Orq MCP is live: Use natural language to interrogate traces, spot regressions, and experiment your way to optimal AI configurations. Available in Claude Desktop, Claude Code, Cursor, and more. Start now →
Create datasets to test LLM models at scale. Define inputs, messages, and expected outputs for experiments. Manage datasets via the AI Studio, API, or Orq MCP.
Datasets hold the test data that powers Experiments. Each dataset row contains up to three fields:
Inputs: Variables injected into the prompt at runtime, e.g. {{firstname}}.
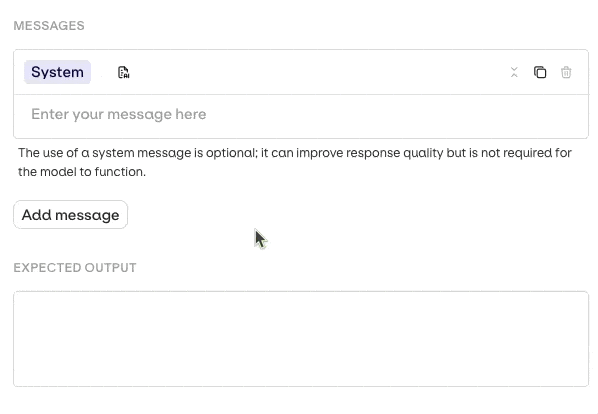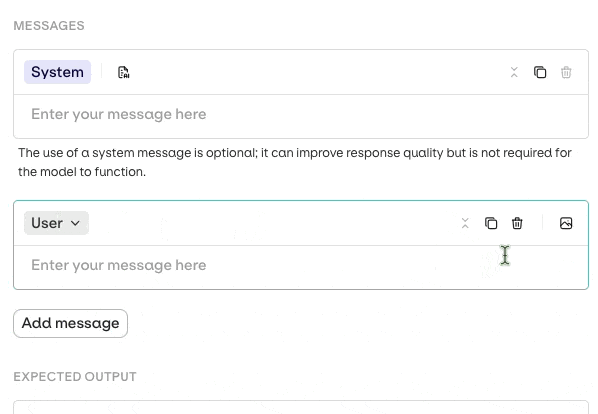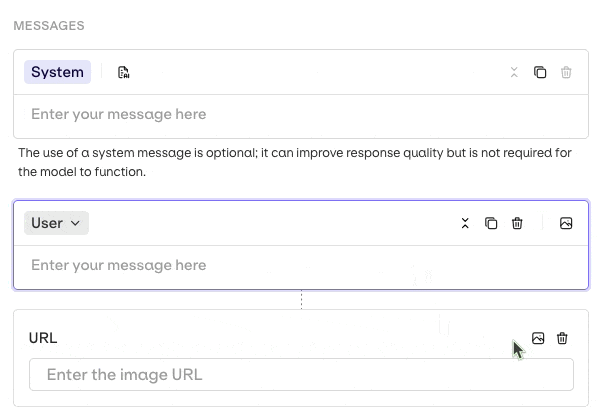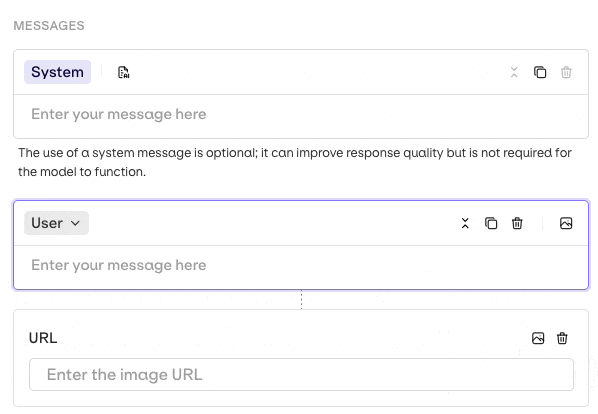
Messages: The prompt template, structured with system, user, and assistant roles.
Expected Outputs: Reference responses evaluators compare against model outputs.
You don’t need all three fields in every dataset. A dataset with only inputs, or only messages, is valid.
Run the same dataset through your prompts before and after a change to verify that updates haven’t degraded performance in any area.
Compare models and prompt variants
Use the same dataset across multiple models or prompt configurations in an Experiment to find the best combination of quality, cost, and latency.
Curated datasets for fine-tuning
Have domain experts review and correct model outputs, then save those verified input/output pairs as a curated dataset to use as fine-tuning reference data.
Synthetic data generation at scale
Use the Orq MCP to generate hundreds of realistic test cases programmatically and add them directly to a dataset without leaving your IDE.
Vision and image datasets
Build datasets with image messages for testing vision models. Supports JPEG, PNG, GIF, and WebP via the AI Studio or API.
Use the button on a Project folder and select Dataset. Enter a title to open the Table View.The table has three columns: Inputs, Messages, and Expected Outputs. Add as many rows as needed.
Use the Create Dataset API. A unique display_name and a path (the Project folder) are required.
Create a dataset called "Support Training Data" in the Default project
The assistant uses create_dataset with the display name and path.Generate a synthetic dataset:
Generate 50 realistic customer support questions about a SaaS product and create a dataset called "Support Training Data"
The assistant generates the entries, uses create_dataset to create the dataset, then uses create_datapoints to add all entries in bulk.Find an existing dataset:
Find the "user-queries" dataset in my workspace
The assistant uses search_entities with type: "dataset" to locate it by name.
Manually: Click Add Row and fill in each cell.From CSV: Click Import and drag-and-drop a .csv file. Map each CSV column to a Dataset field (Inputs, Messages, Expected Outputs). Each row becomes a separate datapoint.
Use the Create Datapoints API. Send between 1 and 5,000 datapoints per request. Requests over 500 datapoints are automatically chunked.
Curated datasets are human-evaluated input and output sets: a prompt paired with a verified expected output. They are used for fine-tuning and as a gold-standard reference in Experiments.Within any module, open the Logs tab and select a log entry. The Feedback panel appears on the right.To add a correction, click Add correction below the assistant response:
The Add correction button is below the assistant response.
Edit the response in the Correction message that opens, then click Save.
The original and corrected responses appear side by side. The correction is shown in green.
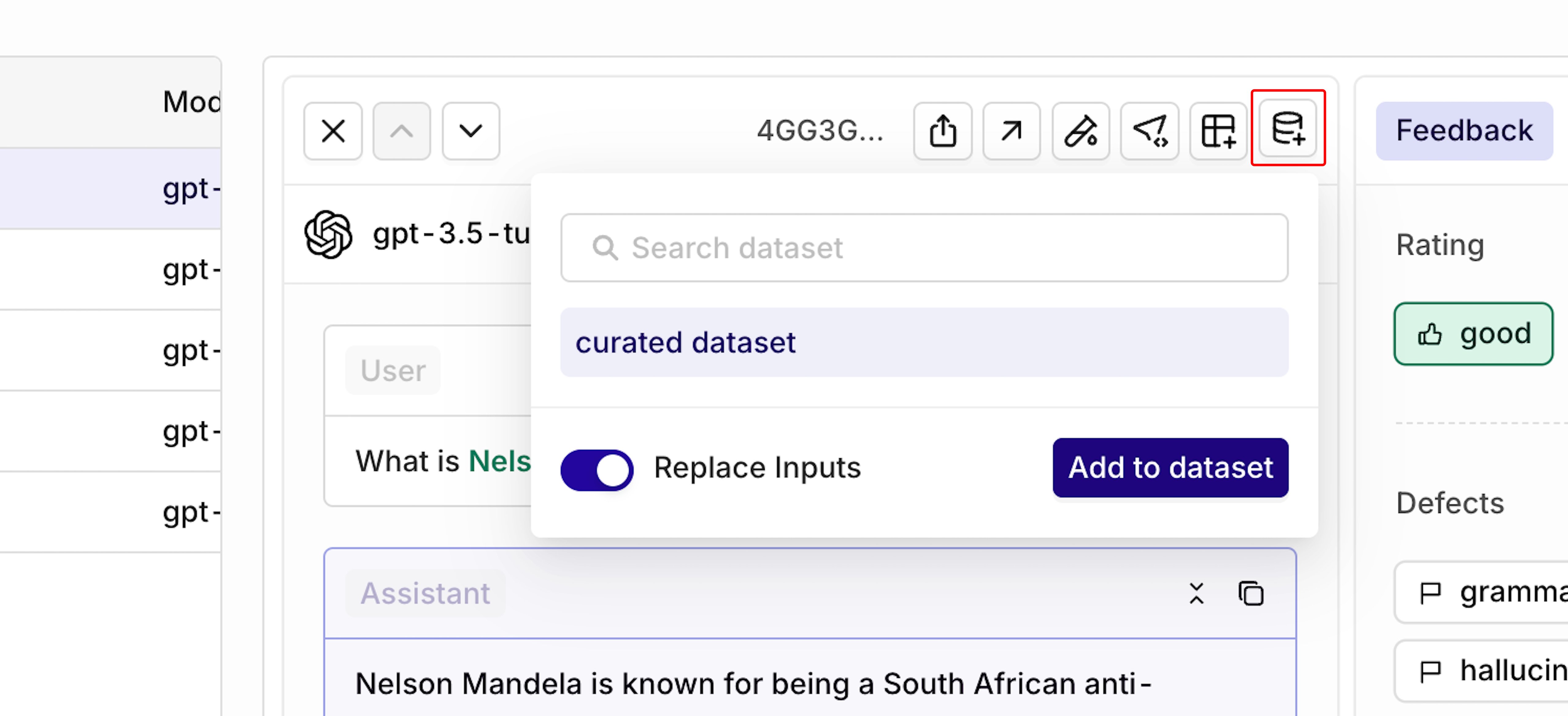
Click the Add to Dataset icon at the top-right of the response to save the corrected entry to a dataset:
Choose to replace the inputs used during generation (recommended).
Import a curated dataset into an Experiment, attach an Evaluator, and see which model or prompt scores best against the curated reference outputs.


 AI Studio
AI Studio MCP
MCP