






POST request to your server whenever those events occur, with no polling required.
Setting Up a Webhook
Navigate to Organization and select Webhooks. Click Create and configure the following:- Name: a unique name to identify this webhook
- URL: the endpoint on your server that will receive the HTTP POST requests
- Event types: choose which events should trigger this webhook
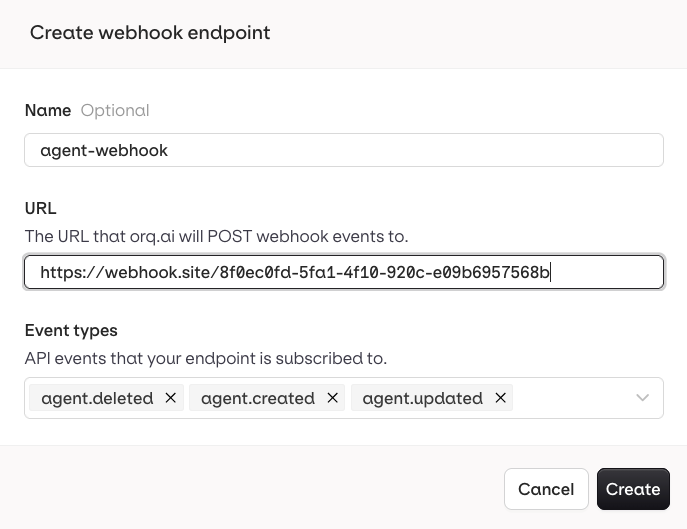
- Send me everything to receive events from all deployments
- Let me select individual deployments to scope the webhook to specific ones.
Event Types
Orq.ai sends webhooks for the following events, grouped by resource:| Group | Event |
|---|---|
| Agent | agent.created |
agent.updated | |
agent.deleted | |
| Deployment | deployment.created |
deployment.updated | |
deployment.deleted | |
deployment.invoked | |
| Prompt | prompt.created |
prompt.updated | |
prompt.deleted |
Delivery Metrics
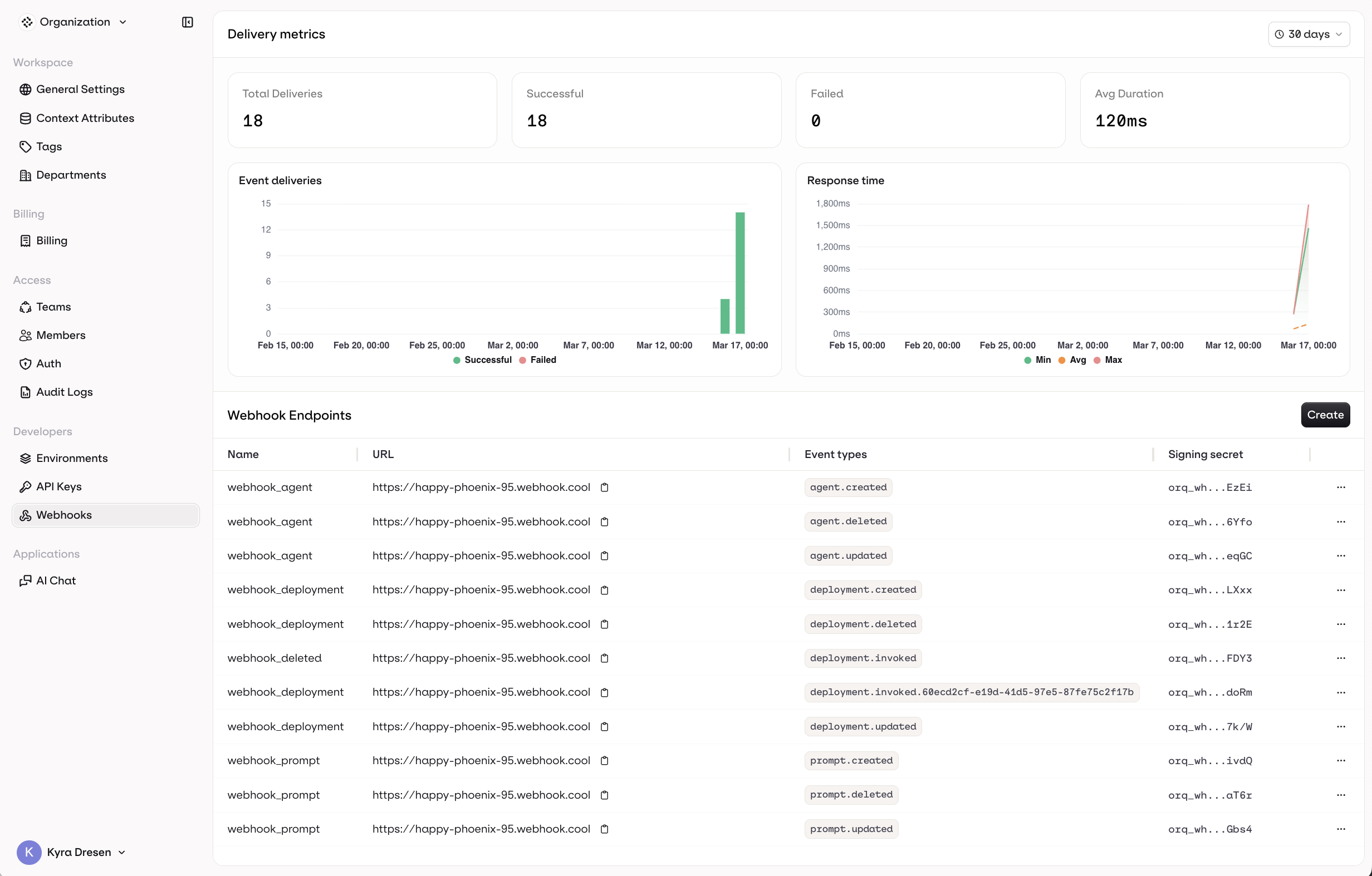
- Total Deliveries, Successful, Failed, and Avg Duration over a configurable time range
- An Event deliveries chart showing successful vs. failed deliveries over time
- A Response time chart showing min, avg, and max response times
Payload Structure
All CRUD events share the same envelope.request_id is an optional string that identifies the originating API request. It is present when the event was triggered by a traceable API call, and absent for system-initiated events.
Agent
agent.created
agent.created
agent.updated
agent.updated
agent.deleted
agent.deleted
Deployment
deployment.created
deployment.created
deployment.updated
deployment.updated
deployment.deleted
deployment.deleted
deployment.invoked
deployment.invoked
Unlike CRUD events,
deployment.invoked does not include workspace, project, api_version, or correlation_id. Deployment metadata is provided in a top-level metadata block instead of a nested object.status is always present. It contains the HTTP status code returned by the upstream model provider (e.g. 200, 429, 500), useful for detecting partial failures without inspecting the full response.Several other fields are conditional and may be absent depending on the invocation:contact_id: present when an Identity is linked to the requestbilling: omitted when the response was served from cachecache_status,cache_key,cache_config: present on cached responsesevals: present when Evaluators are configured on the deploymentthread: present when the invocation is part of a thread
Prompt
prompt.created
prompt.created
prompt.updated
prompt.updated
prompt.deleted
prompt.deleted
Best Practices
- Use HTTPS: always use HTTPS for your webhook URL to ensure payloads are transmitted securely.
- Verify signatures: validate the
X-Orq-Signatureheader on every request before processing the payload. - Respond quickly: acknowledge receipt immediately with a
200response. Offload any heavy processing to a background job. - Handle retries: if your endpoint is temporarily unavailable, Orq.ai may retry delivery. Make your handler idempotent using the event
idto avoid processing the same event twice. - Monitor delivery: use the Delivery Metrics dashboard to track failures and response times.
Security
Every webhook request includes a signature you should verify before processing the payload.Headers
| Header | Description |
|---|---|
X-Orq-Signature | HMAC-SHA256 hex digest of the signature payload |
X-Orq-Hook-ID | The event ID |
X-Orq-Event | The event type |
User-Agent | Orq-Webhook/2.0 |
How the signature is computed
The signature is computed over a JSON string containing exactly these three fields in this order. The type ofcreated differs by event: an integer (Unix timestamp) for CRUD events, and an ISO-8601 string for deployment.invoked. The value must be preserved as-is from the original payload without type conversion.
CRUD events:
deployment.invoked: