

Image Generation: Creating Images from Text
Image Generation models can create images based on text descriptions. These models are perfect for creative tasks, content generation, and visual prototyping.Selecting an Image Generation Model
To select a model that is compatible with Image Generation, use a model that has animage tag next to its name:
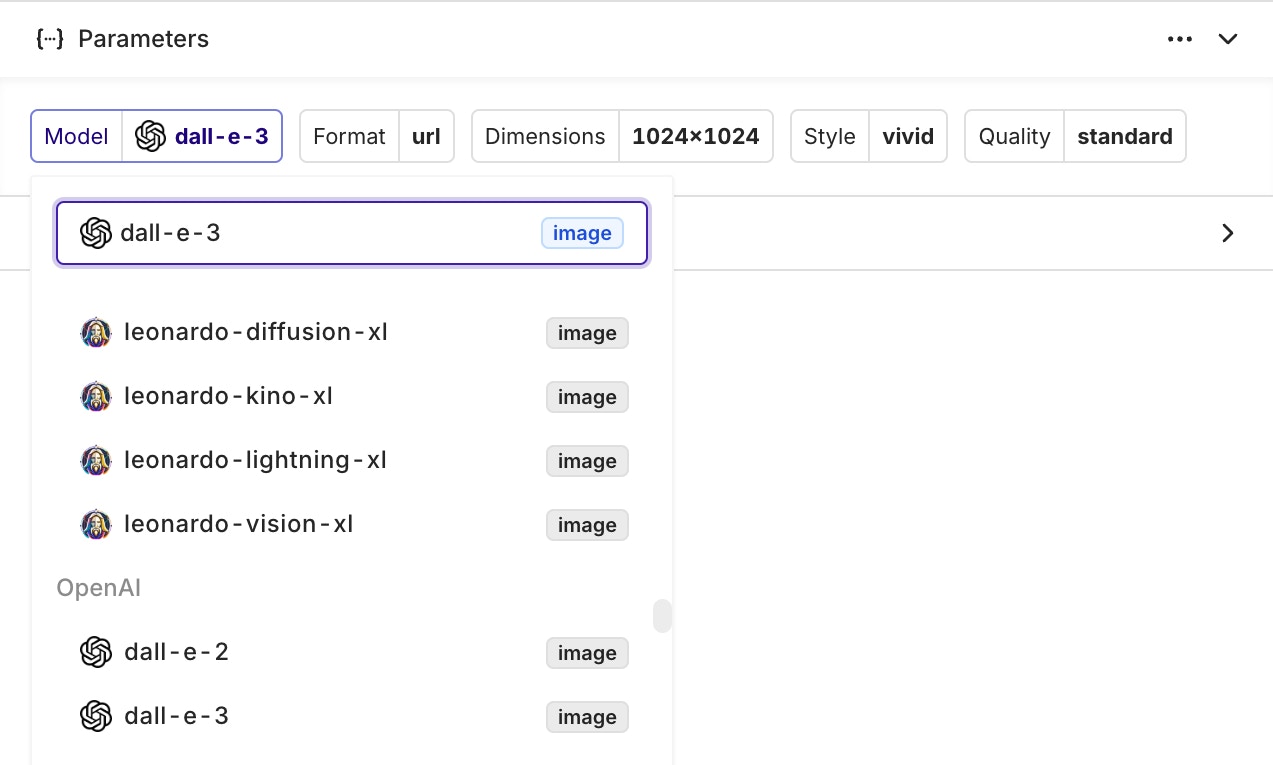
imageThe Image Generation tag means that the model is capable of generating images
Configuring Parameters for Image Models
Image Generation models have different parameters compared to chat models. The parameters will be different for each image model and will impact the generated images.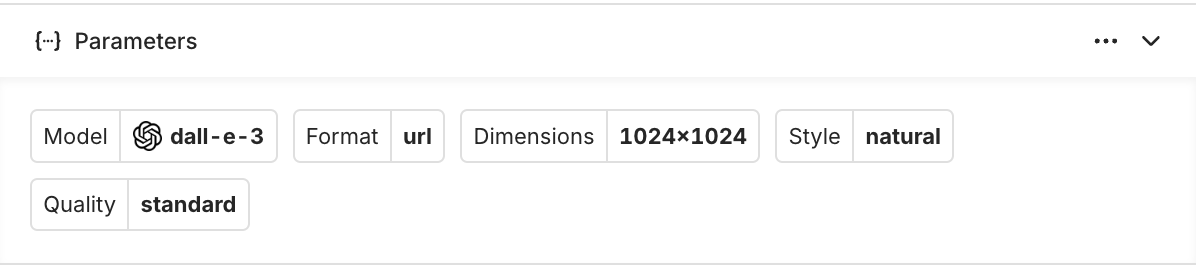
dall-e-3Example of parameters for the DALL-E 3 Image Generation model.
Using Image Generation in Playground
You can use image models just like any other model in the Playground. The generated images will appear as regular messages. You can click on the image to see it on fullscreen or in a new tab.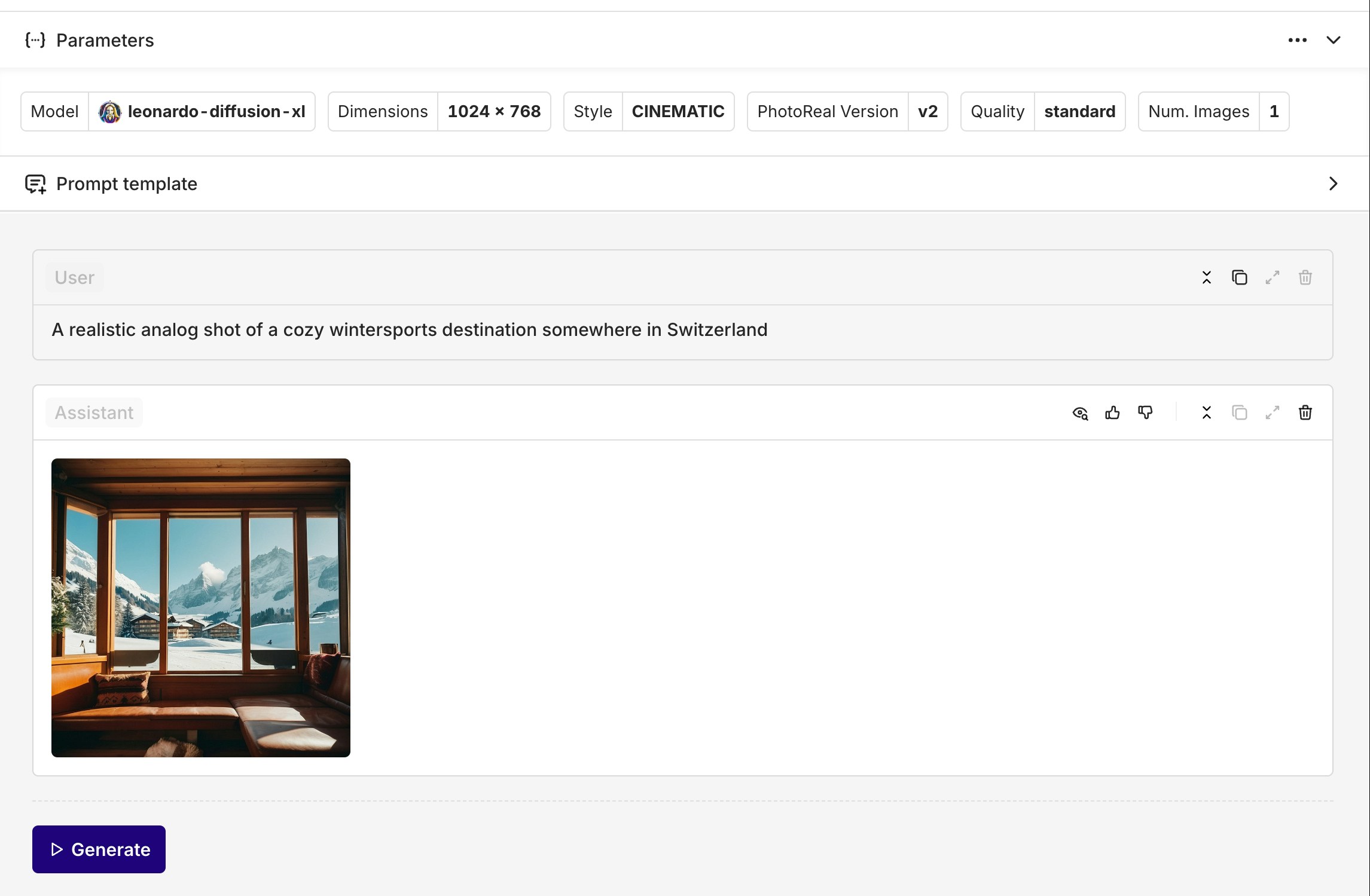
Example of an image generation using Leonardo AI
Use Cases
- Creative Content: Generate artwork, illustrations, and visual content for marketing materials
- Product Design: Create mockups and visual prototypes based on descriptions
- Content Creation: Generate images for blogs, social media, and presentations
- Concept Visualization: Turn abstract ideas into visual representations
Best Practices
- Be Specific: Provide detailed descriptions for better results
- Style Guidelines: Include artistic style, mood, and visual elements in your prompts
- Parameter Tuning: Experiment with model-specific parameters to achieve desired output quality
- Iterative Refinement: Use generated images as starting points for further refinement
Vision: Analyzing and Interpreting Images
Vision models can analyze, interpret, and understand images that you provide. These models are ideal for image analysis, document processing, visual question answering, and content moderation.Selecting a Vision Model
To select a model that is compatible with Vision, use a model that has avision tag next to its name:
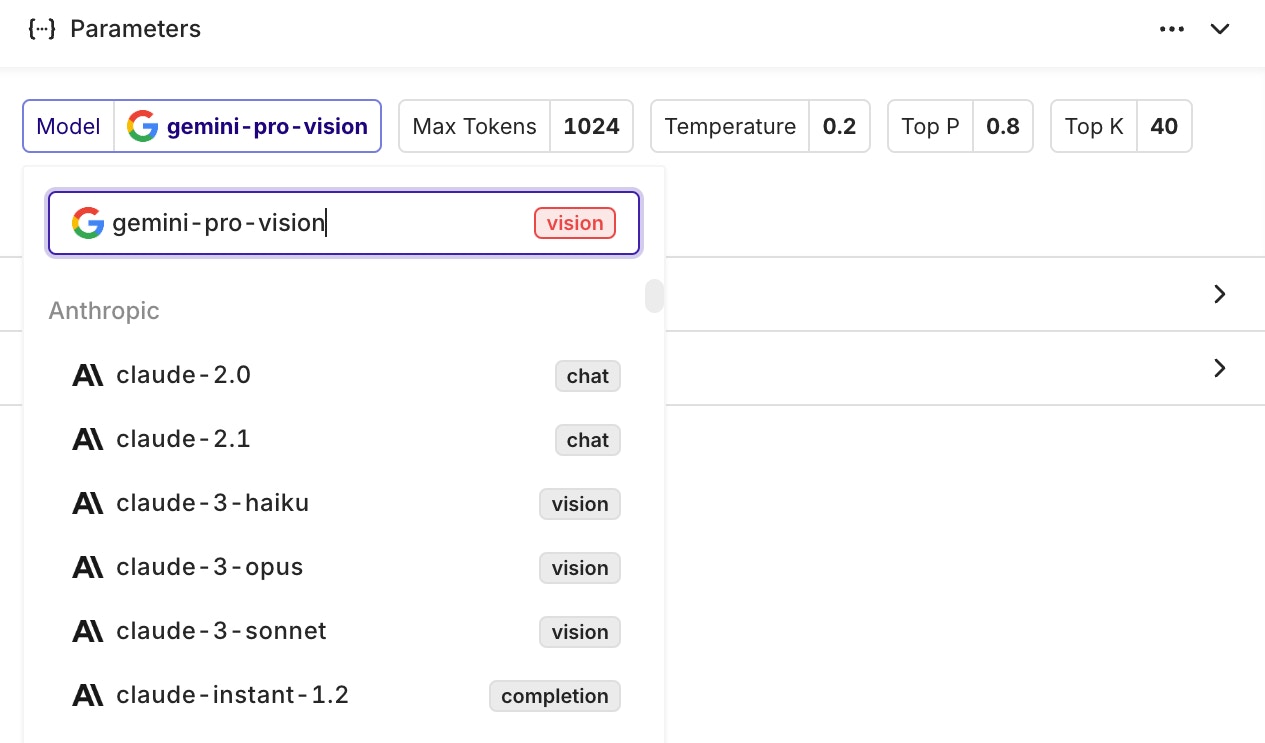
visionThe Vision label means that the model is able to interpret images
Using Vision in the Playground
You can use Vision models just like any other model in the Playground. To include an image as an input for your model, click on the image icon at the top-right of your message. You will then be able to share a link or upload an image to be sent to the model.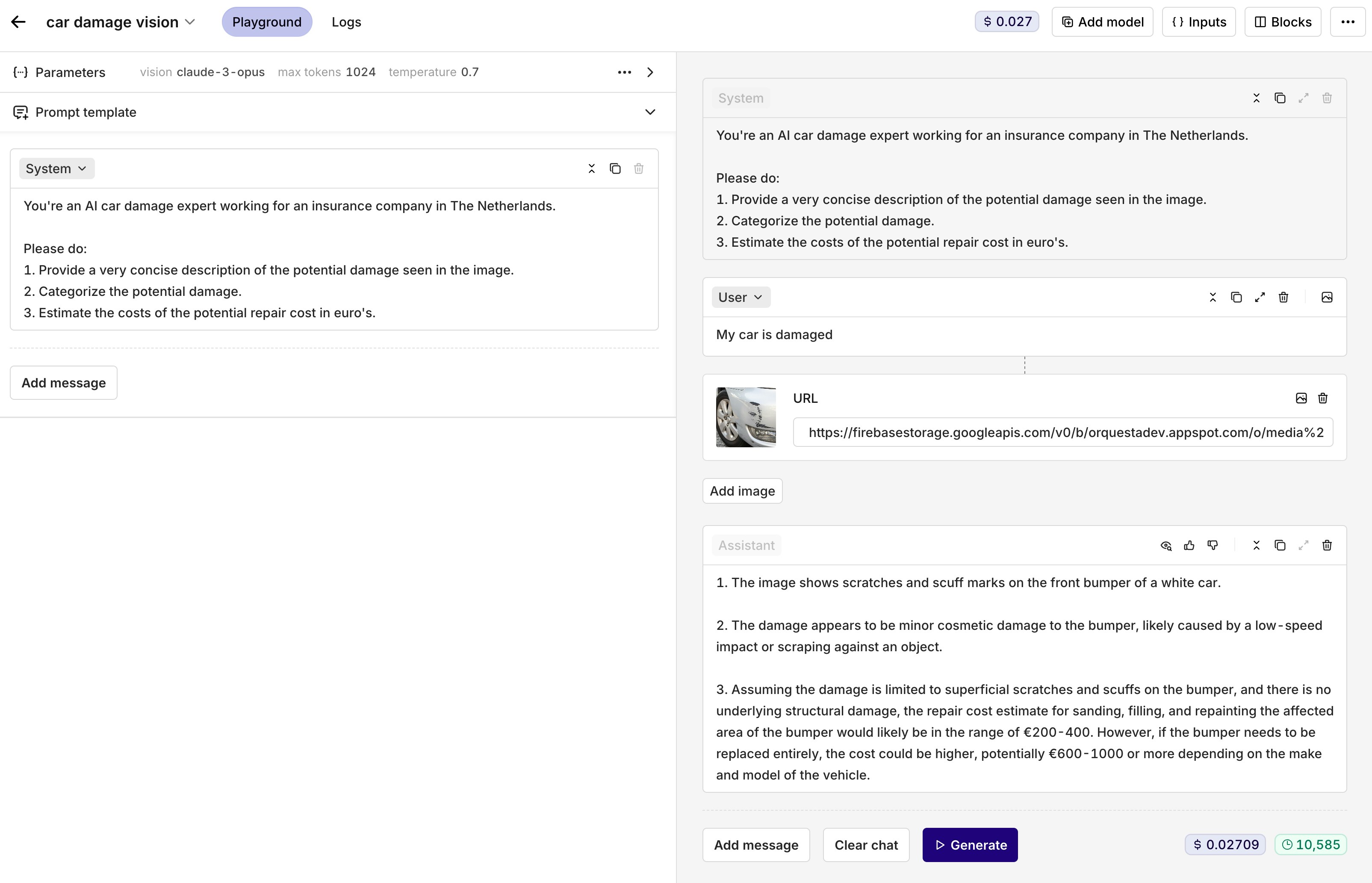
An example use case using a vision model
Use Cases
- Document Processing: Extract text and information from scanned documents and forms
- Visual Quality Control: Analyze product images for defects or compliance
- Content Moderation: Automatically review images for inappropriate content
- Medical Imaging: Analyze medical scans and diagnostic images (with appropriate models)
- Insurance Claims: Process damage assessment photos and documentation
Best Practices
- Image Quality: Ensure images are clear and well-lit for best analysis results
- Specific Questions: Ask focused questions about what you want to extract or understand
- Context Provision: Provide context about what the image represents for better interpretation
- Multiple Angles: For complex analysis, consider providing multiple views of the same subject