

LLM Evaluator
Use a model to judge outputs against any criteria you define in a prompt.
Python Evaluator
Write custom Python code for full flexibility. Use for statistical scoring, regex checks, length validation, or any custom evaluation logic.
HTTP and JSON evaluators are deprecated. Existing HTTP and JSON evaluators continue to work, but cannot be duplicated. Use Python evaluators instead: the
requests package is now available for HTTP calls, and pydantic is available for JSON schema validation.Use Cases
Automated quality scoring
Automated quality scoring
Score model outputs on dimensions like tone, accuracy, or relevance without manual review. Use LLM-as-a-Judge evaluators with custom rubrics, or import pre-built scoring functions from the Hub.
Output compliance checks
Output compliance checks
Verify that outputs meet specific format, content, or structural requirements. Use Python evaluators for custom logic such as regex checks, length validation, or structural assertions.
Guardrails in Deployments and Agents
Guardrails in Deployments and Agents
Attach evaluators as guardrails to block generations that fail a pass condition. Input guardrails run before the model; output guardrails run after. A failed guardrail returns HTTP 422 to the caller.
Regression testing in Experiments
Regression testing in Experiments
Run evaluators across a full dataset in an Experiment to track quality over time. Compare evaluator scores across runs and prompt variants to catch regressions before deploying changes.
Pre-built Evaluators
Before building one from scratch, browse the Hub for ready-to-use evaluators. Add any of them to a Project with the Add to project button, then use them in Experiments, Deployments, and Agents. The Hub groups its evaluators into three categories:- Function Evaluators: deterministic checks such as Contains, Valid JSON, Length Between, and BLEU Score.
- LLM Evaluators: model-judged checks such as Tone of Voice, Grammar, PII, and Sentiment Classification.
- RAGAS Evaluators: retrieval-augmented generation metrics such as Faithfulness, Context Precision, and Response Relevancy.
LLM Evaluator
LLM Evaluators use a model to judge outputs against any criteria you define in a prompt. AI Studio
AI Studio- API & SDK
 MCP
MCP
In a Project or folder, click the button and select LLM Evaluator. Select the model to use for evaluation. It must be enabled in the AI Gateway.
Configure Prompt
- AI Studio
Your prompt has access to the following string variables:
{{log.input}}: the last message sent to the model{{log.output}}: the output response generated by the evaluated model{{log.messages}}: all messages sent to the model, excluding the last message{{log.retrievals}}: Knowledge Base retrievals{{log.reference}}: the reference used to compare output
Model Parameters
- AI Studio
The Model field selects which model acts as judge. Any model enabled in the AI Gateway is available. The model choice affects evaluation quality, cost, and latency.
Output and Guardrail Configuration
- AI Studio
Select the output type that matches the evaluation criteria. The Guardrail configuration panel is visible directly in the evaluator settings. Set the pass condition for each type:Once configured, the evaluator is available as a guardrail in any Deployment or Agent without any additional toggle.
- Boolean
- Number
- Categorical
- String
The model returns a True or False response. Use for binary pass/fail checks.Guardrail: Select True or False. The guardrail passes when the model returns the selected value.
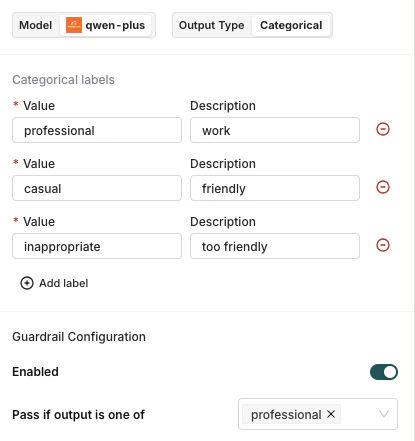
Examples
- AI Studio
Evaluating formality on a 1-5 scale
Evaluating formality on a 1-5 scale
Evaluating accuracy on a 0-100 scale
Evaluating accuracy on a 0-100 scale
Binary pass/fail with numeric output
Binary pass/fail with numeric output
Consistency with the prior conversation
Consistency with the prior conversation
Comparing output against a reference
Comparing output against a reference
Validating tool usage
Validating tool usage
Testing
- AI Studio
- Editor
- Dataset
Fill the payload manually. Enter values for 

messages, input, output, retrievals, and reference. All prompt variables resolve against what you enter.Once created, this evaluator is available as a guardrail in Deployments and Agents. See Evaluators and Guardrails in Deployments and Evaluators and Guardrails in Agents to learn more.
Python Evaluator
Python Evaluators let you write custom Python code for maximum flexibility: from simple validations (regex, length checks) to complex analyses (statistical scoring, custom algorithms).- AI Studio
- API & SDK
- MCP
In a Project or folder, click the button and select Python Evaluator. You are taken to the code editor. Your evaluation function has access to the following fields from the evaluated model’s log:
log["input"]<str>: the last message sent to generate the outputlog["output"]<str>: the generated response from the modellog["reference"]<str>: the reference used to compare the outputlog["messages"]list<str>: all previous messages sent to the modellog["retrievals"]list<str>: all Knowledge Base retrievals
- Number: return a numeric score
- Boolean: return a true/false value
Python
You can define multiple methods within the code editor. The last method is the entry-point for the Evaluator when run.
Environment and Libraries
- AI Studio
The Python Evaluator runs in Python 3.12 with the following preloaded libraries:
Guardrail Configuration
- AI Studio
Within a Deployment or Agent, use the Python Evaluator as a Guardrail to block generations that don’t meet the custom evaluation logic.Use the Pass condition to define when the guardrail passes:
- Boolean evaluators: select True or False. The guardrail passes when your function returns the selected value.
- Number evaluators: enter a score threshold. The guardrail passes when your function’s return value is greater than or equal to the threshold.
Examples
- AI Studio
Checking an output survives an external API round-trip
Checking an output survives an external API round-trip
Use the
requests package to send the output to an external endpoint and confirm it comes back unchanged. Return True only when the call succeeds and the echoed text matches the output.Python
Validating an insurance damage assessment report against a schema
Validating an insurance damage assessment report against a schema
Use
pydantic to validate that the output is JSON matching the expected damage report schema, including a confidence score between 0 and 1. Return True when it parses and validates, False otherwise.Python
Testing
- AI Studio
Fill the payload manually in the Editor. Enter values for 

input, output, reference, messages, and retrievals. All log fields resolve against what you enter.Versions
- AI Studio
When you are done editing, click Publish to save your changes. You will be prompted to write a commit message and choose a version bump: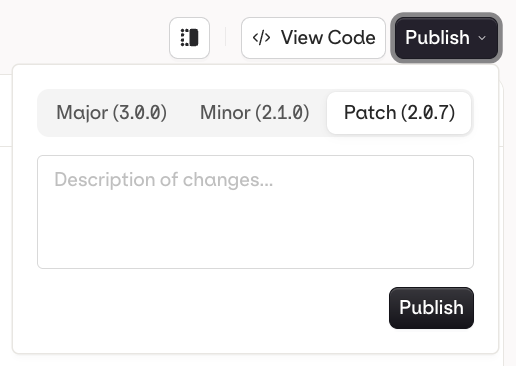
- Patch (e.g.
v1.0.0tov1.0.1): small fixes, no behaviour change - Minor (e.g.
v1.0.0tov1.1.0): new functionality, backwards compatible - Major (e.g.
v1.0.0tov2.0.0): breaking change or significant rework
| Action | Icon | Description |
|---|---|---|
| Compare | Open a diff view to see what changed between versions | |
| Code | Load a code snippet to invoke the evaluator at this exact version | |
| Environment | Tag the version with an Environment (e.g. production, staging) |
List Evaluators
- API & SDK
Use the List Evaluators API:
Invoke an Evaluator
- API & SDK
Fetch the evaluator ID from the List Evaluators API, then invoke it. Use the View Code button on your evaluator page in the AI Studio to get a pre-filled snippet.
Guardrail Error Response
When a guardrail evaluation fails, Orq.ai returns an HTTP422 Unprocessable Entity. The response body lists every guardrail that did not pass.
- Deployments
- Agents
| Field | Type | Description |
|---|---|---|
id | string | Internal ID of the guardrail result. |
status | string | Execution status: "completed" or "failed". |
started_at | string | ISO 8601 timestamp when the guardrail evaluation started. |
finished_at | string | ISO 8601 timestamp when the guardrail evaluation finished. |
related_entities | array | References to the evaluator that ran. Each entry contains type, evaluator_id, and evaluator_metric_name. |
passed | boolean | false for every entry in this error response. |
reason | string or null | Explanation of the failure, when provided by the evaluator. |
evaluator_type | string | "input_guardrail" if the guardrail ran before the model. "output_guardrail" if the guardrail ran after generation. |
type | string | The value type returned by the evaluator: "boolean", "number", or "categorical". |
value | boolean, number, or string | The raw value returned by the evaluator. |
When the evaluator fails to execute: If the evaluator itself fails to run (for example, a network error or timeout), the guardrail is silently skipped and the generation proceeds. Monitor skipped guardrail executions through Traces.When an LLM guardrail’s underlying model fails: If the model powering an LLM guardrail is unavailable, Orq.ai fails the entire request for safety. Since the guardrail could not run, there is no way to know whether it would have blocked the generation.
Evaluatorq
Evaluatorq is a dedicated SDK for running evaluations programmatically. It supports parallel job execution, flexible data sources (inline, CSV, Orq datasets), and syncs results to the Orq.ai AI Studio.- API & SDK
Install:Usage example:
See the Python Evaluatorq and TypeScript Evaluatorq repositories for more.
Cookbook: Running evaluations in parallel with Evaluatorq
Step-by-step walkthrough comparing agent variants with parallel evaluators, including DeepEval and RAGAS integration.