

Objective
A Simple RAG (Retrieval-Augmented Generation) system provides intelligent information retrieval and answer generation by combining your own knowledge base with large language models. This architecture enables applications to provide accurate, contextual responses based on your specific documents and data while maintaining the natural language capabilities of modern LLMs.Use Case
Simple RAG is ideal for applications that need:- Document-Based Q&A: Answer questions based on company documents, manuals, or knowledge repositories.
- Internal Knowledge Search: Help employees find information from internal wikis, policies, or procedures.
- Customer Support: Provide accurate answers based on product documentation and support materials.
- Domain-Specific Information: Reduce hallucinations by grounding responses in verified company data.
- Contextual Responses: Generate answers that reference specific sources and maintain accuracy.
Prerequisite
Before configuring a Simple RAG, ensure you have:- Orq.ai Account: Active workspace in the AI Studio.
- API Access: Valid API key from Workspace Settings > API Keys.
- Model Access: At least one text generation model enabled in the AI Gateway, such as
gpt-5.4,claude-sonnet-4-6, orgpt-5.4-mini. - Embedding Model: At least one embedding model enabled for knowledge base functionality, such as
text-embedding-ada-002ortext-embedding-3-small. - Source Documents: PDF, TXT, DOCX, CSV, or XML files containing your knowledge base content (max 10MB per file).
- API & SDK
 AI Studio
AI Studio
Set up SDKChoose a programming language and install the corresponding SDK:Initialize the SDK as follows:Creating a Knowledge BaseBegin by creating a knowledge base. The Save the Chunk the Text and Add It to the DatasourceThis is the core of the pattern, in two parts: chunk the text with the Chunking API, then add the returned chunks to the datasource.Chunking is the single biggest lever on retrieval quality. Splitting the text directly puts the strategy and chunk size under direct control instead of relying on a default.The example below uses the Search the Knowledge BaseOnce the chunks are added, search the knowledge base directly to retrieve the most relevant chunks for a query. Orq.ai embeds the query, finds the most similar chunks, and ranks them by similarity.
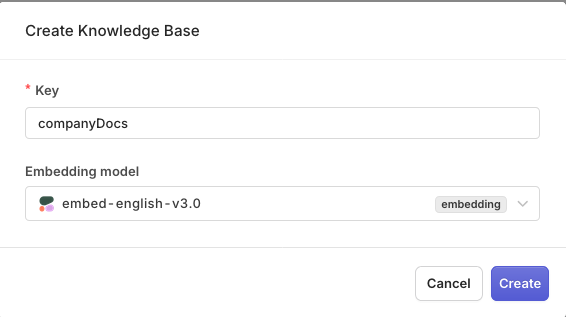
embedding_model uses the provider/model format, and the key is what the deployment prompt references later (use companyDocs to follow this guide).knowledge_id from the response. The datasource step below needs it.Create a datasourceA datasource is the container the chunks live in inside the knowledge base. Because chunks are supplied directly in the next step rather than uploaded as a file, create the datasource empty: give it a display_name and leave file_id out.Passing a file_id here would tell Orq.ai to chunk that file automatically. That is the file-based flow. This guide takes control of chunking instead, so the datasource starts empty.token strategy, which splits purely on token count so every chunk is a predictable size, with chunk_overlap carrying a little context across boundaries. The Chunking API also supports sentence, recursive, semantic, agentic, and fast strategies. For the full list of strategies and parameters, see the Chunking API reference.top_k controls how many chunks are returned, and each match includes the chunk text and relevance scores.For more information on Knowledge Base SDK, see SDK Knowledge.
Configuring a RAG Deployment
A RAG Deployment is a standard Deployment with a Knowledge Base attached. For the full deployment walkthrough, see the Simple Deployment cookbook. The RAG-specific steps are below. To create the Deployment:- Choose a Project and Folder and select the button.
- Choose Deployment.
- Enter name simpleRAG.
- Choose a primary Model.
YAML
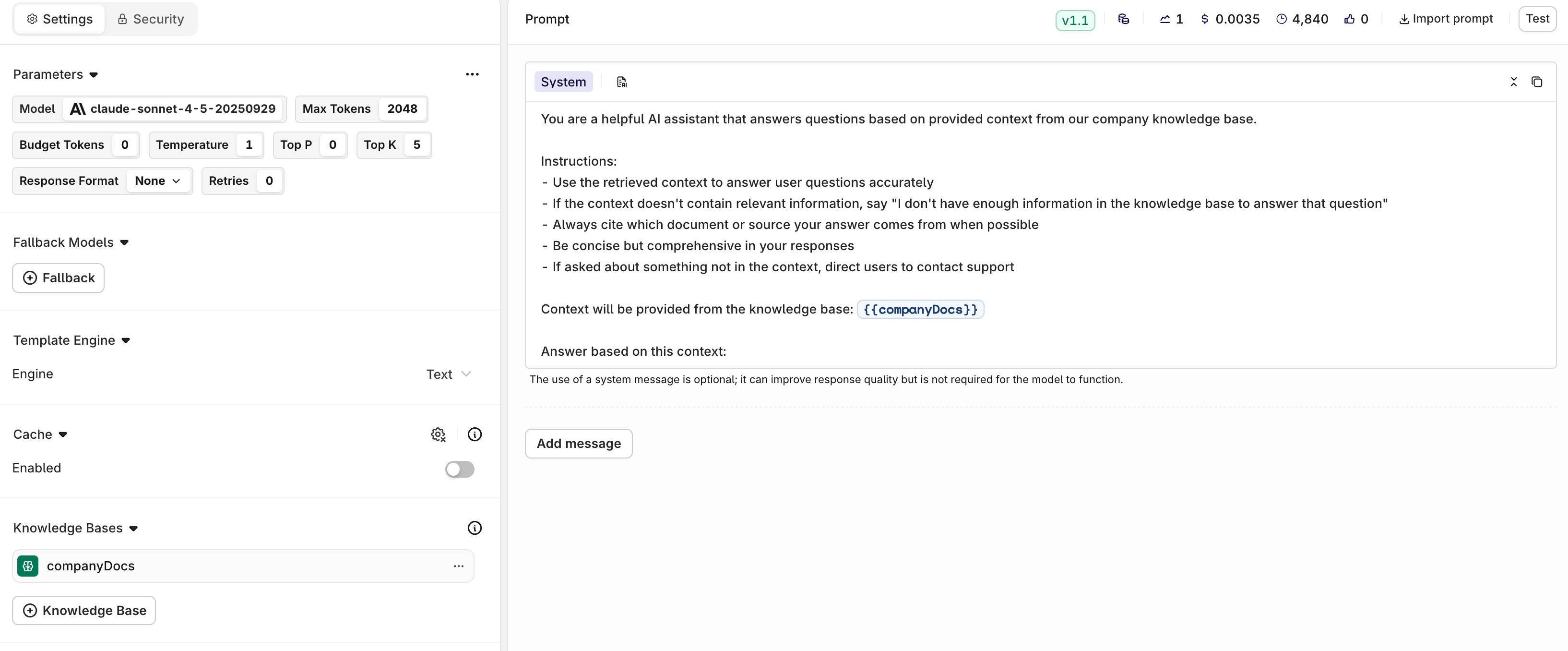
Adding Knowledge Base to Prompt
- Click Add Knowledge Base in the settings of the Deployment.
- Choose the knowledge base key (
companyDocs).
{{companyDocs}} variable in the system prompt must match the Knowledge Base key. Retrieved chunks are injected at that position on each call. If the variable is omitted, the chunks are appended to the end of the system message instead.
Learn more about knowledge base configuration in Knowledge Base, and prompt configuration in Knowledge Base in Deployments.
When ready with your Deployment choose Deploy, learn more about Deployment Versioning.
Calling the Deployment
To implement a RAG-powered question answering system:Viewing Traces
Open the Traces tab on the Deployment page to inspect every call made through the RAG application. Click any trace to see the full span detail: the user’s question, the generated response, retrieved document chunks with relevance scores, and performance timings.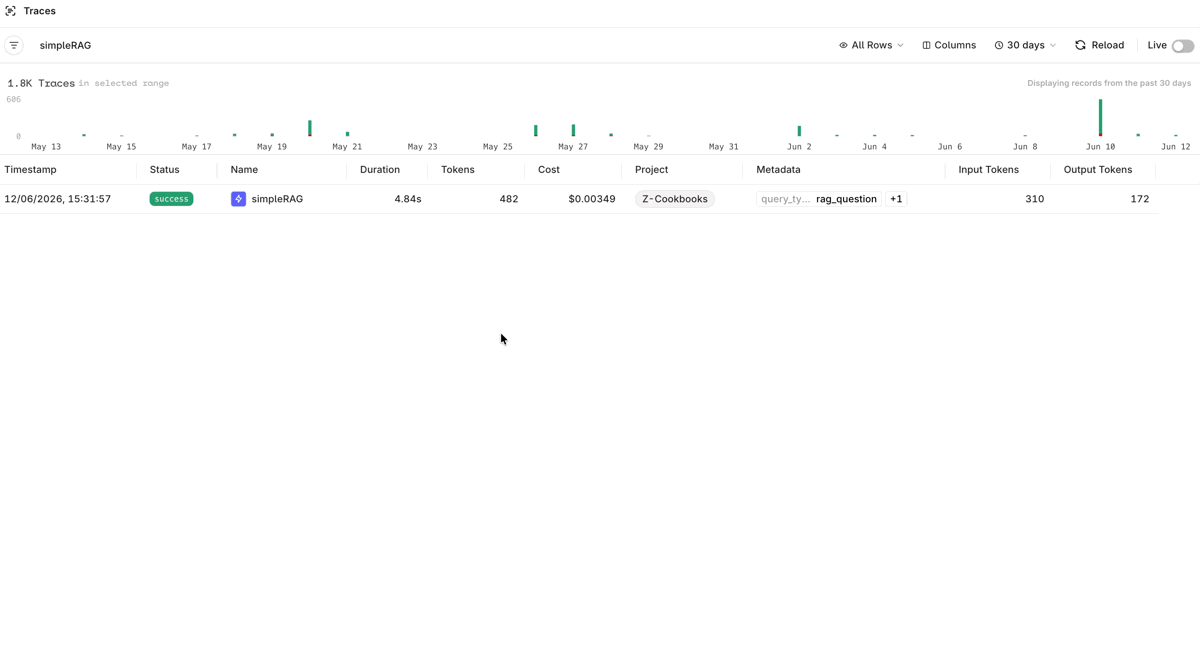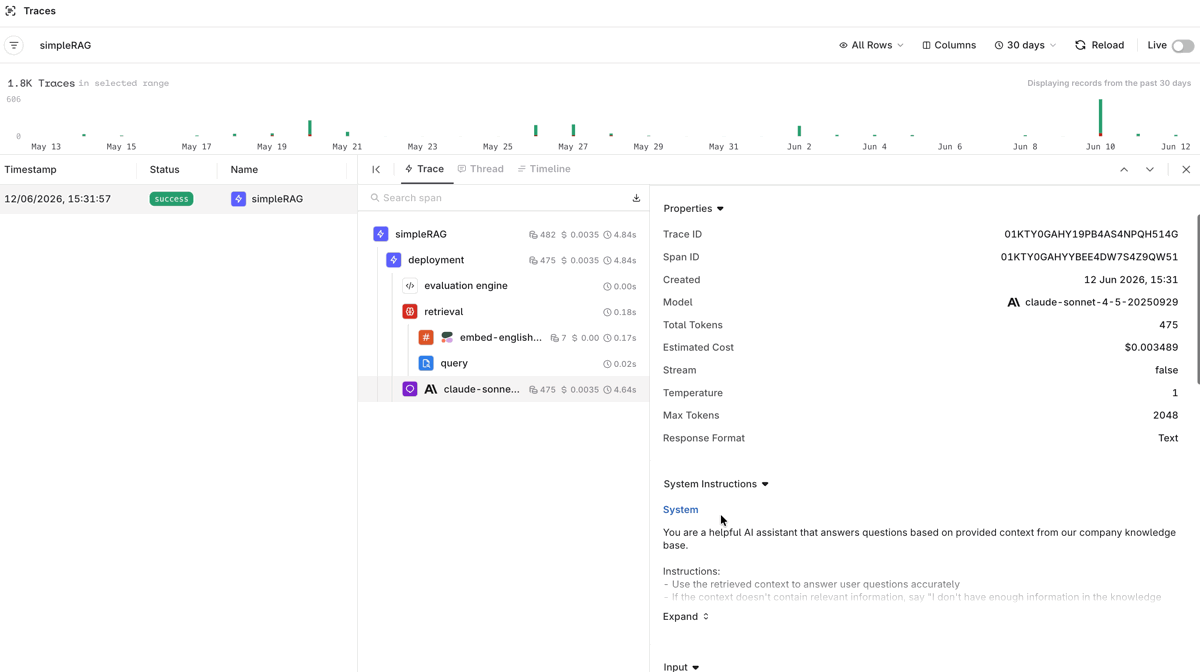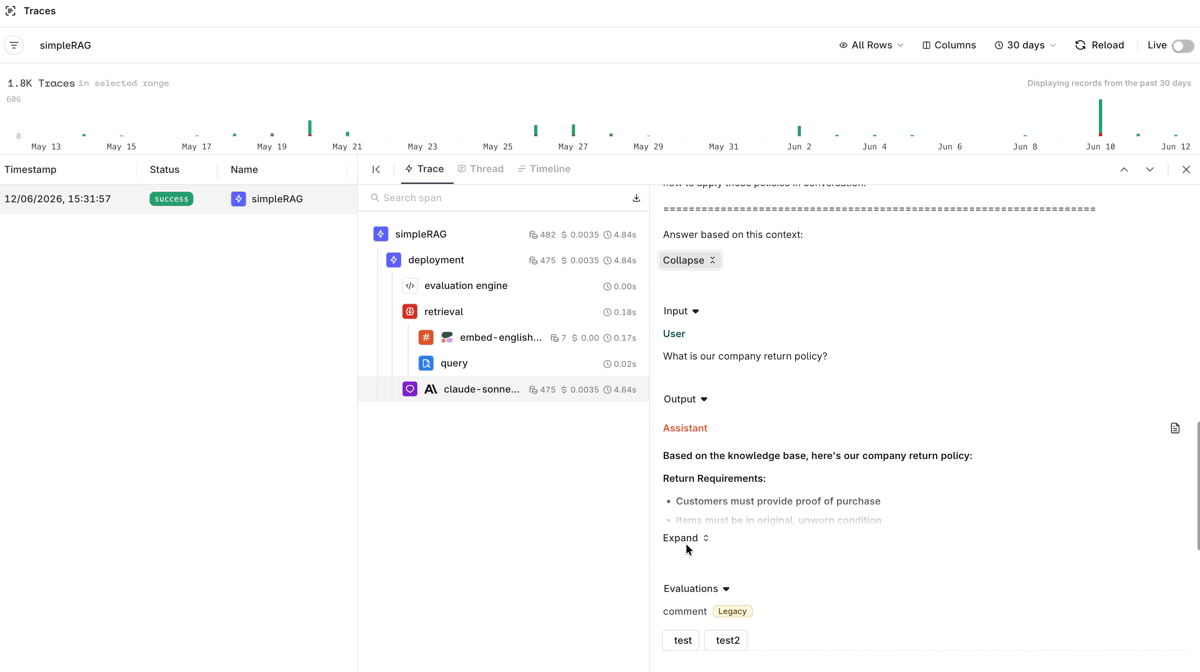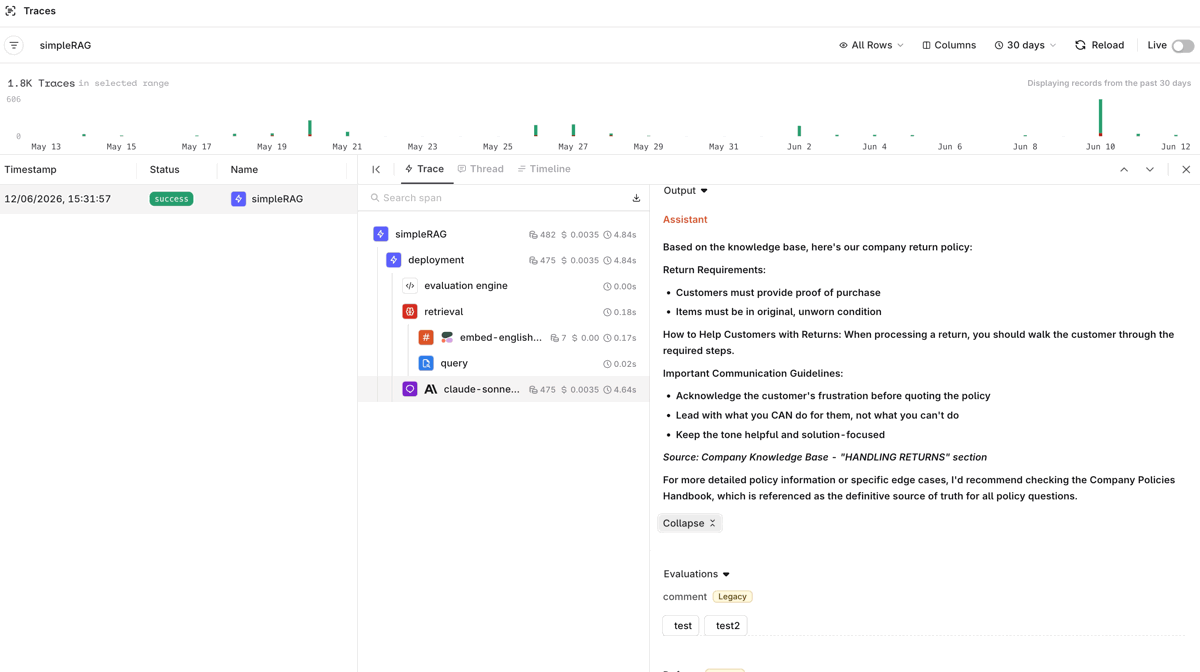
To learn more about Traces see Traces.
You’ve completed the setup for a Simple RAG system. Explore other Common Architecture patterns to see more advanced RAG implementations.