TL;DR
- Run experiments from code to compare any AI system against your evaluation criteria, whether it’s Orq-native or built with LangGraph, CrewAI, or your own custom framework
- Results rendered in Orq’s UI so when experiments complete, prompt engineers can drill into failure points, identify why a version underperforms, and iterate on tool descriptions, agent instructions, or prompts directly in the platform
- Choose your evaluators using Orq’s native evaluation suite or plug in third-party tools like RAGAS and DeepEval
What is Evaluatorq?
Evaluatorq is an evaluation framework for running experiments programmatically, available in both Python and TypeScript. This cookbook focuses on Python. It features the following capabilities:- Define jobs: These are functions that run your model over inputs and produce outputs.
- Parallel evaluations: enabling running multiple jobs (model configurations, deployments, or agents) simultaneously against the same test dataset, then comparing their results side-by-side and decide which configurations will perform best in production.
- Flexible Data Sources: Apply jobs and evaluators over datasets. These could be inline arrays, async sources, or even datasets managed in the Orq.ai platform.
- Type-safe: Built with Python type hints for better IDE support
- Access to experiments from code: Test Orq deployments, Orq agents, or any third-party framework, execute them over datasets, and evaluate results without leaving your IDE. For examples and common patterns, check out the Python Evaluatorq repository
What will we build?
We will build two separate Orq.ai-native Agents using different models that act as cloud engineering consultants, evaluate their performance and challenge them against LangGraph Agent for the following task:Prerequisites
1
Getting started
Install the required packages
2
Set up the Agents
Before we run any evaluations, we need to set up two Agents for comparison to do so:
-
Create a new Project in AI Studio

-
Add Agents to the Project to evaluate
Next, in Python we create two Agent variants to evaluate:
VariantAwith gpt-5-miniVariantBwith claude-sonnet-4.5Agent Variant A (gpt-5-mini)Key Agent variables:key: Unique name of the Agent.path: Path to the Projectdescription: Detailed instructions how an Agent should behavemodel: Foundational model which we will evaluateAgent Variant B (claude-sonnet-4.5)
3
Assessing Agent performance with parallel evaluators
Once we have the Agent variants set up, we’re ready to run parallel evaluations using Evaluatorq. In the Evaluatorq evaluation framework, you’ll notice the following syntax:In the example below we will run four evaluators in parallel:Expected output
@jobdecorator is a wrapper that identifies and names the function as a jobasync def your_evaluatorevaluators are defined as functions
Before running evaluations: You must first create an Orq LLM-as-a-judge Evaluator via the UI or API. Once created, retrieve the Evaluator ID from the URL (e.g.,
https://my.orq.ai/project/evaluators/01KECJTD1GWGF90DMGSP1D8XZN) or via the Get All Evaluators API.Orq also supports custom Python evaluators, JSON-based evaluators, and HTTP evaluators, all invoked via their unique Evaluator ID.- Evaluator 1: Orq LLM-as-a-judge (checks response quality and coherence)
- Evaluator 2: DeepEval Faithfulness
- Evaluator 3: DeepEval Answer Relevancy
- Evaluator 4: Response Length (example of a custom Python script)
Alternative Data Sources: Instead of defining DataPoints inline, you can load data from a CSV file or use Orq-managed Datasets. This is especially useful for running experiments over large evaluation sets.
4
Third-party evaluators
RAGAS
RAGAS
RAGAS (Retrieval Augmented Generation Assessment) is a research-backed evaluation framework specifically designed for RAG systems. It provides both reference-free and reference-based metrics that assess retrieval quality and generation quality using LLM-as-a-judge.Reference-Free Metrics (No Ground Truth Needed):
- Faithfulness: Checks if the response is grounded in the retrieved context
- Answer Relevancy: Checks if the response addresses the query
- Context Precision: Measures if retrieved contexts are relevant to the ground truth
- Context Recall: Measures if all contexts were retrieved compared to ground truth
Before running this example: You must first create an Orq Deployment with a Knowledge Base enabled. Once created, replace
"rag-knowledge-assistant" with your deployment key.DeepEval
DeepEval
DeepEval is a comprehensive open-source LLM evaluation framework that treats AI testing like software unit testing. Built with pytest integration, it provides 15+ evaluation metrics covering RAG systems, chatbots, AI agents, and general LLM outputs.
Orq.ai vs LangGraph Agent
Orq.ai allows you to process third-party agent traces. This evaluation compares two AI agent implementations using GPT-4o model. Both agents act as Cloud Engineering Assistants and are tested on cloud infrastructure questions. Agents tested:LangChain Agent:Direct implementation using LangChain’s ChatOpenAI with custom system promptsOrq Native Agent:Agent deployed through Orq.ai platform with equivalent configuration
DeepEval Faithfulness: Measures how well responses align with provided contextCloud Engineering Relevance: Keyword-based scoring for cloud-specific terminology
1
Set up LangGraph traces in Orq.ai
Follow along the LangGraph vs Orq.ai Agent cell in Google Colab. Variables need to be configured under the
Step 1 section:ORQ_API_KEY - For Orq agent access and telemetry exportOPENAI_API_KEY - For LangChain agent and DeepEval metrics2
Run the evaluators
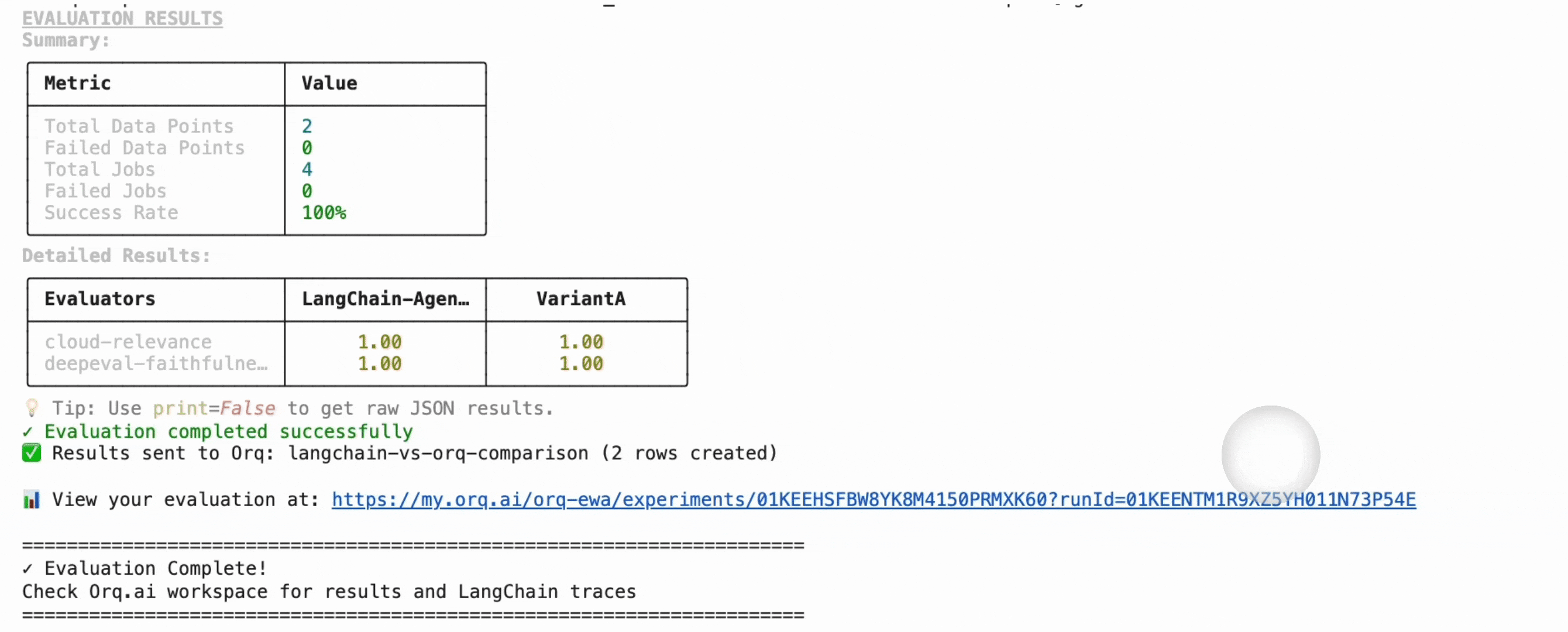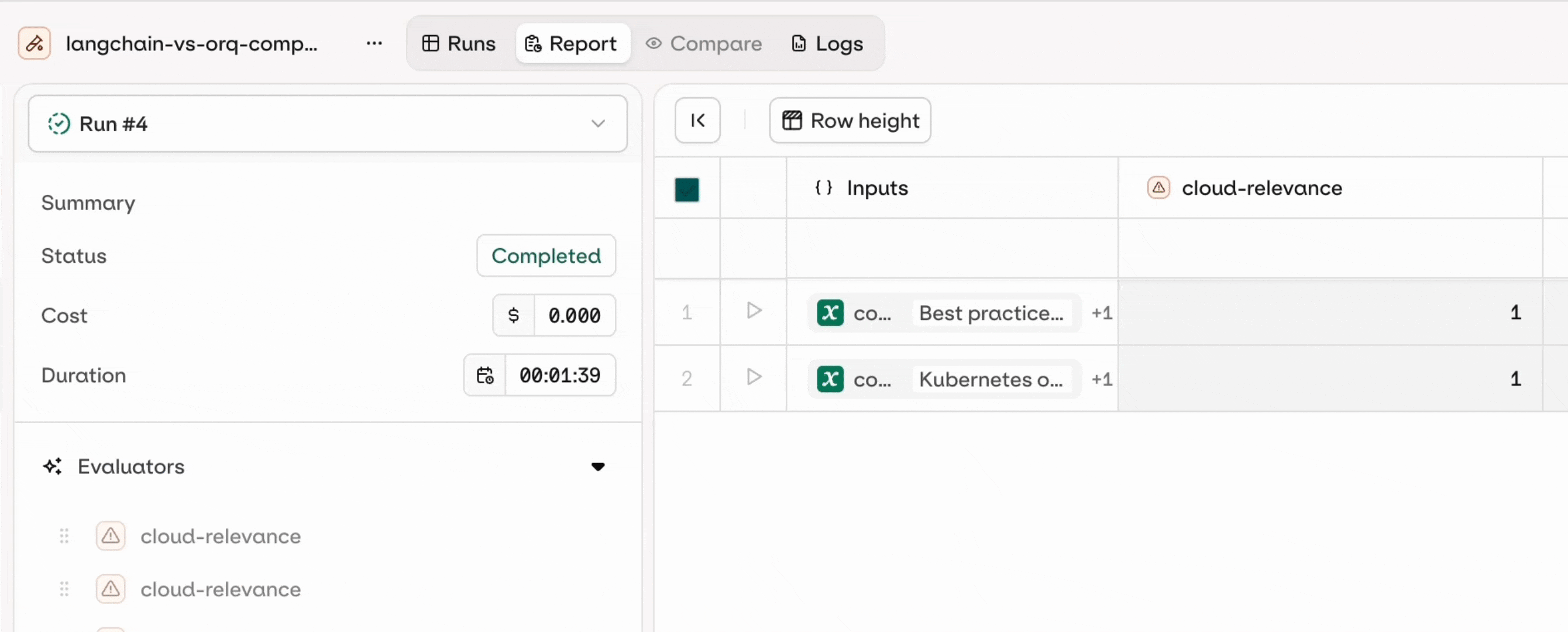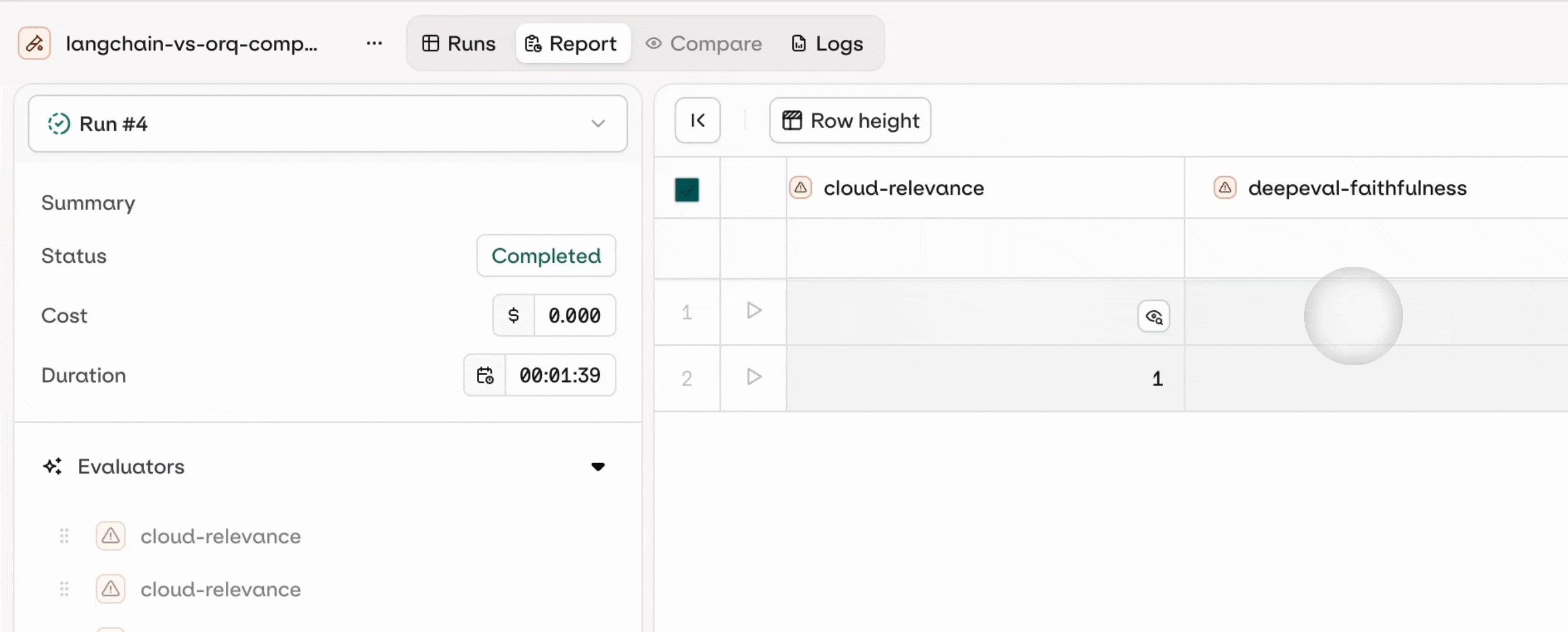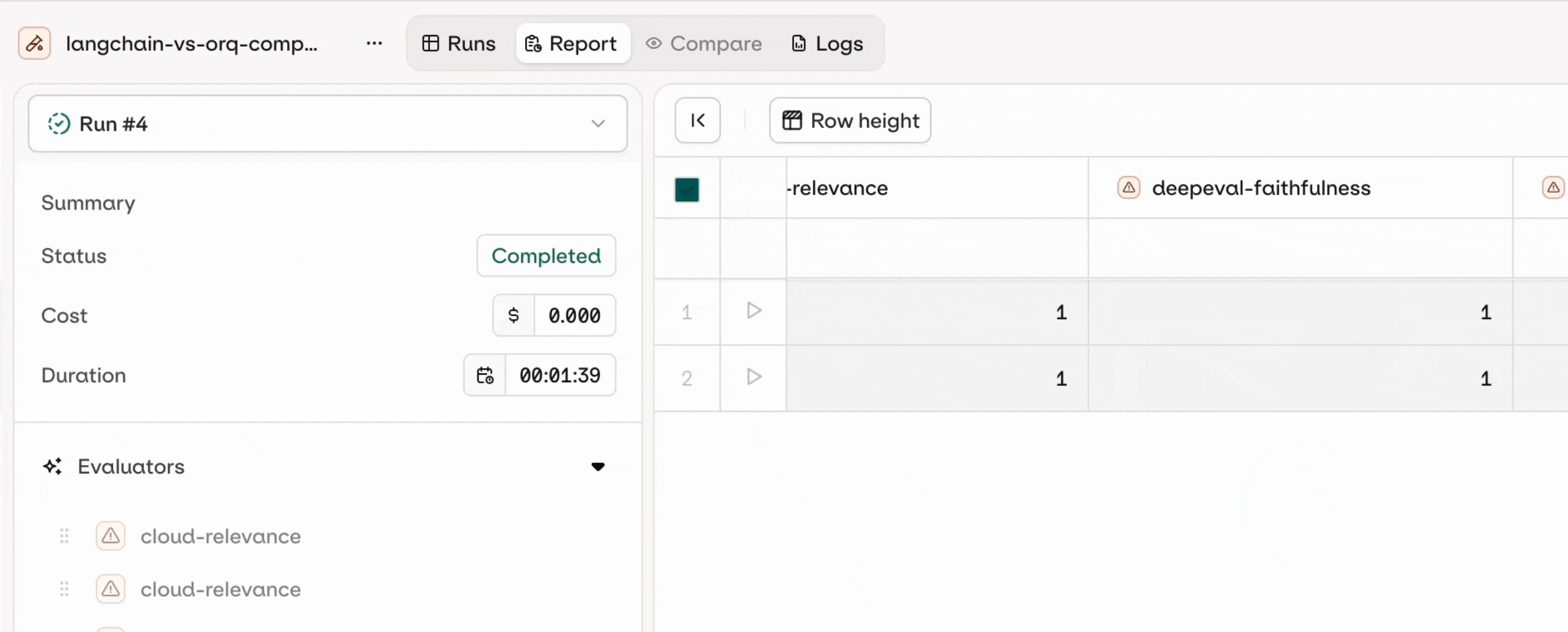
We set up in this step equivalent configurations of LangChain and DeepEval Agents and run two evaluators on the following those steps:Expected Results: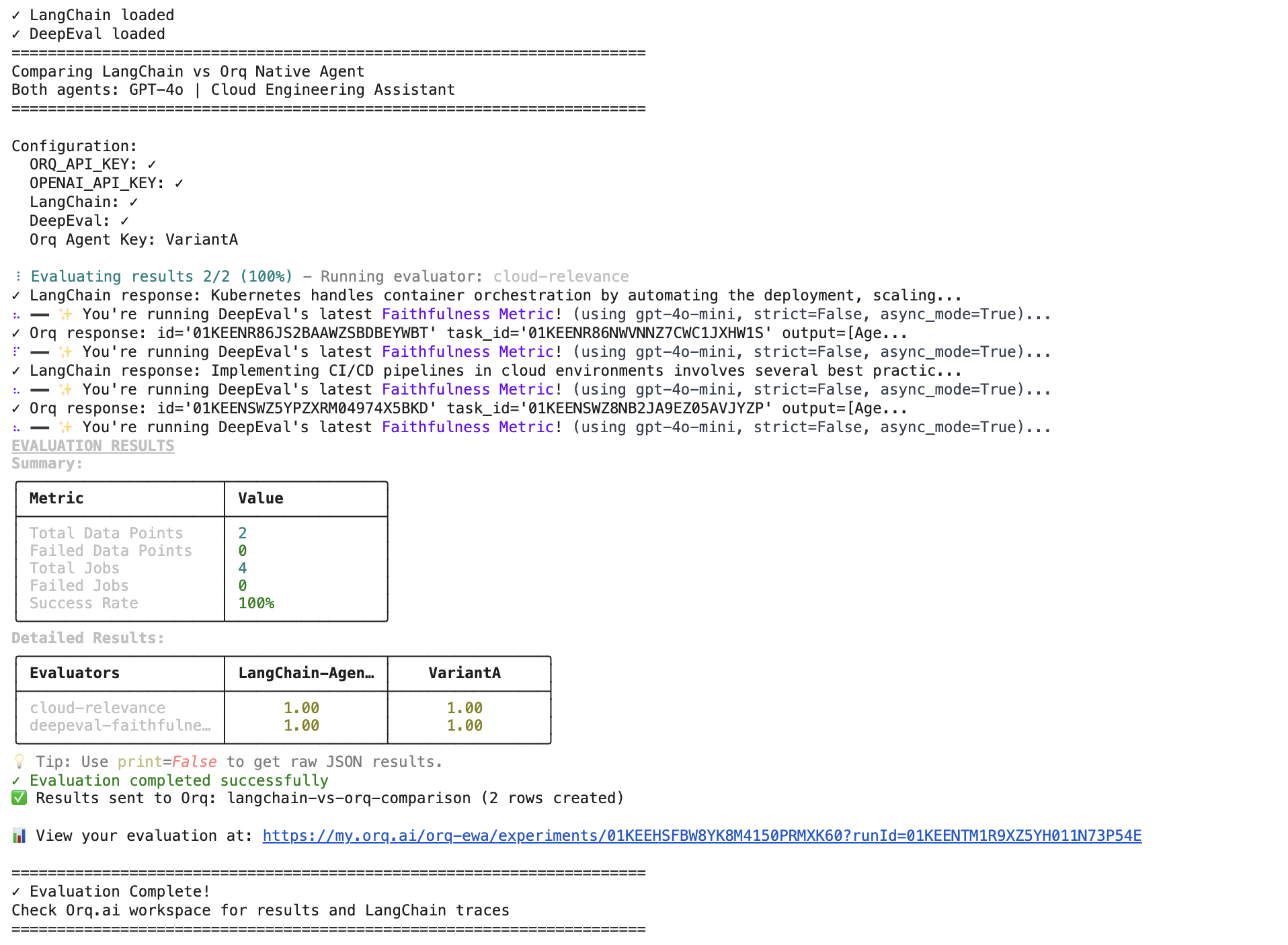
Step 2 - Install and Import LangChainStep 3 - Install and Import DeepEvalStep 4 - Create LangChain Agent (Matching Orq Setup)Step 5 - Call the Orq.ai-native AgentStep 6 - Run DeepEval and Relevance evals3
Preview the results in AI Studio
You can see the results directly in the AI Studio by clicking on the generated link that shows up after you run the agent evaluators: