error Response
When a guardrail blocks a generation in a Deployment or Agent, Orq.ai returns an HTTP422 Unprocessable Entity. The following payloads are returned.
- Deployments
- Agents
| Field | Type | Description |
|---|---|---|
id | string | Internal ID of the guardrail result. |
status | string | Execution status of the guardrail: "completed" or "failed". |
started_at | string | ISO 8601 timestamp when the guardrail evaluation started. |
finished_at | string | ISO 8601 timestamp when the guardrail evaluation finished. |
related_entities | array | References to the evaluator that ran as this guardrail. Each entry contains type, evaluator_id, and evaluator_metric_name. |
passed | boolean | false for every entry in this error response, as the guardrail’s condition was not met. For example: a boolean guardrail configured to pass on true returns passed: false when the evaluator returns false. |
reason | string or null | Explanation of the failure, when provided by the evaluator. |
evaluator_type | string | "input_guardrail" if the guardrail ran before the model (request rejected before generation). "output_guardrail" if the guardrail ran after generation (response withheld). |
type | string | The value type returned by the evaluator: "boolean" or "number". |
value | boolean or number | The raw value returned by the evaluator. |
When the evaluator fails to execute: If the evaluator itself fails to run (for example, a network error contacting an external HTTP evaluator or a timeout), the guardrail is silently skipped and the generation proceeds. A broken evaluator does not block your users. Monitor skipped guardrail executions through Traces in the Orq.ai Studio.When an LLM guardrail’s underlying model fails: If the model powering an LLM guardrail is unavailable, Orq.ai fails the entire request for safety. Since the guardrail could not run, there is no way to know whether it would have blocked the generation, so Orq.ai errs on the side of caution.
Using EvaluatorQ
EvaluatorQ is a dedicated SDK for using Evaluators within your application. It features the following capabilities:- Parallel Execution: Run multiple evaluation jobs concurrently with progress tracking
- Flexible Data Sources: Support for inline data, promises, and Orq platform datasets
- Type-safe: Fully written in TypeScript
Learn more, see the Python EvaluatorQ and TypeScript EvaluatorQ repositories.