

Objective
The Simple Deployment architecture provides the most straightforward way to integrate Orq.ai into your application as an AI Gateway. This pattern serves as the primary entry point for routing LLM calls through the Orq.ai platform, enabling you to benefit from unified routing, monitoring, and security features while maintaining a clean separation between your application logic and AI model configurations.To orchestrate multiple Deployments in application code, see Chaining Deployments.
Use Case
Simple Deployment is ideal for applications that need:- Single Model Integration: Applications requiring one primary LLM interaction pattern.
- Straightforward AI Features: Chat interfaces, content generation, text processing workflows, and classification tasks.
- Rapid Prototyping: Quick integration for testing AI capabilities in existing systems.
- Centralized Management: Teams wanting to manage AI configurations outside of application code.
Prerequisites
Before configuring a Simple Deployment, ensure you have:- Orq.ai Account: Active workspace in the AI Studio.
- API Access: Valid API key from Workspace Settings > API Keys.
- Model Access: At least one model enabled in the AI Gateway, see Using the AI Gateway.
Configuring a Deployment
To create a Deployment, head to the AI Studio:- Choose a Project and Folder and select the button.
- Choose Deployment.
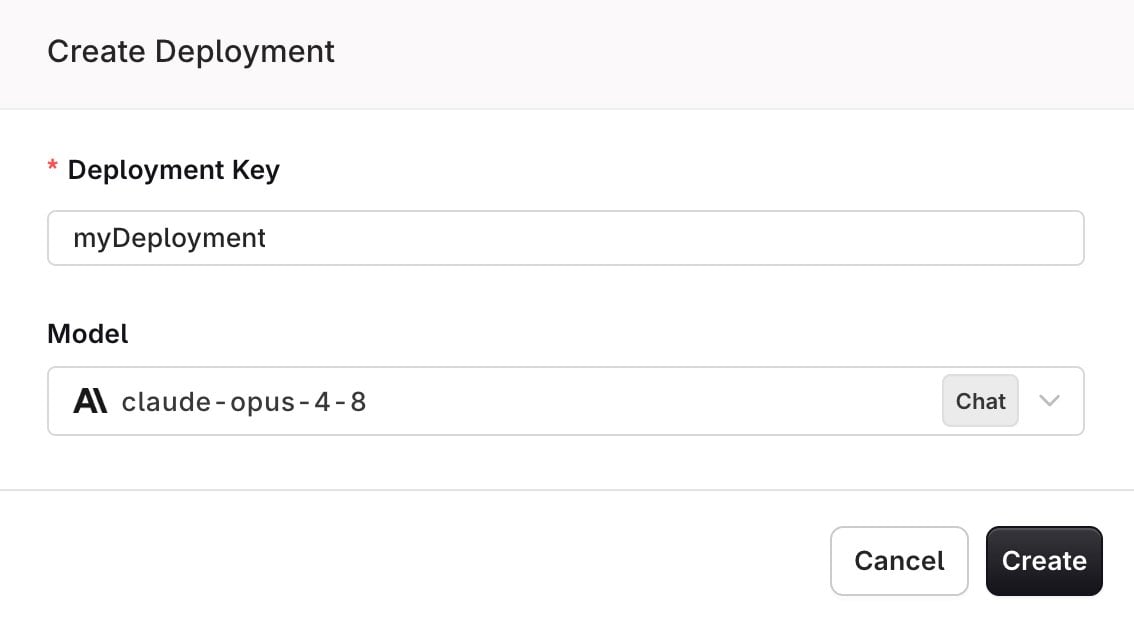
Configuring your Deployment, all parameters can be changed after creation.
Prompting
Configure the Deployment using the Prompt template, or type a prompt directly into the Deployment. There are three message types:- System: Defines what the LLM does, setting its rules and persona.
- User: What the user asks the LLM to do, usually a question.
- Assistant: The LLM’s response.
To learn how to write good prompts, see Prompting.
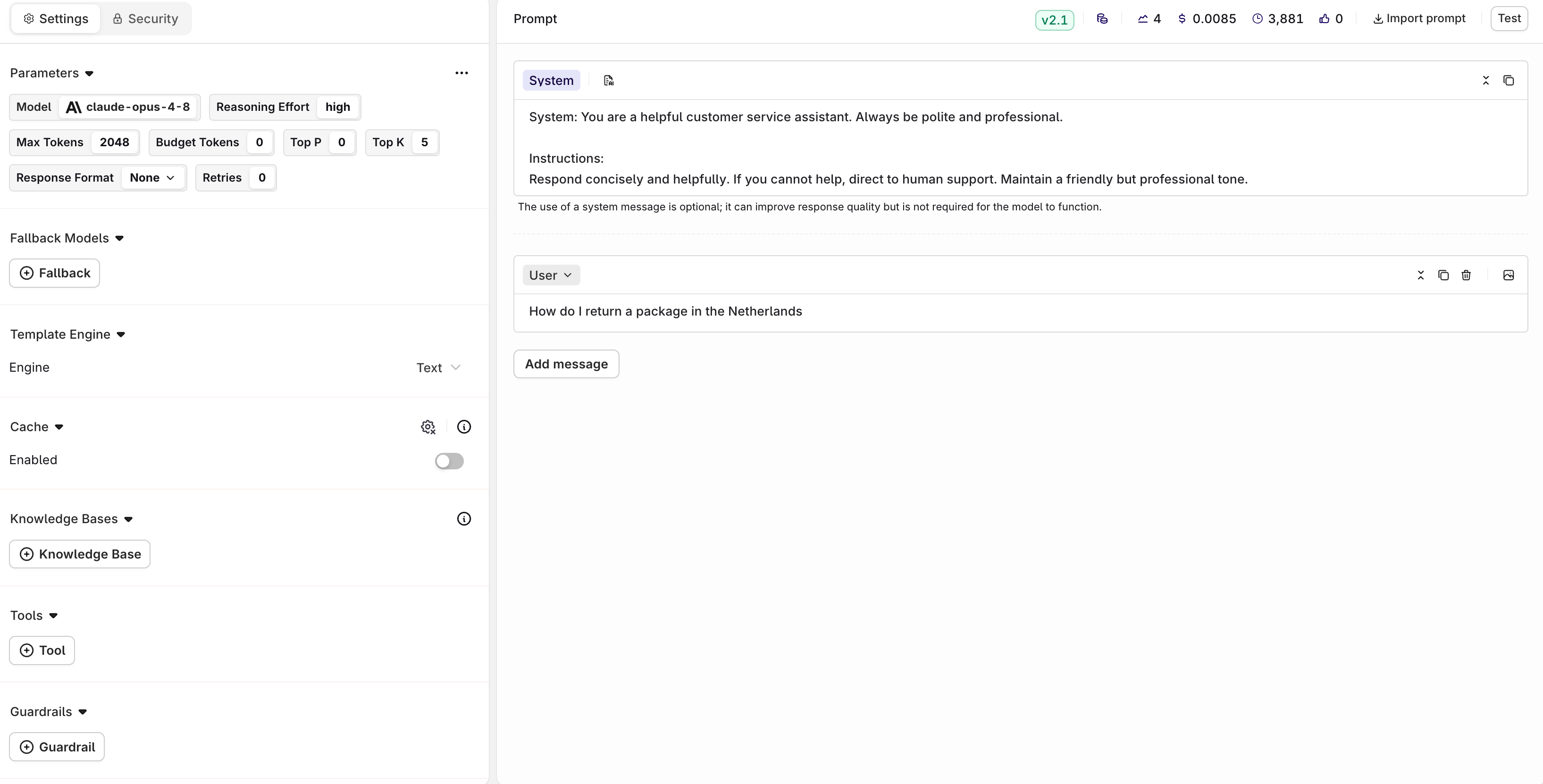
Configure here your model and messages.
Learn more about the possibilities of Prompts in Orq.ai, see Creating a Prompt.
Choose Deploy once ready, this will make your newly created Deployment available through the API.
Integrating with the SDK
Choose your preferred programming language and install the corresponding SDK:Calling the Deployment
To call the Deployment within your integration, use the following calls:To pass messages at request time rather than relying only on the prompt configured in the AI Studio, include the optional
messages parameter in invoke.To learn more about Identities see Track usage by identity.
Viewing Traces
Go to Observability > Traces to see every call made through the Deployment. Click a trace to inspect its span breakdown, including the input, model output, latency, tokens, and cost.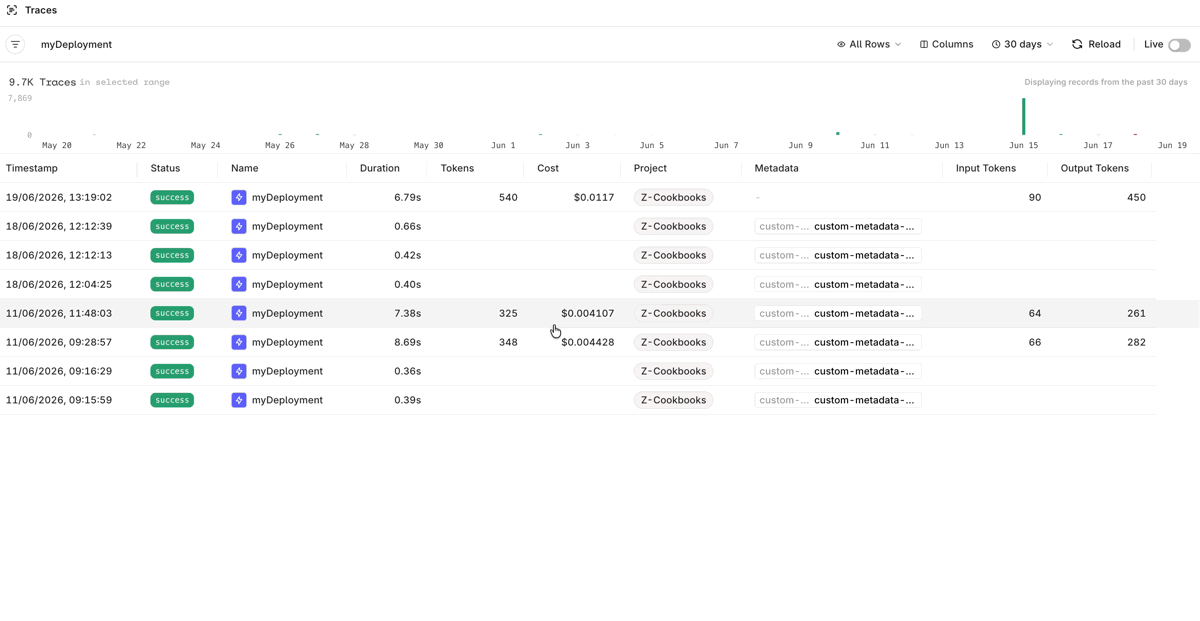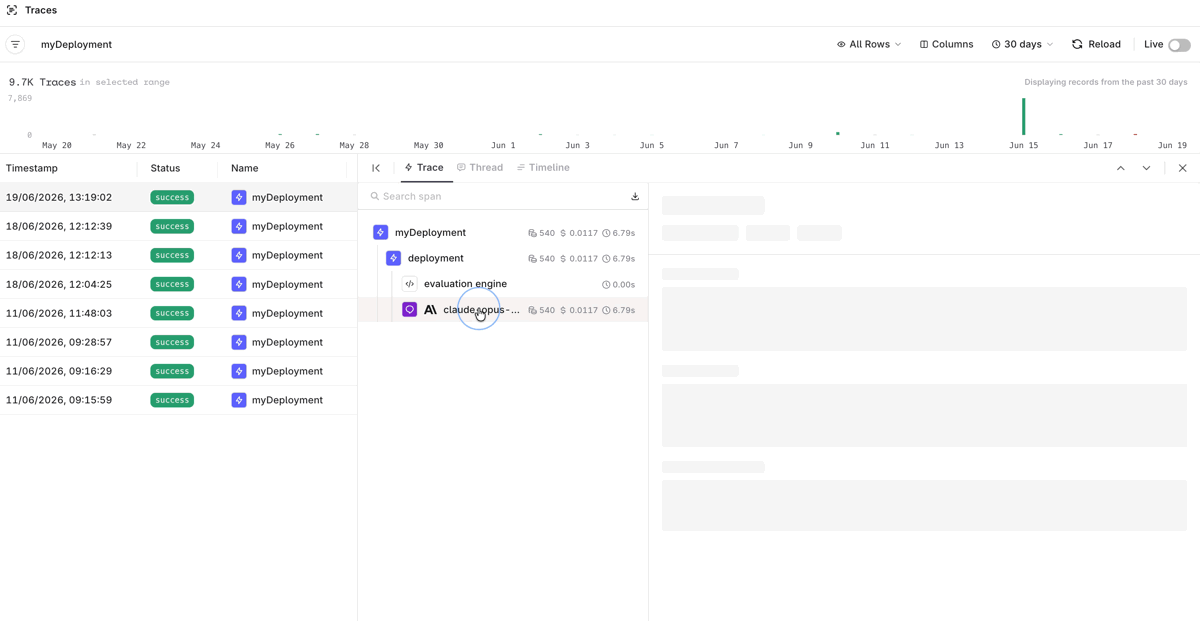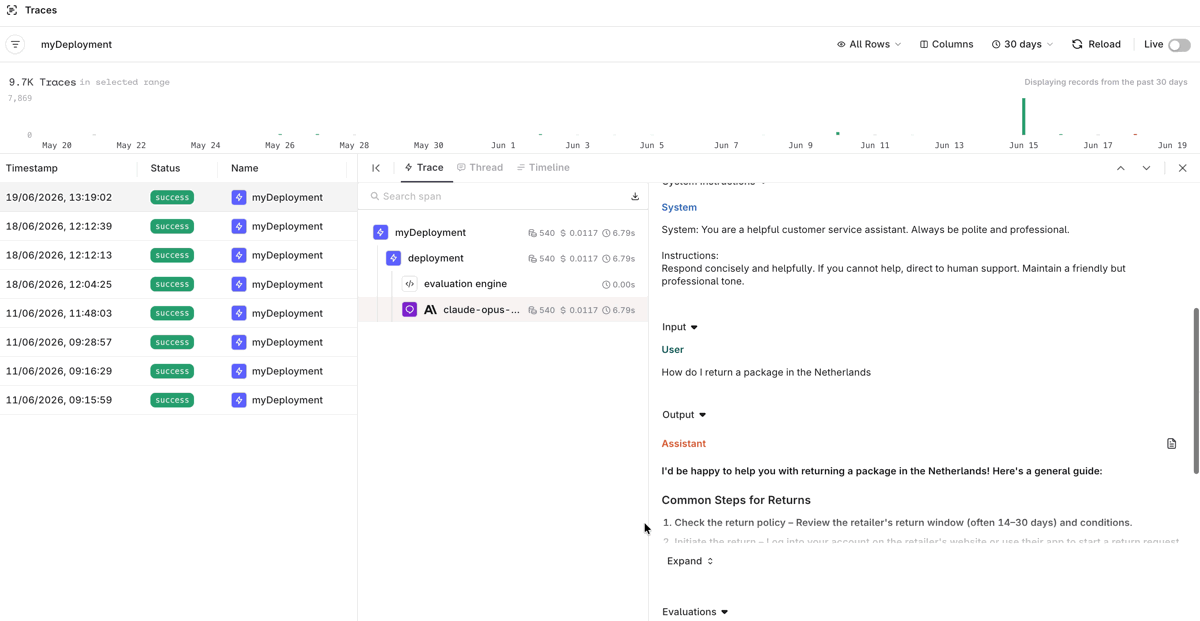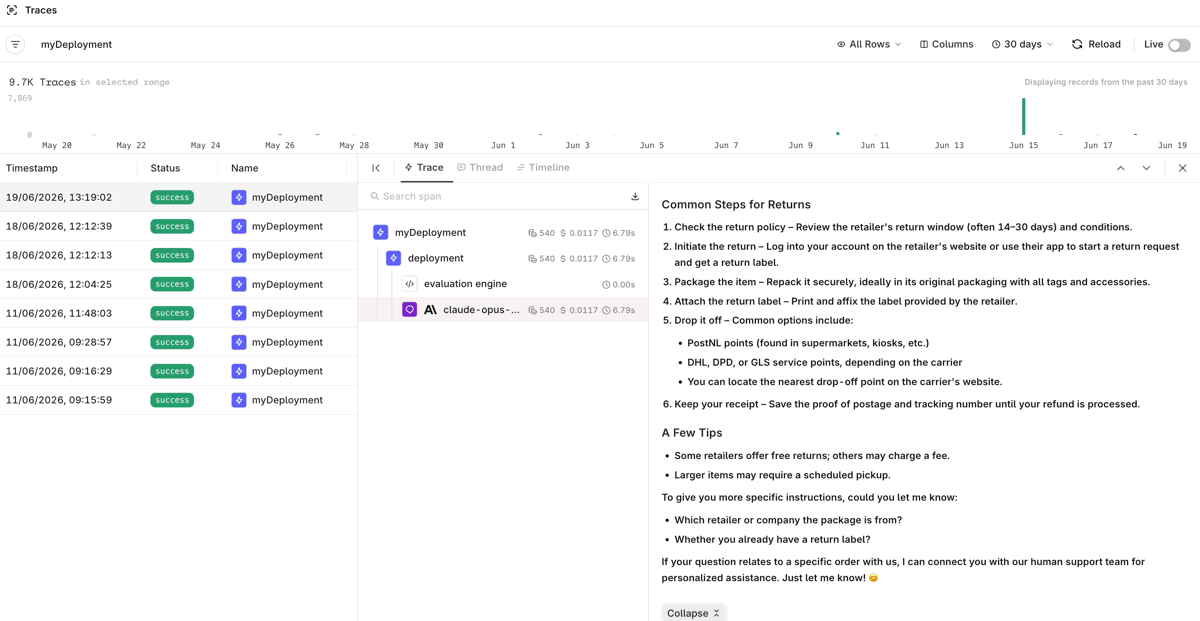
View traces and look at the Deployment calls with span tree and model output details.
To learn more about traces, see Traces.
You completed basic common architecture for a Simple Deployment, explore more of our other Architectures to see more complex architectures.