

Run Agents
For Python and Node.js client libraries, see Orq SDKs.
- API & SDK
 MCP
MCP
Streaming
Setstream: true to receive incremental output as server-sent events. The response arrives in chunks as the Agent produces it.
| Event | When | Key field | Notes |
|---|---|---|---|
response.created | Stream opens | id | Pass as previous_response_id to continue the conversation |
response.output_text.delta | Each text chunk | delta | Append to build the full output |
response.output_text.done | Text generation complete | text | Full accumulated text |
response.completed | Agent finishes | status | Value is "completed" |
response.failed | Agent encountered an error | response.error | Full error details; response.status is "failed" |
Pass Variables
Pass variables in thevariables field of the execution request:
Attach Files
Attach files in thecontent array of an input message item:
- Images: Via URL (
image_url). For base64-encoded images, also setmime_type(e.g.image/jpeg). - PDFs: Data URI only (
file_data). Pass the file asdata:application/pdf;base64,<base64-data>. URL links are not supported for PDFs.
Continue a Conversation
- API & SDK
- MCP
After receiving a response, continue the conversation by passing the previously received response The continuation returns a new response
id as previous_response_id in the next request. The agent maintains full context from previous exchanges.id for the extended conversation. The agent retains full context from all prior turns.Use Memory Stores
To call the Agent with a memory store, we’ll use the Responses API with an Embedded message and Linked memory.Attach Metadata
Attach arbitrary key-value pairs to a response using themetadata field. Metadata is stored on the response and visible in traces. Use it to tag runs by session, user, environment, or any other dimension useful for filtering in Observability. Values must be strings.
Use Tools
Pass tools in thetools array of any Responses API call. Multiple tools of different types can appear in the same request.
| Tool type | What it does |
|---|---|
| Function | Define a custom schema. The model decides when to call it; the application executes and returns the result. |
| MCP Server | Connect to an MCP-compatible server. Orq.ai fetches the tool catalog and routes calls to the server. |
| HTTP | Call an external REST endpoint. Orq.ai executes the request; no application-side logic needed. |
| Built-ins | Platform-managed tools (orq:google_search, orq:web_scraper, orq:current_date) with no setup or execution logic. |
Function
Function
Define a custom function schema. The model decides when to call it, fills the parameters, and returns a
function_call output item. Choose Inline to embed the schema in the request, or Pre-saved to reuse a schema stored in Studio.- Inline
- Pre-saved
Define a function schema inline. The model decides when to call it, fills the parameters, and returns a The response contains a Step 2: Execute the function and return the result:Pass Function tool fields:
function_call output item. The application executes the function and sends the result back.Step 1: Send the request with a function tool:function_call output item when the model decides to use the tool:previous_response_id and a function_call_output input item with the matching call_id. Include the same tools array so the model can make additional calls if needed.| Field | Type | Required | Description |
|---|---|---|---|
type | string | yes | "function" |
name | string | yes | Function name. Returned in the function_call output item so the application knows which function to run. |
description | string | no | What the function does. Helps the model decide when to call it. |
parameters | object | no | JSON Schema object describing the function’s parameters. |
strict | boolean | no | Enforce strict parameter validation against the schema. |
MCP Server
MCP Server
Connect to any MCP-compatible server. This lets the agent read from and write to external services like Linear, Slack, or GitHub without writing any integration code. Choose Inline to supply the server URL per-request, or Pre-saved to reference a saved server by key with credentials stored on the platform.
- Inline
- Pre-saved
Supply the MCP server URL directly in the request. The tool catalog is fetched from the server on each call. Use for one-off calls or when the server has not yet been saved under Tools. Provide Per-request credentialsUse
server_url (inline) or key (pre-saved), not both.{{variable}} placeholders in headers and supply values at call time. The secret: true wrapper keeps token values out of traces and logs:HTTP
HTTP
Reference an HTTP tool saved in Studio using To create and manage HTTP tools, see Create Tools.
orq:http and its tool_id. Orq.ai executes the HTTP request against the configured endpoint and returns the result to the model. No execution logic needed in the application.Built-ins
Built-ins
Orq.ai includes platform-managed tools that require no configuration. Reference them by
Built-in tools execute automatically on Orq.ai infrastructure. Results are fed back to the model within the same request; no
type alone. No credentials or execution logic needed in the application.type | Description |
|---|---|
orq:current_date | Returns the current UTC date and time. |
orq:google_search | Performs a Google search and returns top results. |
orq:web_scraper | Fetches and extracts text content from a URL. |
function_call_output round-trip needed.Control Tool Calls
Controls whether and which tool the model calls. Applies to all tool types.Auto: Model Decides
Auto: Model Decides
Default when tools are present. The model decides on each turn whether to call a tool or answer directly. Use this for conversational agents where tool use is situational.
Required: Always Call a Tool
Required: Always Call a Tool
The model must call at least one tool before producing a final response. Use when a tool call is always necessary: for example, a retrieval step before every answer.
None: Disable Tools
None: Disable Tools
The model must not call any tool. Tools remain present in the request (the model can see their schemas) but cannot invoke them. Use to temporarily disable tools without removing them from the request.
Specific Function: Force One Tool
Specific Function: Force One Tool
Force the model to call one named function. Pass
{ "type": "function", "name": "<function name>" }, replacing <function name> with the exact name from the tool definition. Use when the application must extract structured data from a known function schema.Filter Tools
MCP servers can expose dozens of tools. Useallowed_tools on any MCP entry (inline or pre-saved) to narrow what the model sees. Tools outside the filter are invisible to the model and cannot be invoked. allowed_tools applies only to MCP tools; it has no effect on function, HTTP, or built-in tools.
tool_names: Expose Named Tools Only
tool_names: Expose Named Tools Only
Expose only the listed tools by name. The model cannot see or call any tool not in the list.
read_only: Non-mutating Tools Only
read_only: Non-mutating Tools Only
Expose only tools the server marks as
readOnlyHint: true. Use to prevent the model from calling any mutating operations. The server must annotate tools with readOnlyHint for this filter to have effect.Combined: Name and Read-only Filter
Combined: Name and Read-only Filter
Intersection filter: expose only tools that are both read-only AND in the named list.
Streaming Events
Setstream: true on any request with tools. See Streaming for setup and base event shapes. For function tools, act on response.output_item.done: it carries the complete function_call item with arguments and call_id ready for Step 2. MCP server calls also emit three additional events:
| Event | When |
|---|---|
response.mcp_call.in_progress | MCP tool starts executing. |
response.mcp_call.completed | MCP tool returned a result. |
response.mcp_call.failed | MCP tool raised an error or the connection failed. |
type: "mcp_call". Function tool output items use type: "function_call". Match on type when processing output on the client.
Observability
Every tool invocation appears in traces as a child span of the agent loop. All tool spans:| Attribute | Description |
|---|---|
gen_ai.tool.name | The tool name the model called. |
gen_ai.tool.type | mcp, function, http, or code. |
gen_ai.tool.call.id | The call ID matching the output item in the stored response. |
gen_ai.tool.call.arguments | JSON-encoded arguments passed to the tool (secrets redacted). |
| Attribute | Description |
|---|---|
server.address | The MCP server URL. |
mcp.session.id | The pre-saved tool key, or the inline server URL for ad-hoc calls. |
mcp.method.name | Always tools/call. |
Error Reference
Rejected server_url
Rejected server_url
HTTP
400, type: "invalid_request"The server_url uses a bad scheme or resolves to a disallowed address (loopback, link-local, private RFC 1918, unspecified, or cloud-metadata).Pre-saved Key Not Found
Pre-saved Key Not Found
HTTP
400, type: "invalid_request"The key passed in the request does not match any tool saved in the workspace.Server Refused the Handshake
Server Refused the Handshake
HTTP
400, type: "invalid_request"The MCP server rejected the connection during the initialization handshake.Server Unreachable or Bad Response
Server Unreachable or Bad Response
HTTP
400, type: "invalid_request"The MCP server was not reachable or returned a malformed response during tool discovery.Server-side Failure
Server-side Failure
HTTP
500, type: "internal_error"An unexpected error occurred on the Orq.ai side. Retry with exponential backoff.Tool-call Execution Failure
Tool-call Execution Failure
HTTP
200, output item with status: "failed"The tool call was routed successfully but the tool itself raised an error. The overall HTTP response is 200 because the request succeeded; inspect output[n].output for the error detail.Limits
| Limit | Value |
|---|---|
| Supported MCP transports | Streamable HTTP (preferred) and SSE |
| Tool discovery per call | 250 tools across all MCP servers |
| Per-tool call timeout | 10 minutes |
| Encrypted header size | 16 KB per header value |
Schedule Agents
Run an agent on a recurring cadence without holding open an HTTP connection. Each scheduled run follows the same execution path, tracing, and billing as a direct API call.Create a Schedule
 AI Studio
AI Studio- API & SDK
Open the agent and go to the Schedules tab. Click New schedule to open the form.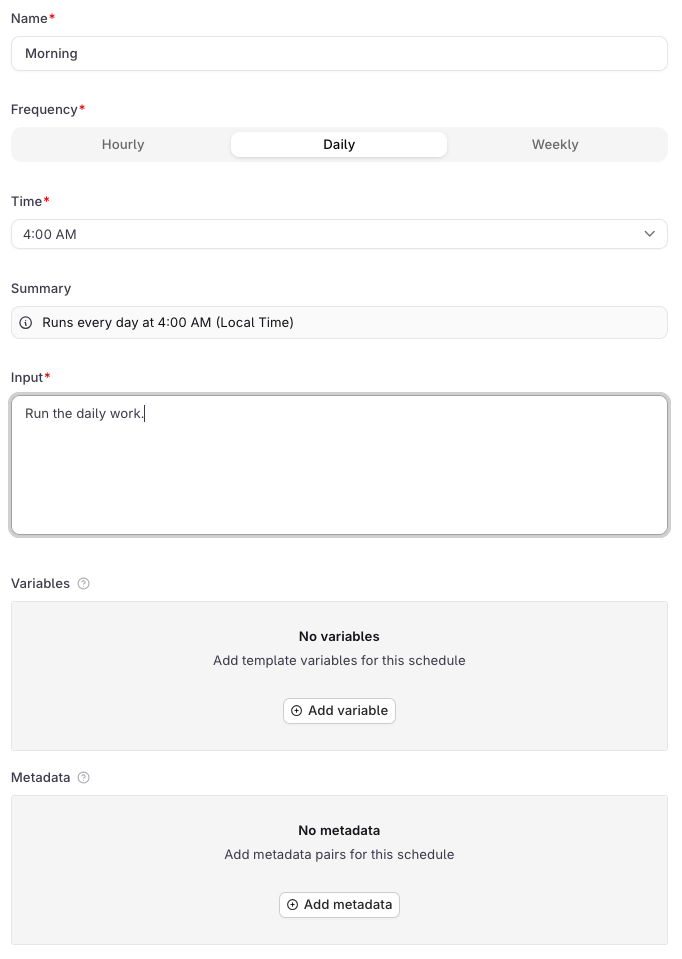
VariablesUse the Variables section to define values that the agent needs on each run. Variables are sent alongside the input as a distinct payload field, and can be consumed by the agent’s instructions, any configured tool, or a subagent wherever the variable is wired up.Variables cannot be referenced inside the Input field itself. Wire them into the agent’s instructions, a tool, or a subagent instead.MetadataUse the Metadata section to attach arbitrary key-value pairs to every response generated by this schedule. Metadata is not passed to the agent: it is stored on the trace and can be used to filter traces in Observability, identify which schedule triggered a run, or tag responses for downstream processing.Click Create to activate the schedule. It starts firing at the next matching time.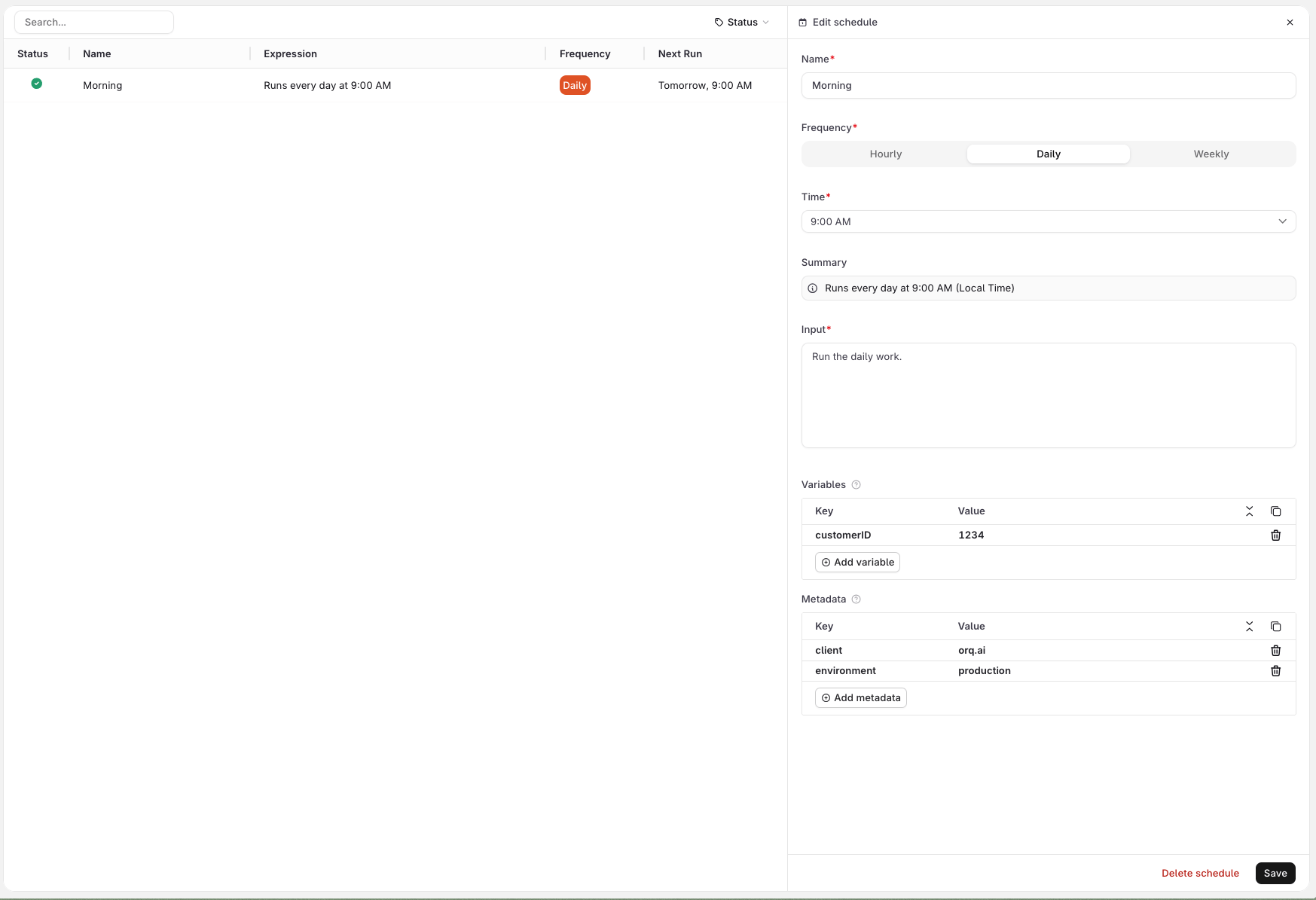
| Field | Description |
|---|---|
| Name | A display label for the schedule in the UI. Required. Not sent to the agent. |
| Frequency | Hourly, Daily, or Weekly. |
| Time | The hour the schedule fires, in local time. Shown for Daily and Weekly. |
| Pick the day | Day of the week to fire. Shown for Weekly only. |
| Summary | Auto-generated human-readable description of the schedule. |
| Input | The user message sent to the agent on each firing. Required, since every agent invocation needs a user message. |
| Variables | Key-value pairs passed to the agent on each run. See below. |
| Metadata | Key-value pairs attached to every response this schedule generates. See below. |
For example, a support agent with an HTTP tool that looks up a customer in an external system can receive
customer_id=1234 from the schedule and use it to query the right record on every run. See the screenshot below.List & Retrieve
- AI Studio
- API & SDK
All schedules for the agent are listed in the Schedules tab. Click a schedule row to open its details, including trigger count and last fired time.
Pause and Resume
- AI Studio
- API & SDK
Click on the schedule row, then click Enable to toggle the schedule on or off. Field edits saved while paused take effect on the next active run.
Trigger On Demand
- API & SDK
Runs the schedule’s payload immediately without affecting its regular cadence. Useful for smoke-testing a new schedule or manually re-running a missed execution.Returns The run appears in traces as a
202 Accepted with:schedule.<agent_key> leading span roughly 10 seconds later, carrying orq.schedule_id and the full agent execution chain. Schedule-driven cost and token usage appear in usage reports alongside HTTP-invoked runs. Inactive schedules return 400 schedule_inactive.Delete
- AI Studio
- API & SDK
Click on the schedule row, then click Delete. The action is immediate and permanent.
Examples
- API & SDK
Daily morning briefing (9 AM UTC)
Daily morning briefing (9 AM UTC)
Hourly background summarizer (with memory)
Hourly background summarizer (with memory)
memory_entity_id attaches a Memory Store entity to every run. The agent can read from and write to the store on each firing, accumulating context across executions.Scheduled run with secret variables
Scheduled run with secret variables
Agent and Task States
- AI Studio
- API & SDK
- MCP
Agent states:
Task states:
| State | Description |
|---|---|
| Active | Execution in progress; continuation requests blocked |
| Inactive | Waiting for user input or tool results; ready for continuation |
| Error | Execution failed; continuation blocked |
| Approval Required | Tool execution requires manual approval (coming soon) |
| State | Description |
|---|---|
| Submitted | Task created and queued for execution |
| Working | Agent actively processing |
| Input Required | Waiting for user input or tool results |
| Completed | Task finished successfully |
| Failed | Task encountered an error |
| Canceled | Task was manually canceled |
Multi-Agent Workflows
- AI Studio
- API & SDK
- MCP
Multi-agent workflows are configured at the agent level. Each agent in a team is created individually, then the orchestrator references sub-agents through its
team_of_agents configuration.The Description field on each sub-agent is critical: orchestrators use it to decide when to delegate.To configure multi-agent setups, see Build Agents: Instructions for how to write descriptions that enable effective delegation.
Traces
- AI Studio
- API & SDK
- MCP
The Traces tab in the agent page shows execution logs filtered to the agent automatically.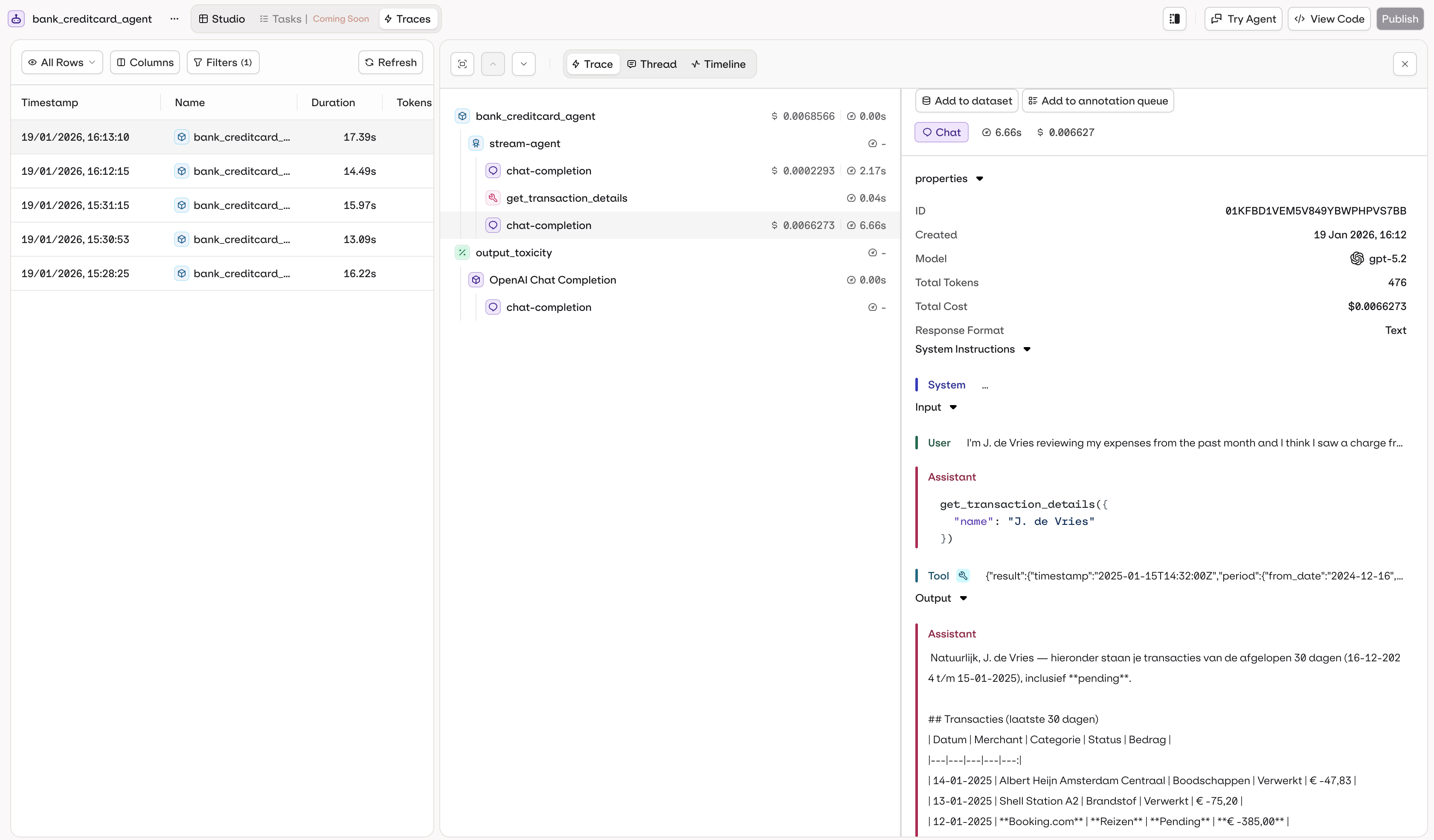
- Execution history with timestamps
- Input and output for each call
- Token usage and cost per execution
- Execution duration and performance metrics
- Errors and debugging information
- Tool calls executed (function, HTTP, code, or MCP calls)
- Knowledge retrieval results and RAG context
- Memory store interactions
Trace Views
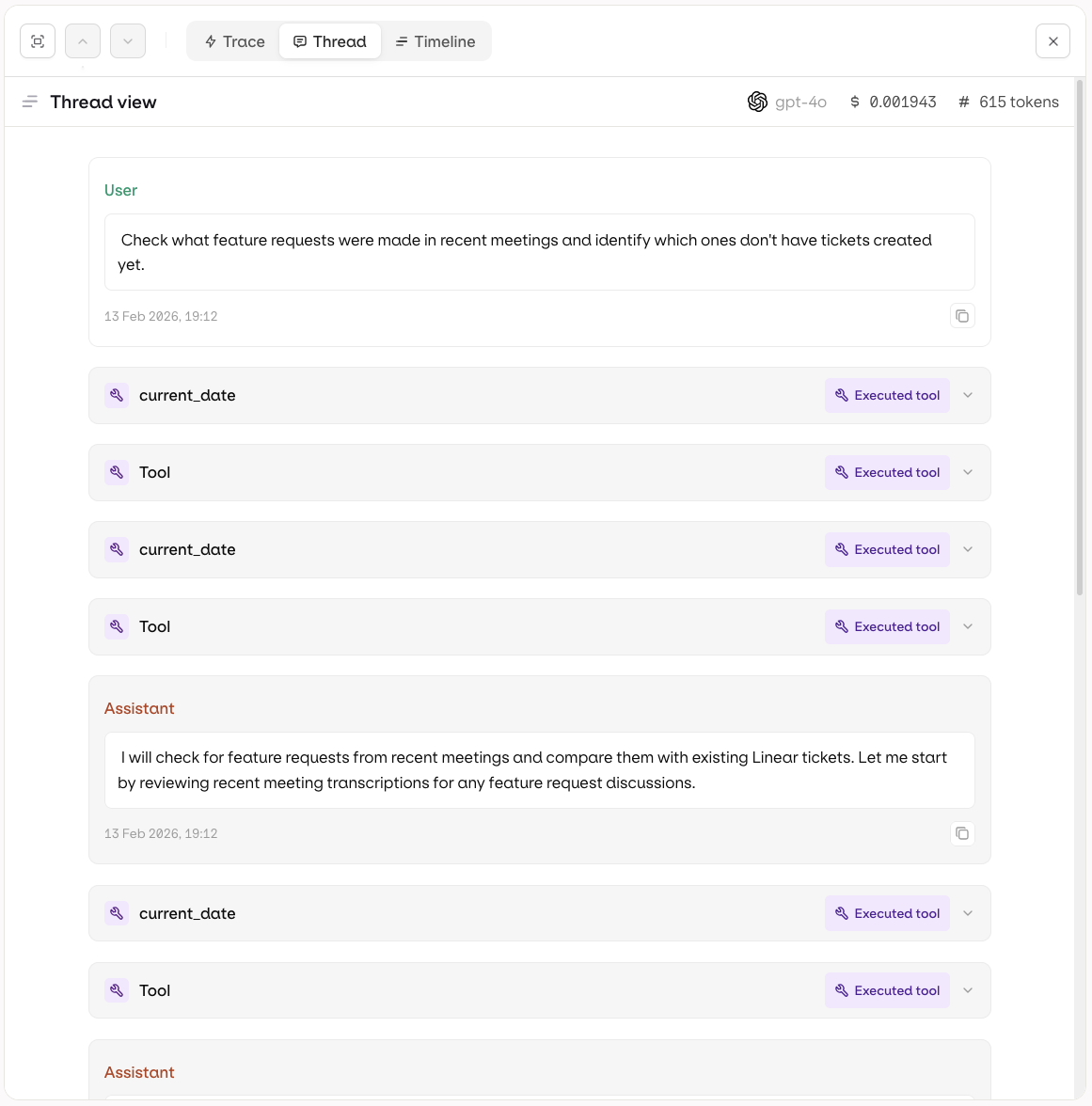
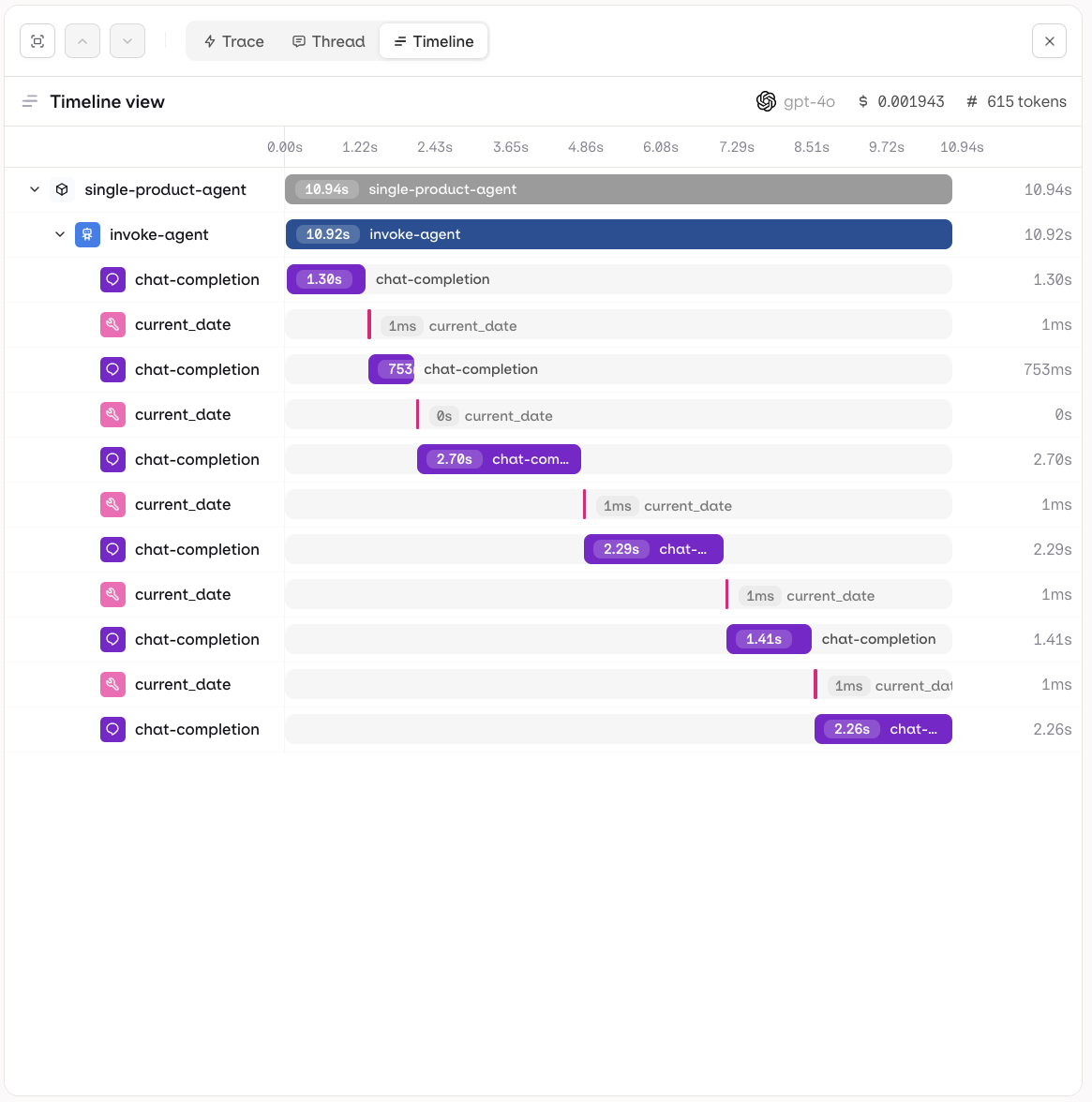
Each trace can be inspected in three views:- Trace
- Thread
- Timeline
The Trace view shows the full execution tree for a single agent run. Each step is displayed hierarchically, including LLM calls, tool invocations, knowledge retrievals, and memory interactions.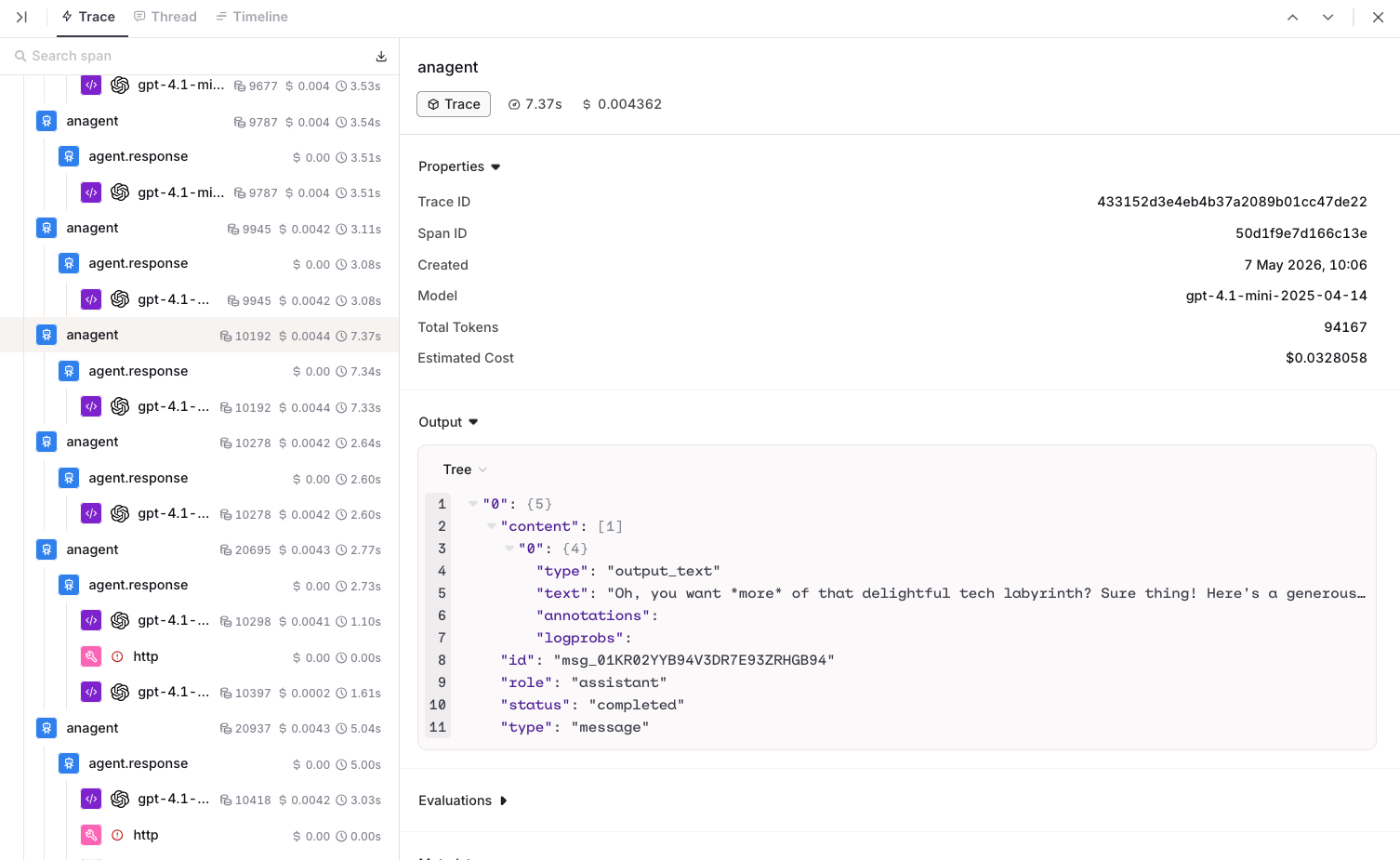
Creating Custom Views
Save frequently used filter combinations as reusable views:- Set the desired filters.
- Click All Rows (top right).
- Select Create New View.
- Give the view a title.
- Optionally check Set view private (default is shared with project members).