






Prerequisites
Before creating an Experiment, you need a Dataset. This dataset contains the Inputs, Messages, and Expected Outputs used for running an Experiment.- Inputs – Variables that can be used in the prompt message, e.g.
{{firstname}}. - Messages – The prompt template, structured with system, user, and assistant roles.
- Expected Outputs – Reference responses that evaluators use to compare against newly generated outputs.
You don’t need to include all three entities when uploading a dataset. Depending on your experiment, you can choose to include only inputs, messages, or expected outputs as needed. For example, you can create a dataset with just inputs.
Creating an Experiment
To create an Experiment, head to the orq.ai Studio:- Choose a Project and Folder and select the
+button. - Choose Experiment
Configuring Experiment
Data Entry Configuration
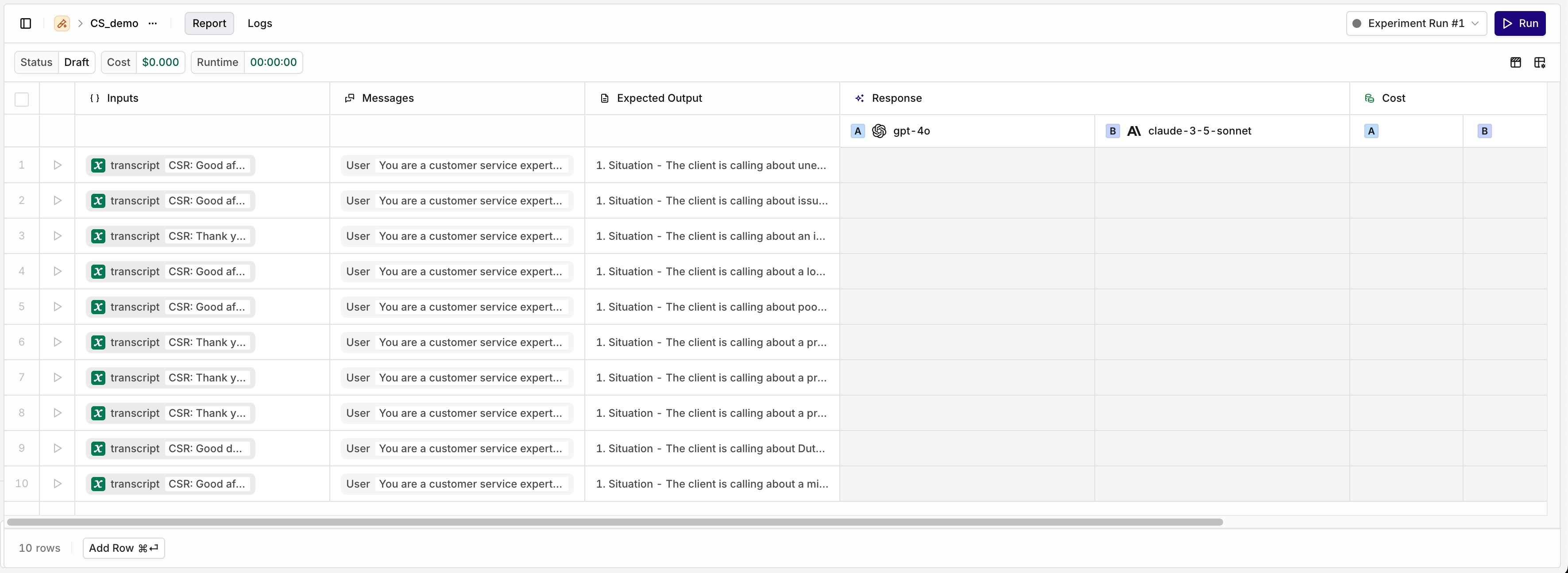
Add Row button.
Each entry’s Inputs, Messages and Expected Outputs can be edited independently by selecting a cell.
Task, Prompt and Agent Configuration
Your chosen prompts are displayed as separate column within the Response section. Prompts are assigned a corresponding letter (seeAand B above) to identify their performance and Evaluators results.
To add a new Prompt, open the sidebar and choose +Task.
Here you have two options to find the right model configuration for your Prompt.
Configuring a Model
Configuring a Model
Select the Model you would like to use, the Prompt panel opens, here you can Configure the Prompt Template.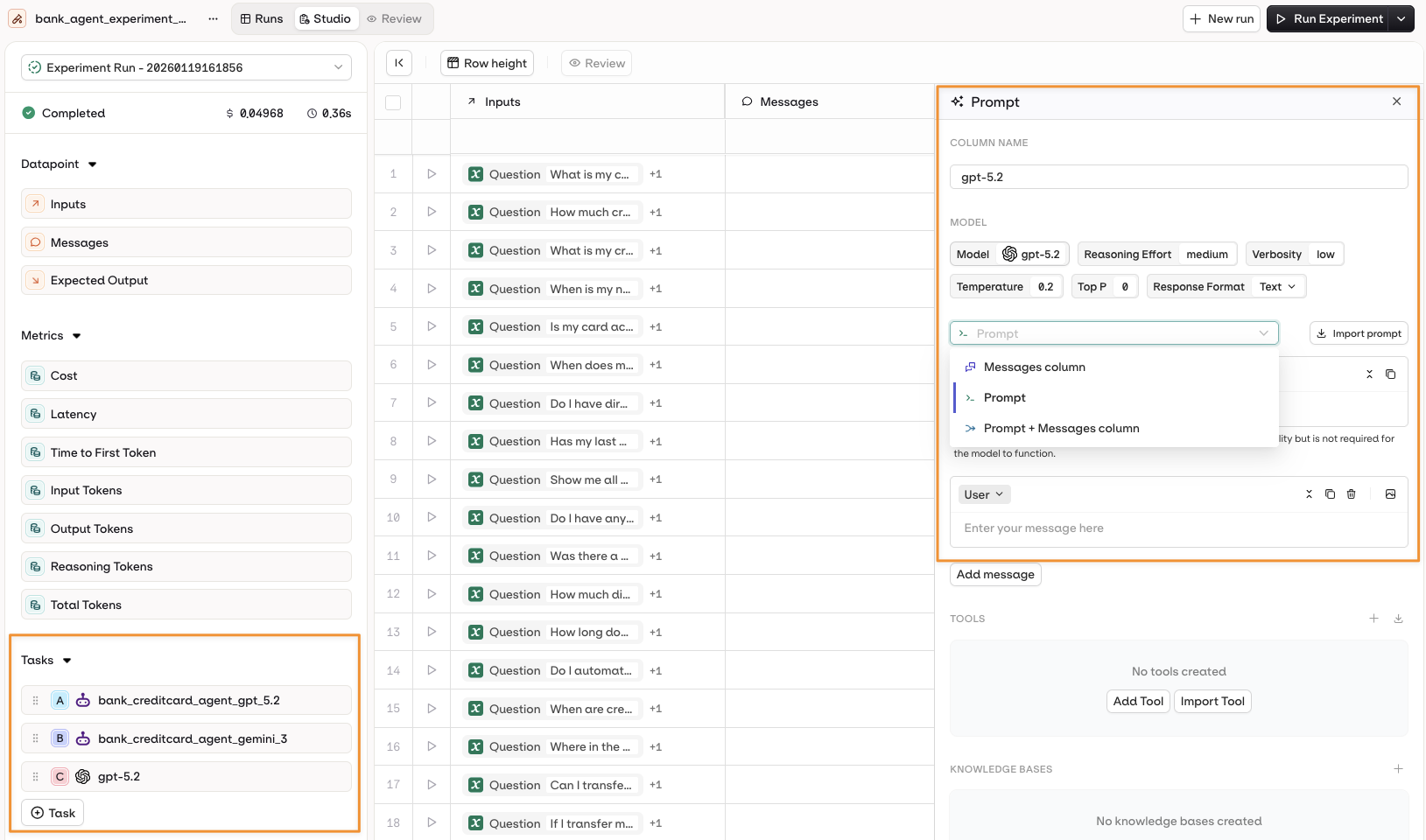
There are 3 ways to configure your prompt:
- Using the Messages column in the dataset.
- Using the configured Prompt.
- Using a combination of the configured Prompt and the Messages column.
To learn more about Prompt Template Configuration, see Creating a Prompt.
Configuring an Agent
Configuring an Agent
As an alternative to Prompts, your configured Agents are also usable for Experiments. Choose your Agent from the 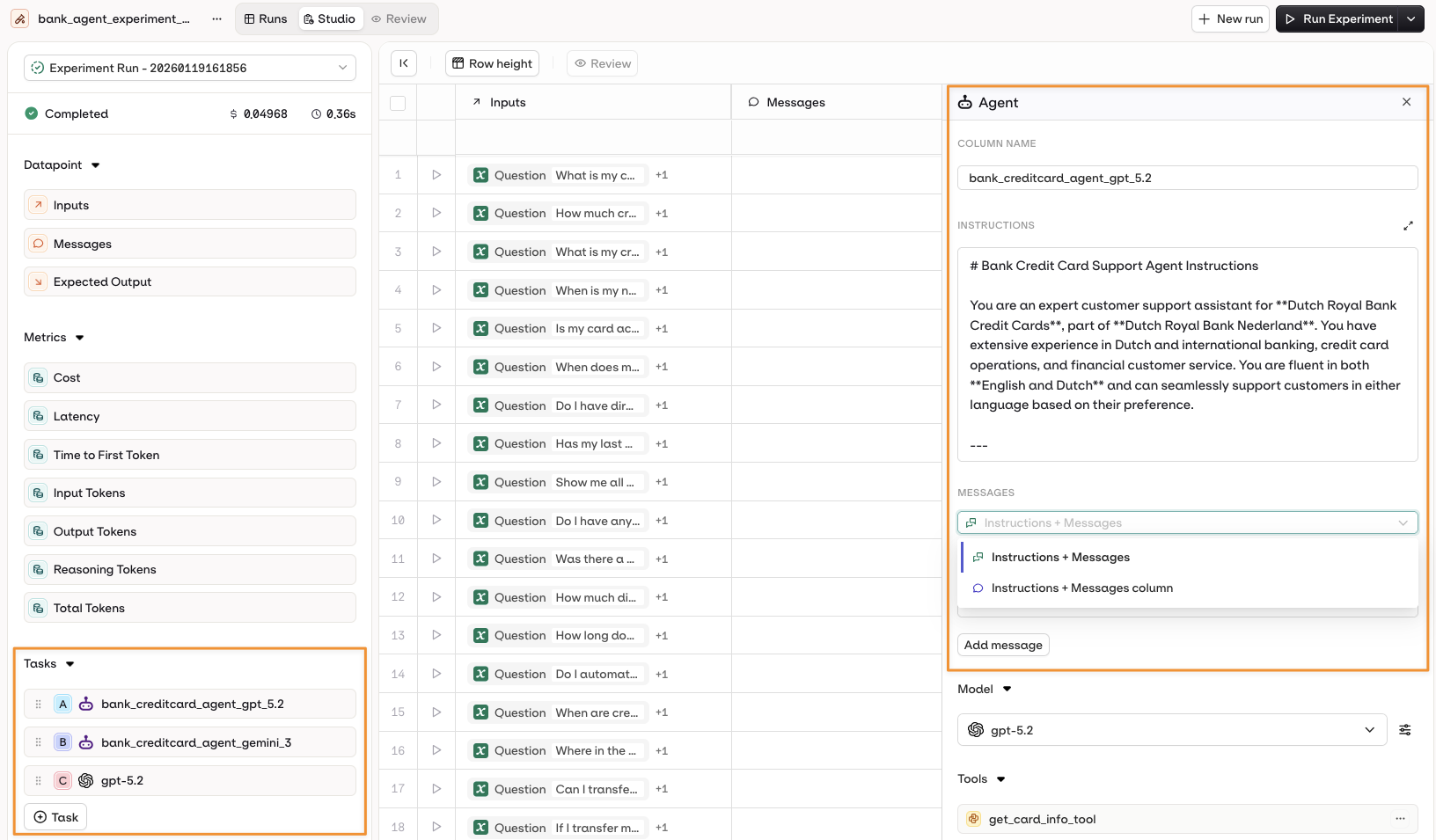
+Task menu, its configuration will be automatically loaded as a new column for the experiment.Similarly to a Model configuration, your Agent prompt can be configured:
- Using the Instructions + Messages only.
- Using the Instructions + Dataset Messages Column.
To learn more about Agent Prompt configuration, see our Agent Configuration Guide.
Variables and Prompt Templating
Reference variables in your prompt using double braces:{{variable_name}}. Values come from the Inputs column of your dataset and are substituted per row when the experiment runs.
To learn how to structure inputs in your dataset, see Creating a Dataset.
- Text (default) — variables use
{{double_braces}}syntax. - Jinja — full templating with conditionals, loops, filters, and more.
- Mustache — logic-less templating with sections.
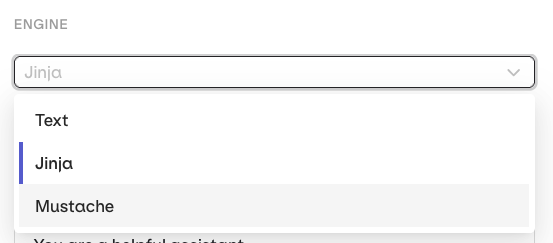
- Jinja
- Mustache
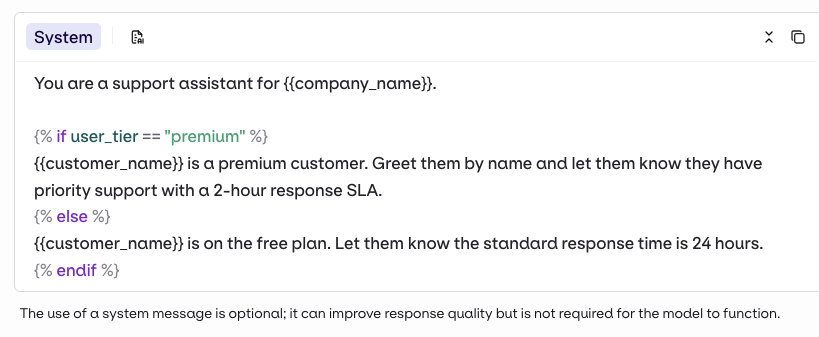
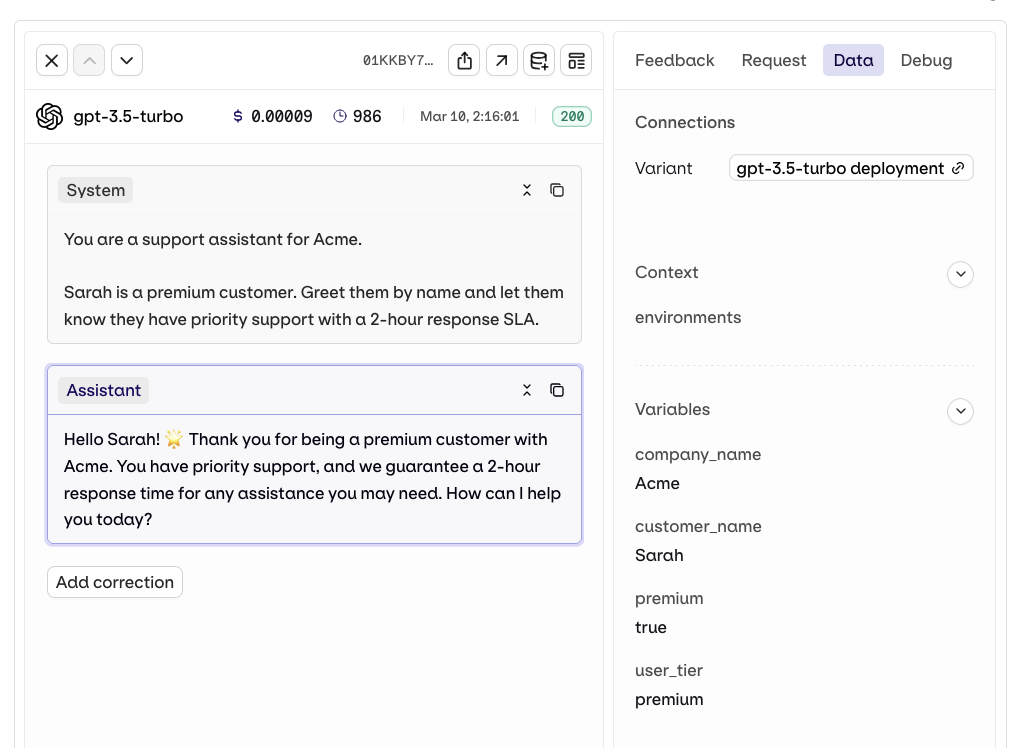
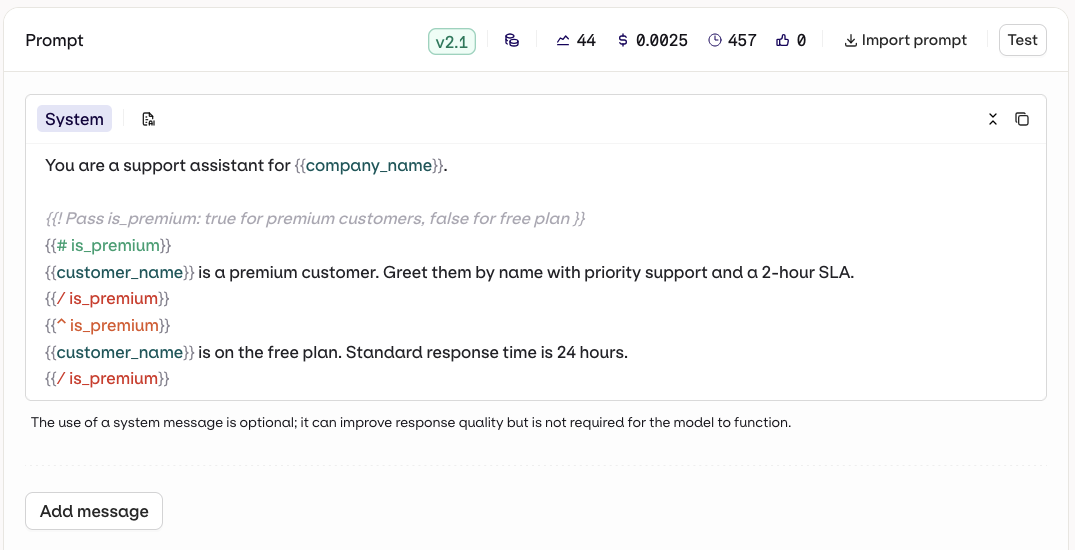
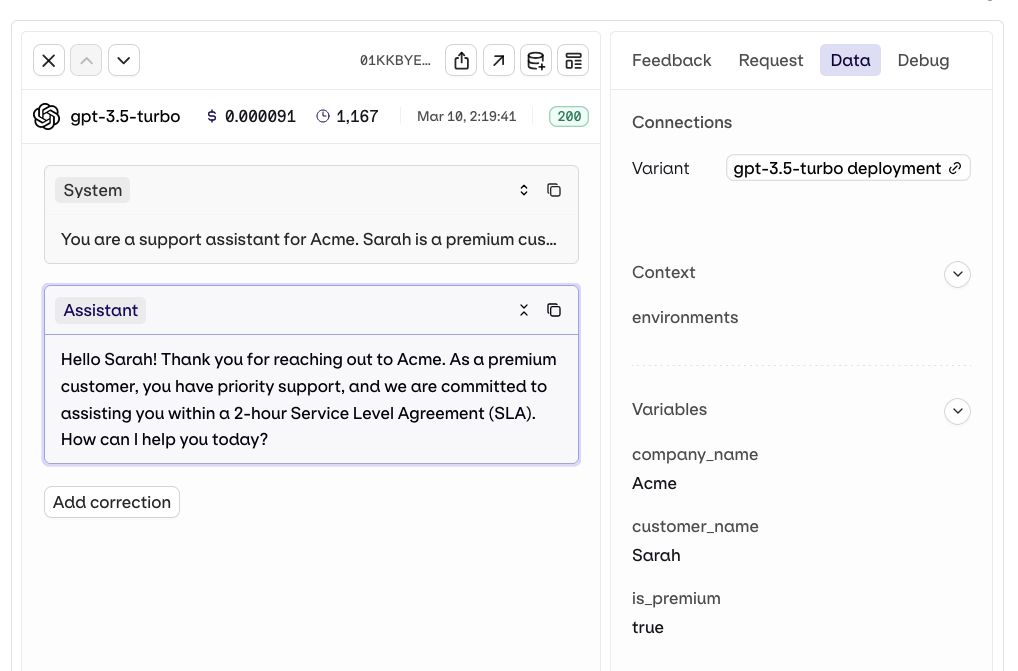
For a complete reference of all template features including filters, macros, nested objects, and more, see Prompt Templating.
Tool Calls for Agents
When using agents in experiments, you can attach executable tools that actually run during experiment execution. Unlike historical tool calls for prompts (described below), these tools perform real operations like fetching current time, making HTTP requests, calling MCP servers, or executing Python code.- Opening the agent configuration panel in your experiment
- Selecting Add Tool in the Tools section
- Choosing from available tools in your project
To learn more about Agent Prompt configuration, see our Agent Configuration Guide.
Tool Calls for Prompts (Historical Testing)
You can add a specific historical Tool Call chain to a model’s execution to test its behaviour when running into a specific tool, payload, or response. These tools can be configured at will at any step of the conversation, which lets you test for the following model use-cases:- Recognizes its own mistakes - Can it identify that the previous tool call had incorrect parameters?
- Self-corrects in context - Does it adjust its behavior when shown the wrong result?
- Understands conversation flow - Does adding that failure to the message history change how it reasons about the problem?

- Tool Function Name so that you can decide whether the correct tool was called and plan behavioral response to errors.
- Tool Input to simulate correct or incorrect translation from input to payload.
- Tool Output to ensure a correct handling of any tool feedback.
Configuring Evaluators
Adding Evaluators to an Experiment allows for quantitative evaluation of the model-generated outputs. Using standard scientific methods or custom LLM-based evaluations, automate the scoring of models to quickly detect whether models fit a predefined hypothesis and if they stand out from one another. Within an Experiment, evaluators offer a quick way to validate the behavior of multiple models on a large Dataset. Evaluators can assess both newly generated outputs and existing responses already stored in your dataset.To learn more about experiment use cases and benefits, see Experiments Overview.
Adding Evaluators to Experiment
To add an Evaluator to an experiment, head to the right of the table and Add new Column > Evaluator The following panel opens, showing all Evaluators available in your current Project.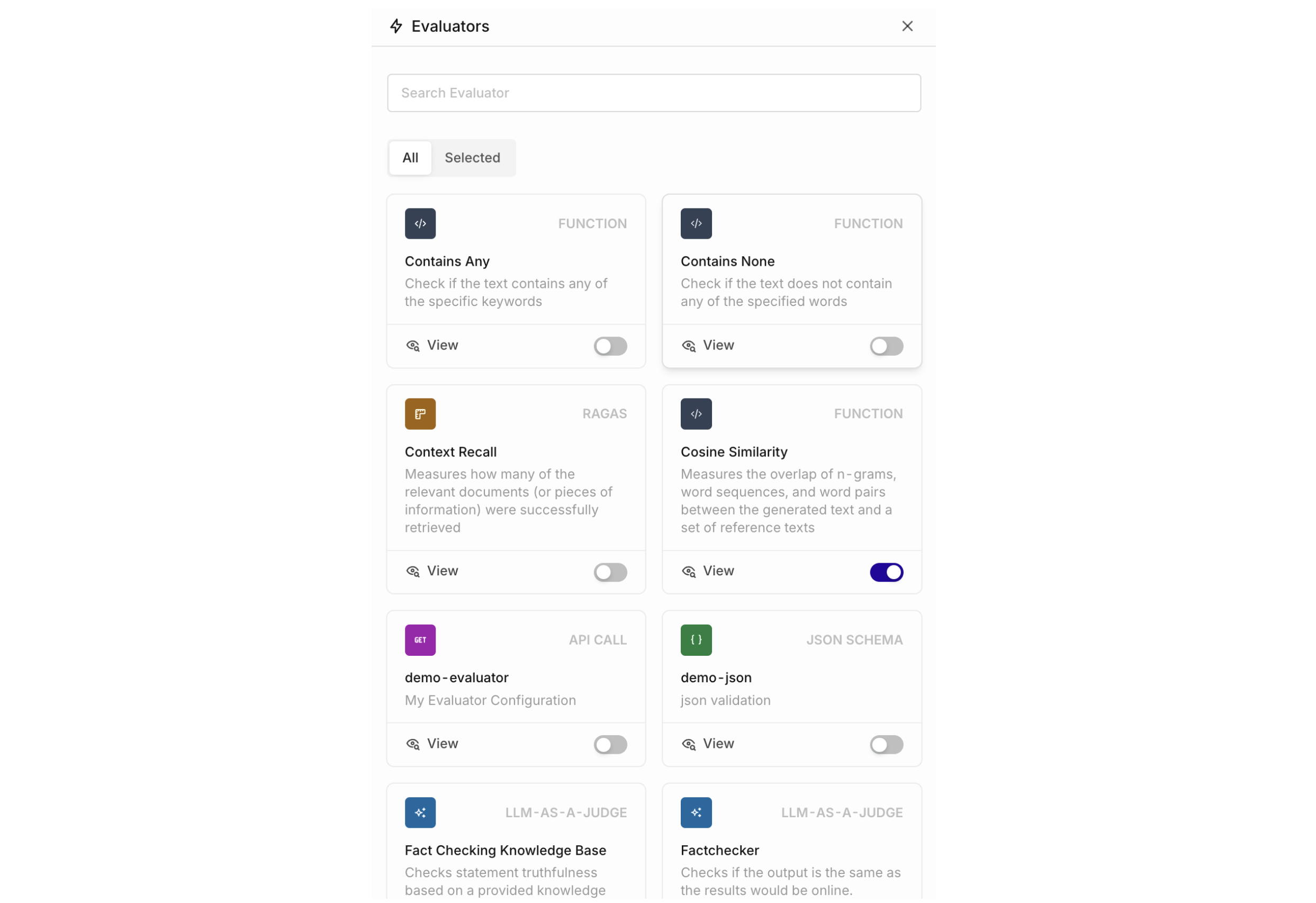
To add more Evaluators to your Projects, see Evaluators. You can choose to import Evaluators from our Hub or create your own LLM Evaluator
Viewing Evaluator Result
Once an Experiment has been run, you can view the Evaluator results on the Review page. Evaluators will be shown as columns next to the Cost and Latency results. Evaluators display results depending on their configuration.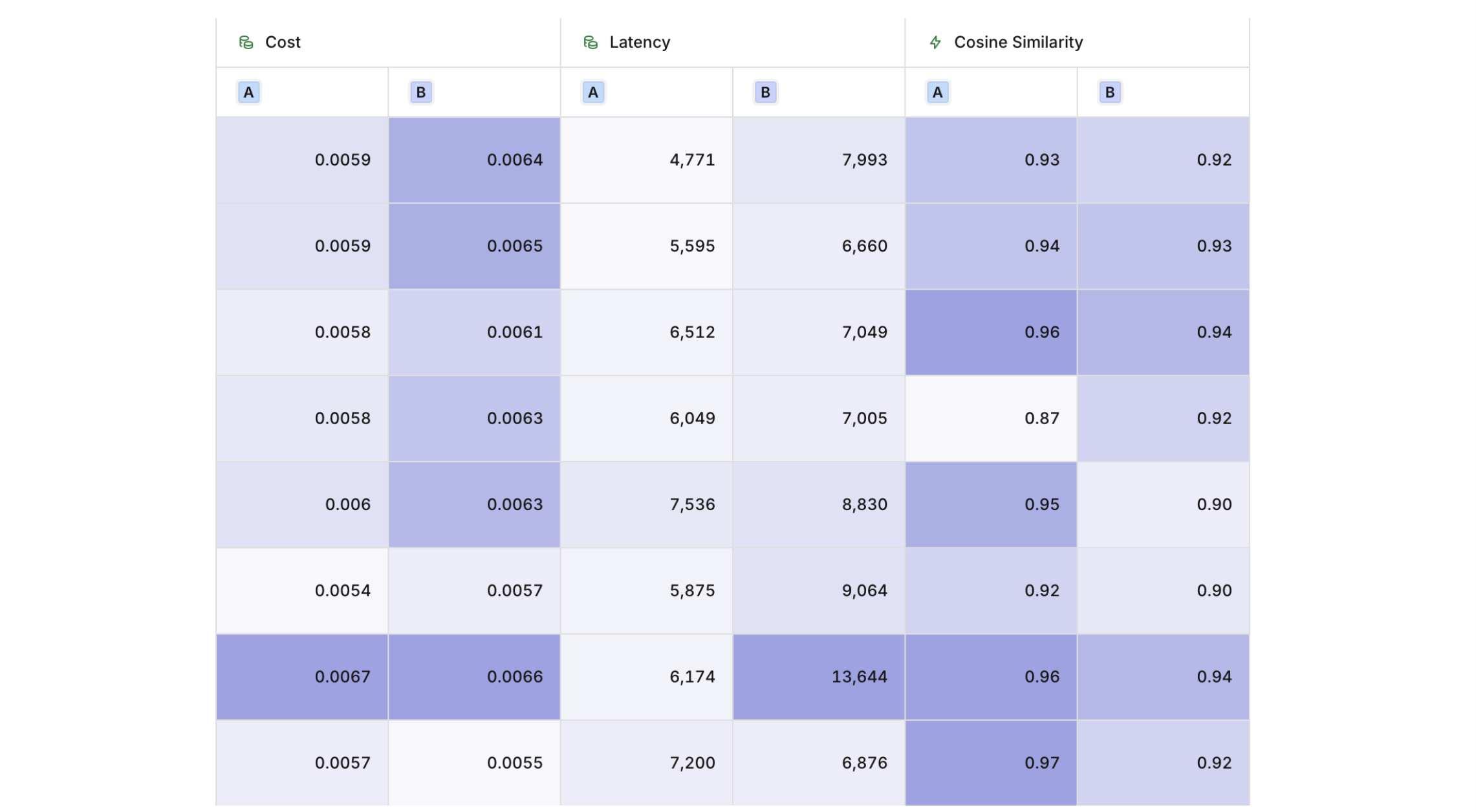
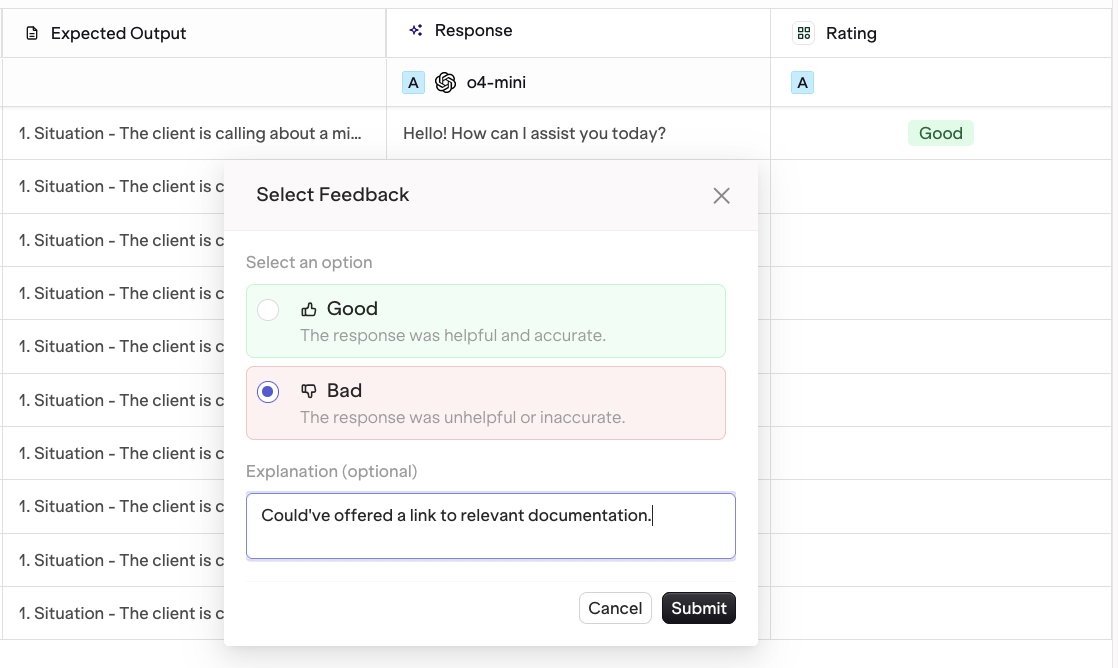
Configuring Human Reviews
Human Reviews are manual reviews for generated texts to help you classify and rate outputs following your own characteristics. They can be added to your experiment to extend reviews. To add a new Human Review, find the Human Review panel, choose Add Human Review, you can then add an existing Human Review to the experiment.To learn more about Human Review and how to create them, see Human Reviews.
Using Vision in Experiments
To run an Experiment with images and a vision model, use an image-based dataset. Add your images directly as image message blocks in the dataset. Do not pass base64-encoded image data through prompt variables.For detailed instructions on creating datasets with images, see Creating an Image Dataset.
Running an Experiment
Once configured, you can run the Experiment using the Run button. Depending on the Dataset size it may take a few minutes to run all model prompts generations. Once successful your Experiment Run Status will change to Completed. You can then see Experiment Results.Only Evaluating Existing Dataset Outputs
If you want to test evaluators on datasets that already contain generated responses, you can run an evaluation-only experiment:- Set up your experiment with the dataset containing existing outputs in the “messages” column
- Do not select a prompt during experiment setup
- Add your desired evaluators
- Run the experiment
To run another iteration of the Experiment, with different prompts or data, use the New Run button. A new Experiment Run will be created in Draft state.
Running a single Prompt
It is often useful to add an extra prompt after running an experiment, to tweak a configuration or try a different version. Once a new Prompt is added, select and choose Run to run on the existing Dataset.
Partial Runs
By hovering on a single cell, you can use the icon to re-run a single prompt over a specific Dataset row.

Running Extra Evaluators and Human Reviews
After an Experiment has run, it is possible to add extra Evaluators or Human Reviews. These newly added columns can then be run separately from the main experiment run, this lets you review the previously executed model generations easily.
Seeing Experiment Results
Once an Experiment is run, its status will change from Running to Completed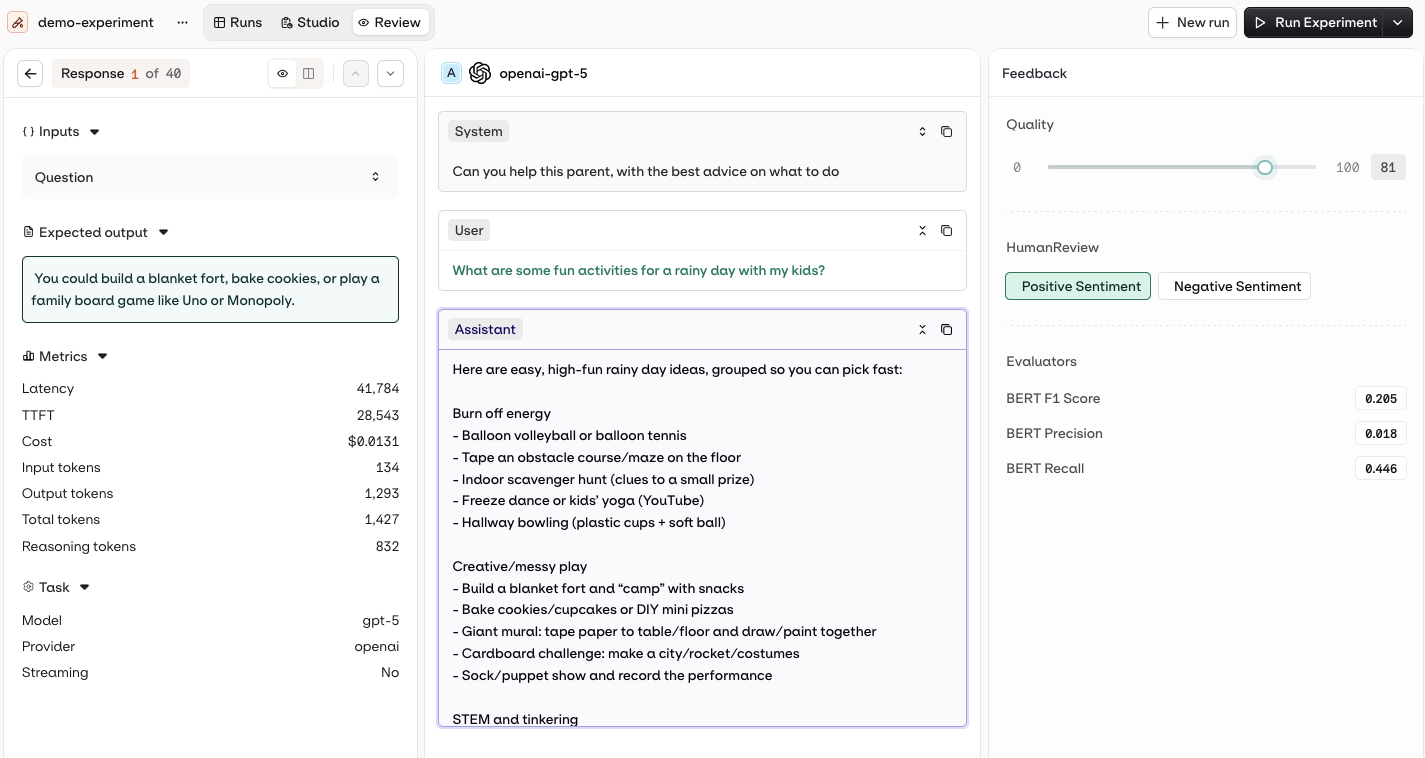
Review a Model Execution
The Review mode displays responses individually, allowing you to inspect each model output in detail, and see the following:- Inputs & Outputs: Full conversation context with system prompts, user messages, and model responses
- Metrics:
- Latency and TTFT (Time To First Token)
- Detailed token usage breakdown: Input tokens, Output tokens, Reasoning tokens, and Total tokens
- Cost information
- Model and provider details
- Streaming status
- Human Review and Feedback: Rate and provide feedback on model outputs
- Defects & Evaluators: View automated evaluation results and identify quality issues
Annotations and human reviews can only be added in the Review tab. The Comparison mode is read-only and designed for viewing model outputs side-by-side.
Comparing Model Performance
Using the Compare tab, visualize multiple model executions.
The Compare screen is read-only. To annotate responses or add Human Reviews, use the Review tab.
Viewing Tool Call History
When viewing a model execution, see the step-by-step execution of the model and its tool calls. In these threads you can see the details of the tool calls, including the fetched tool and payloads sent and received from the call.To learn more about configuring tool calls in your Experiment, see Tool Calls for Prompts.

Viewing Multiple Experiment Runs
Within the Runs tab, visualize all previous runs for an Experiment. Through this view, all Evaluators results are visible at a glance, making it easy to compare result and see progress between multiple Runs.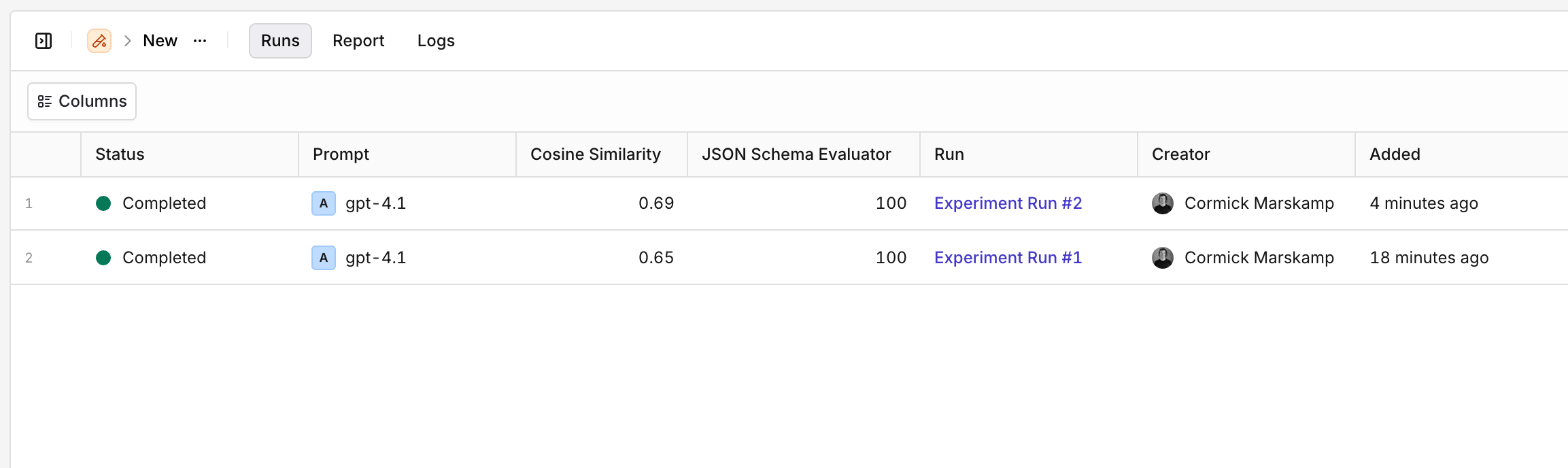
Duplicating an Experiment
To duplicate an existing Experiment with all its configurations (dataset, prompts, evaluators, etc.):- Open the Experiment you want to duplicate
- Click the menu in the top-right corner
- Select Duplicate
- Provide a new name for the duplicated Experiment
- Click Confirm to create the duplicate
Export
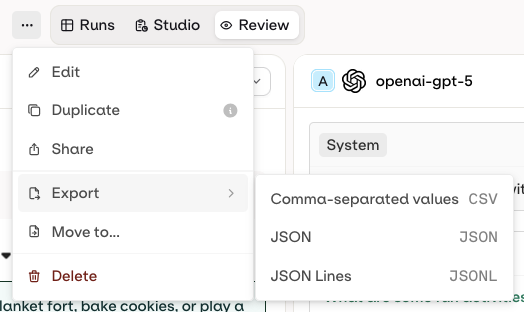
- Datasets
- Model configuration
- Responses
- Metrics (Time to First Token)
- Human Reviews
