

Model Configuration in Orq
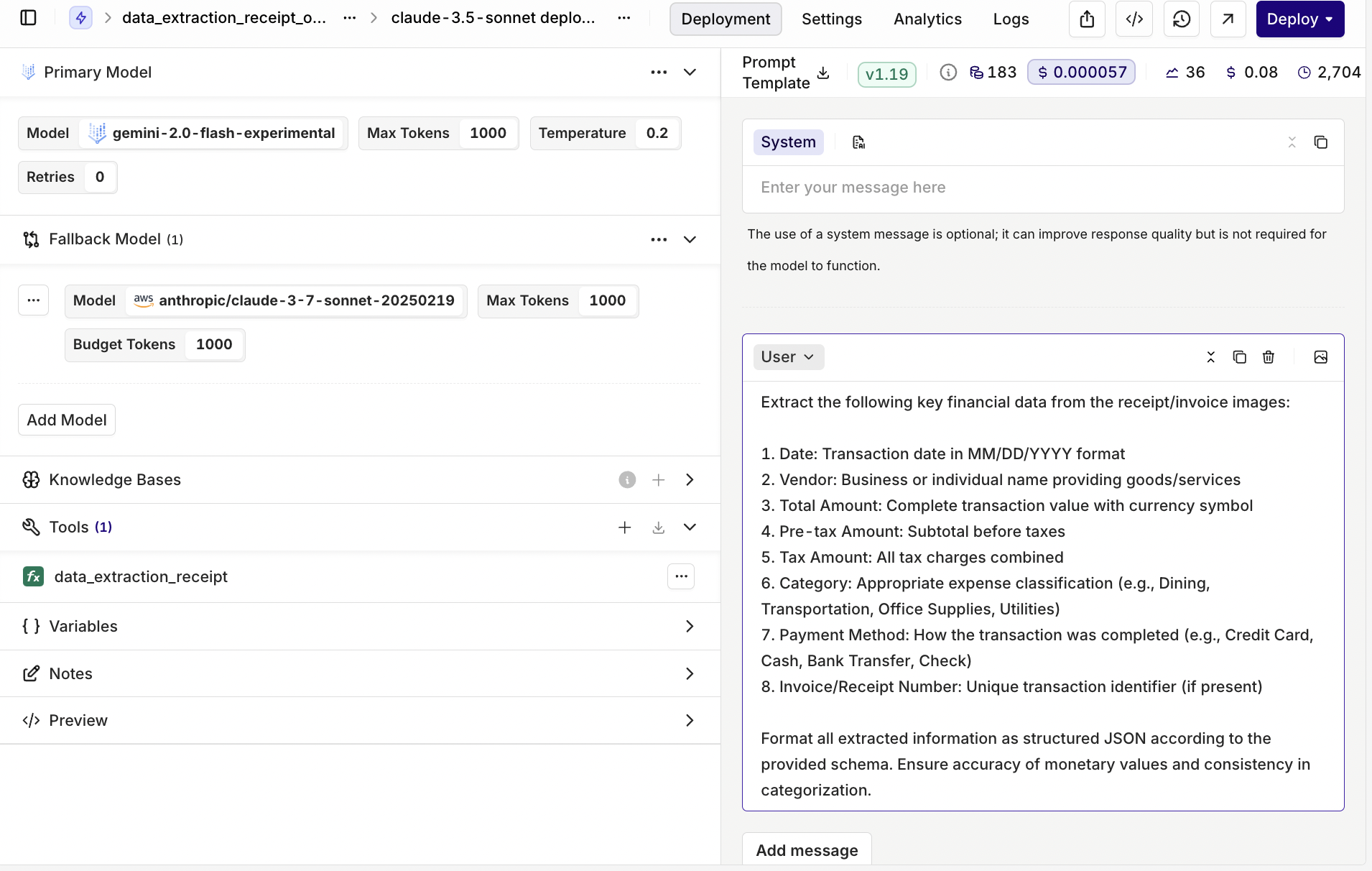
In this Orq model setup, we’re usingGemini-2.0-Flash-Experimental as the primary model for fast and efficient data extraction, with Claude-3.7-Sonnet as a heavier and more expensive model as fallback—just in case things don’t go as planned. This way, we ensure smooth processing without hiccups.
We’ve set the temperature to 0.2, keeping things precise and predictable. Why? Because when dealing with financial data, we don’t want the model getting too creative—we need structured, reliable results that stick to the schema. A lower temperature helps keep responses on track, ensuring accurate extractions every time.
Prompt
To achieve accurate extraction, we use a well-defined prompt that provides clear instructions on identifying key financial details. It specifies exactly what information should be extracted: transaction date, vendor name, amounts (total, pre-tax, and tax), and payment details. By explicitly requesting tax type differentiation and category classification, the prompt ensures a granular and precise extraction.Tools
To keep things structured, we use a JSON schema as our data blueprint. This schema acts as a quality control tool, ensuring that all extracted fields are correctly formatted and validated. Beyond just verification, this structured output makes the data programmatically accessible, allowing seamless integration into other systems, automated workflows, or financial analyses (without the need for manual intervention).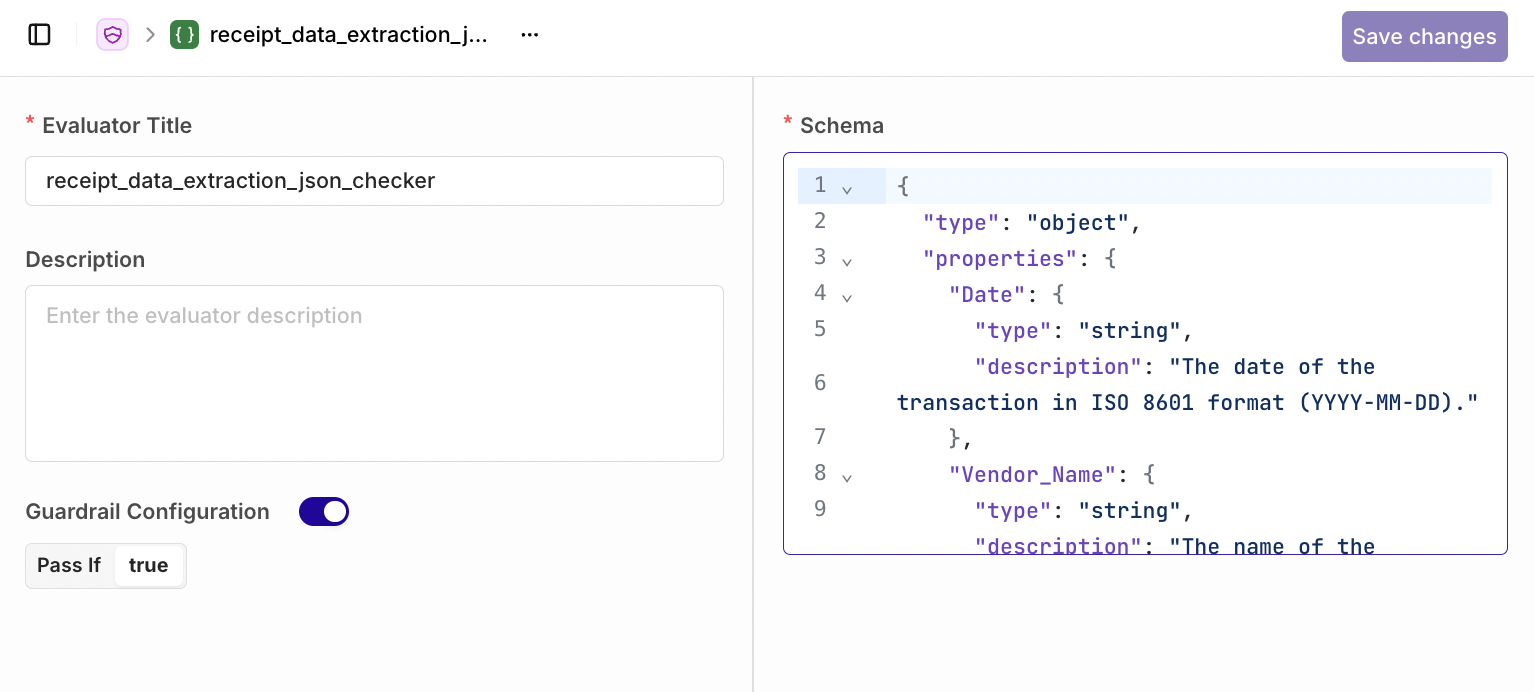
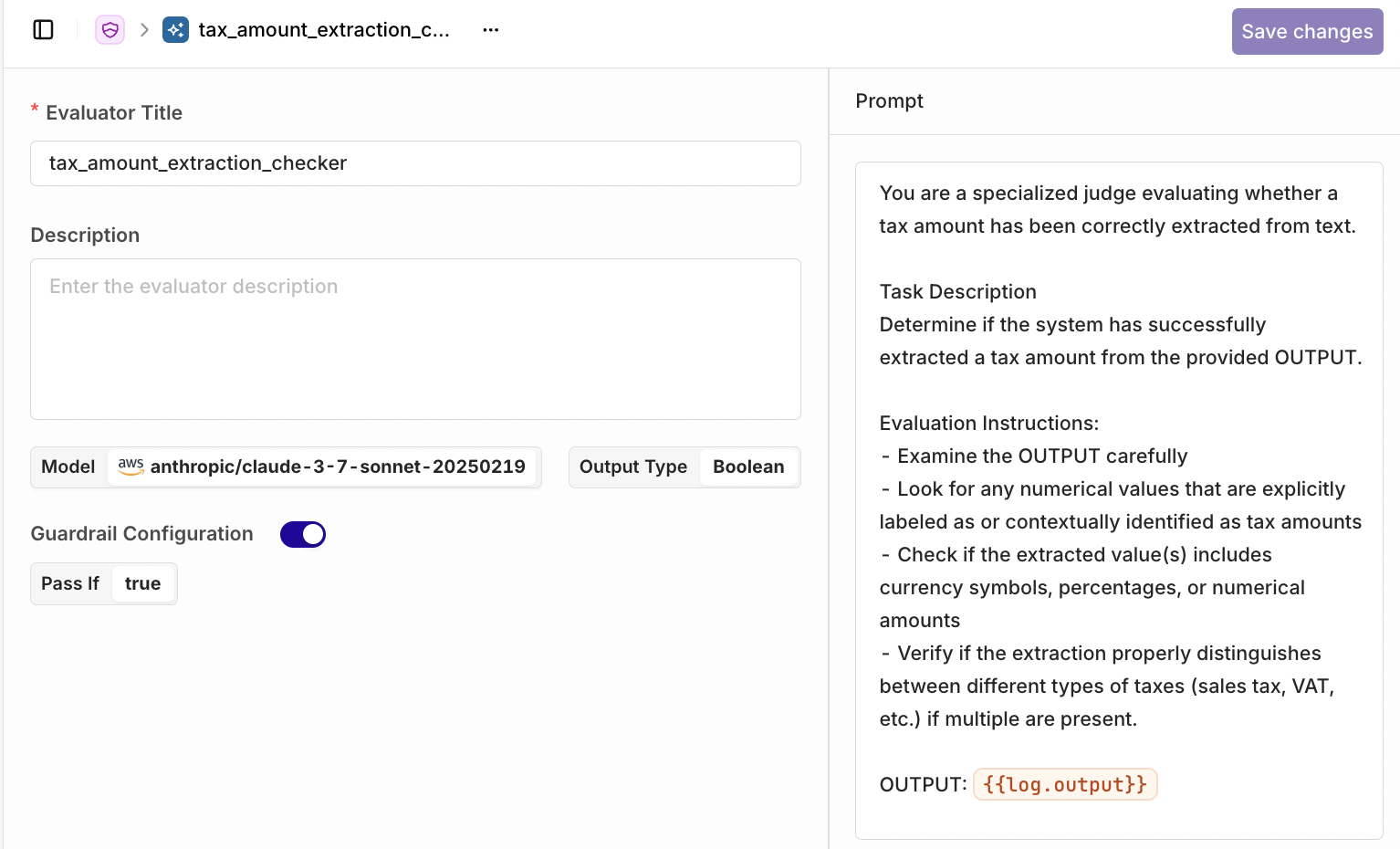
extraction_results, making it ready for further processing, such as financial summarization or validation.
Step 7: Financial Summarization Deployment
The second deployment summarizes the extracted financial data, providing a high-level overview of expenses. It highlights total spending, detects unusual charges, and identifies potential cost-saving opportunities, ensuring a clear and concise financial snapshot.Model Configuration in Orq
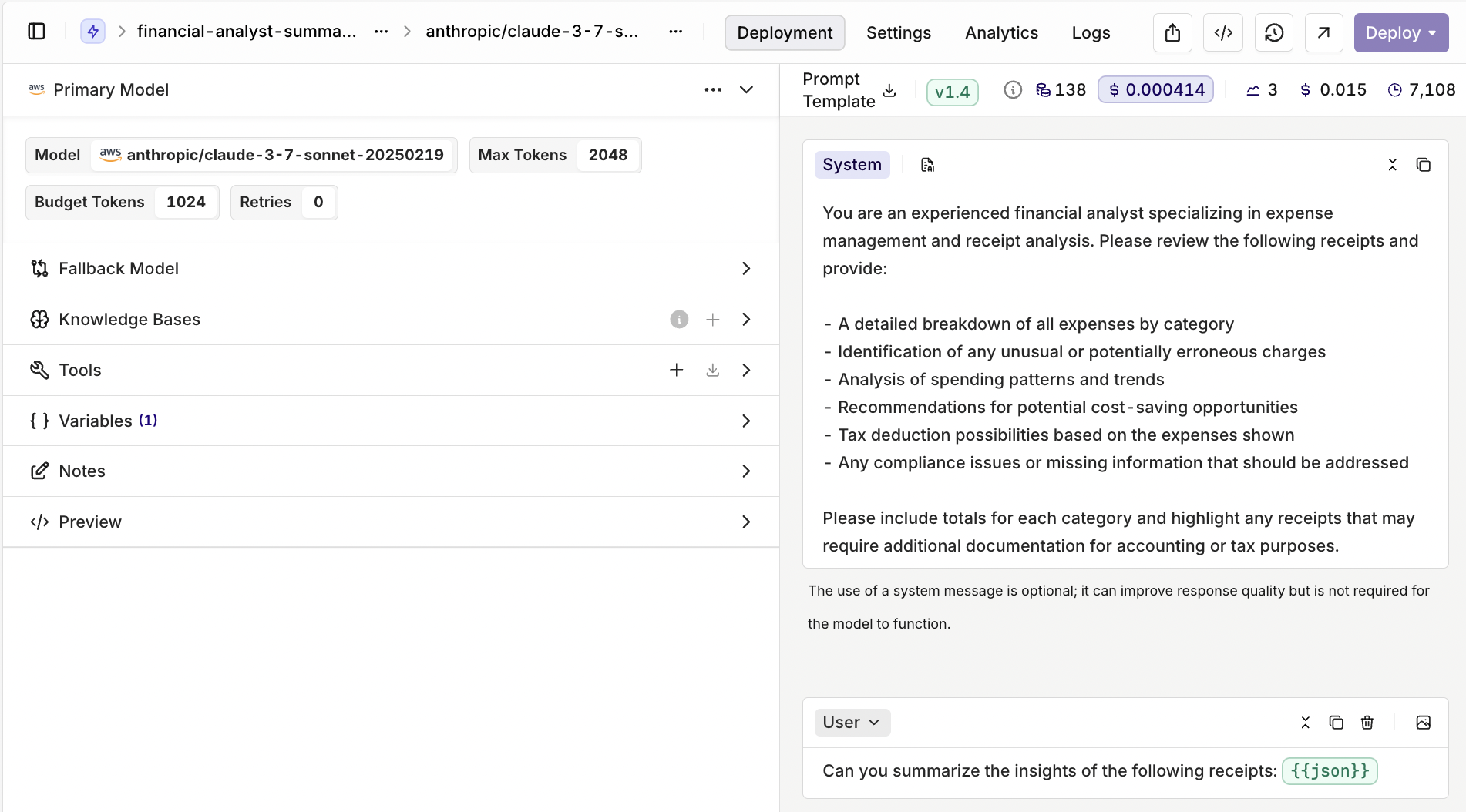
For summarizing all that extracted receipt data, we’re usingClaude 3.5 Haiku as our primary model—it’s fast and efficient. If it ever needs backup, Claude 3.7 Sonnet is ready to jump in as the fallback.
We’ve set the temperature to 0.5, which keeps things balanced—structured enough to stay accurate, but still flexible enough to offer insightful takeaways about spending patterns and tax deductions. The Top P (0.7) and Top K (5) settings make sure responses stay focused and relevant, without the model going off on financial tangents.
Prompt
This prompt guides the model to act as an experienced financial analyst, focusing on expense management and receipt analysis. It goes beyond simple data extraction by requesting a detailed expense breakdown, identification of unusual charges, and an analysis of spending patterns. Additionally, it includes actionable insights, such as cost-saving recommendations, tax deduction opportunities, and compliance checks. By summarising totals for each category and flagging receipts that may need further review, this prompt ensures a comprehensive financial assessment, making it useful for both accounting and tax reporting.Step 8: Passing Extracted Data to the Next Deployment
Here, we invoke the next deployment, using the JSON output from the previous extraction step as input. This ensures a seamless transition between deployments, allowing for structured financial summarization based on the extracted receipt data.- Scale and Adapt: Apply the same principles to process different data types, from text documents to audio transcripts or sensor data.
- Optimize with Evaluations: Run targeted evaluations at key steps to ensure accuracy, detect anomalies, and refine model performance.
- Automate Decision-Making: Use chained deployments to create intelligent workflows that extract, analyze, and act on data with minimal manual intervention.