Setting up a Knowledge Base
Create a knowledge base with any source file to be then searched by models.
Creating a Knowledge Base
To create a new Knowledge Base head to the orq.ai panel.
Use the + button in a chosen Project and select Knowledge Base.
Press Create Knowledge, the following modal will appear:
 and [Deployments](ref:deployments-2). Also enter a **Name** and which **Project** this knowledge belongs in.](https://files.readme.io/73c85744ed55dec5af1da825f903f2fa209d6e3af0d5c4d0618373c9db666193-Screenshot_2024-10-02_at_12.33.56.png)
Here you can enter a unique Key that will be used to reference your Knowledge Base within Playgrounds and Deployments. Also enter a Name and which Project this knowledge belongs in. You can also choose an availabel Embedding Model to use during knowledge search.
You can only create a Knowledge Base once you have activated an embedding model within your Model Garden.
Adding a source
You are then taken to the source management page.
A source represents a document that is loaded within your Knowledge Base. This document's information will then be used when referencing and querying the Knowledge Base.
Documents needs to be loaded ahead of time so that they can be parsed and cut into chunks. Language models will then use the loaded information as source for answering user queries.
To load a new source, select the Add Source button. Here you can add any document of the following format: TXT, PDF, DOCX, CSV, XML.
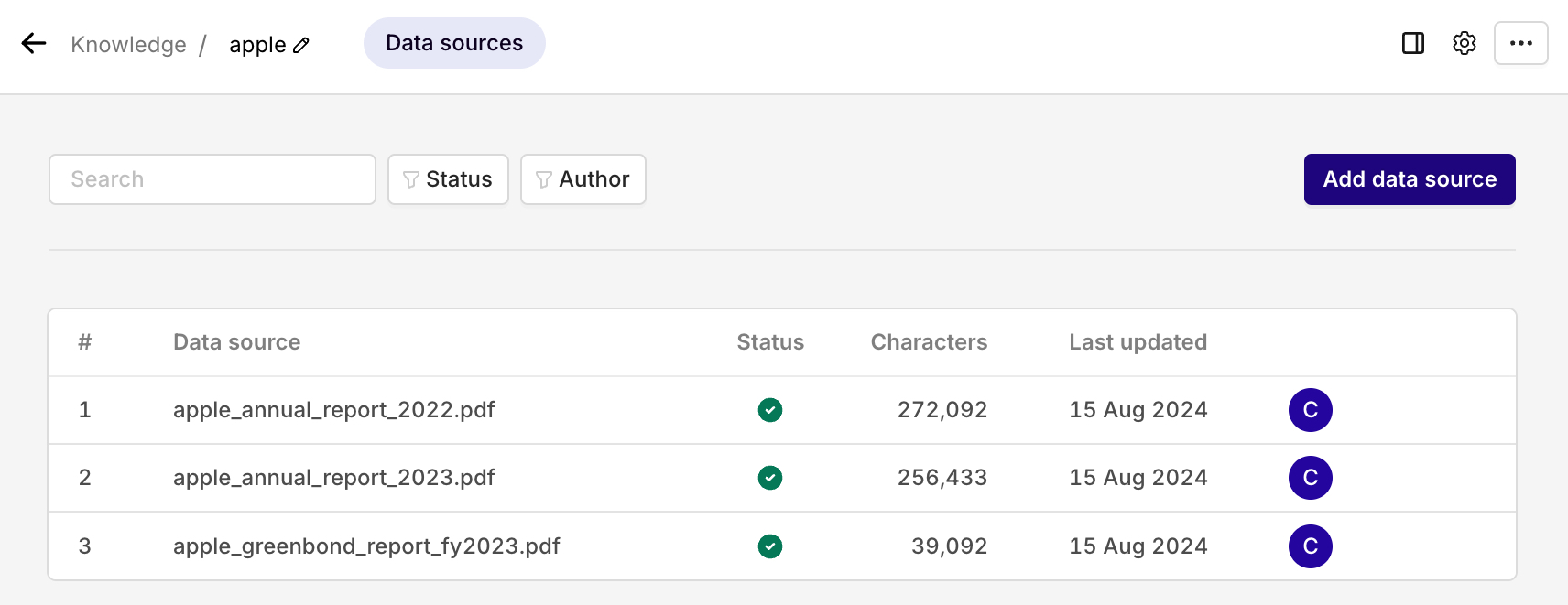
While you can add any number of sources to a Knowledge Base, A single source document must be of a maximum of 10MB.
Once you have selected files from your disk, you will be able to configure how the file is parsed and indexed within the Knowledge Base.
Chunk Setting
Chunks refer to the size of information source documents will be divided in. The bigger chunks the more information they contain, the smaller the chunks the cheaper their transfer costs.
You can configure how you want chunks to be configured for your source, see Chunking strategy.
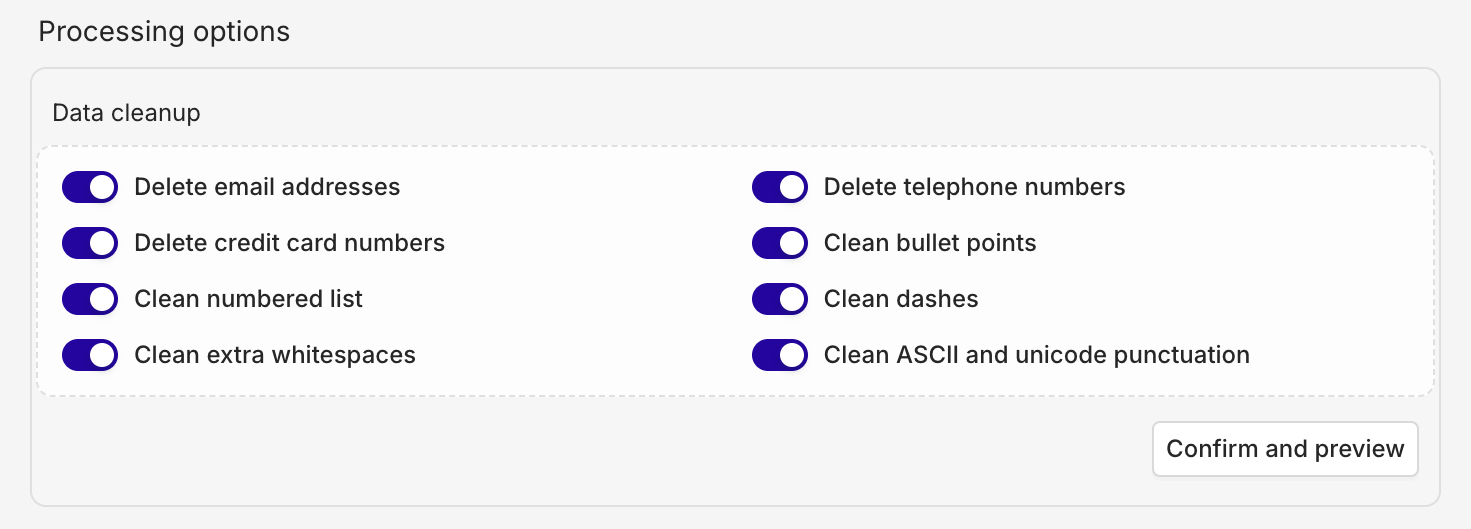
Data Cleanup
You can choose to modify the data loaded within your sources, this can be great to clean the chunks or anonymize data. To activate each cleanup, simply toggle on the option within the data cleanup panel.
Summary and Cost Estimation
Once your document has been processed, the following summary will be displayed:
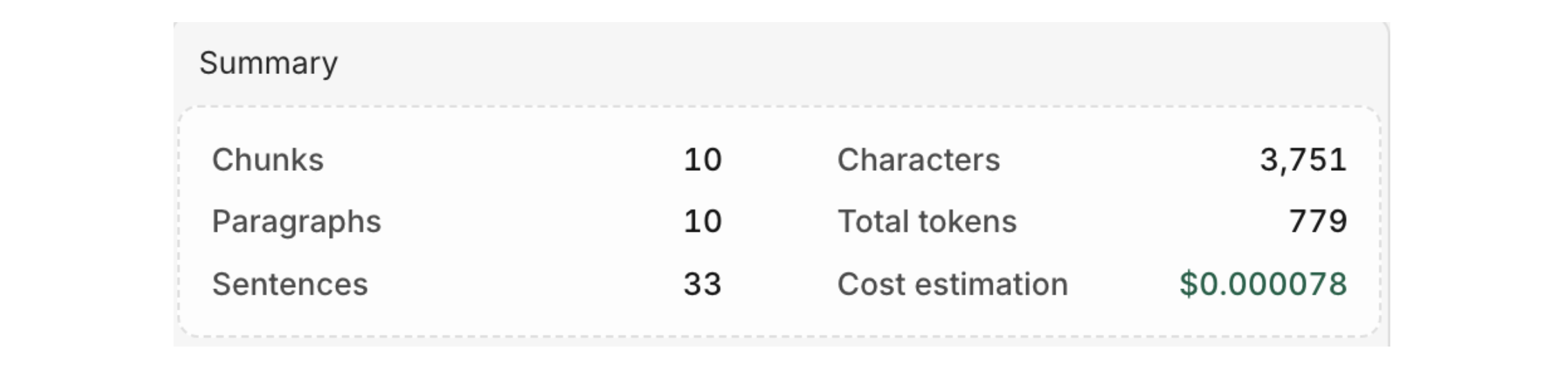
Here you can see details of the data parsed into your Knowledge Base and estimate the cost of retrieval.
Retrieval Testing
By choosing the Retrieval Testing button you can query your Knowledge Base to see if the desired information is returned.

Clicking the following icon will open the Retrieval Testing tab.
In the open tab you can type any query to test whether knowledge retrieval works correctly.
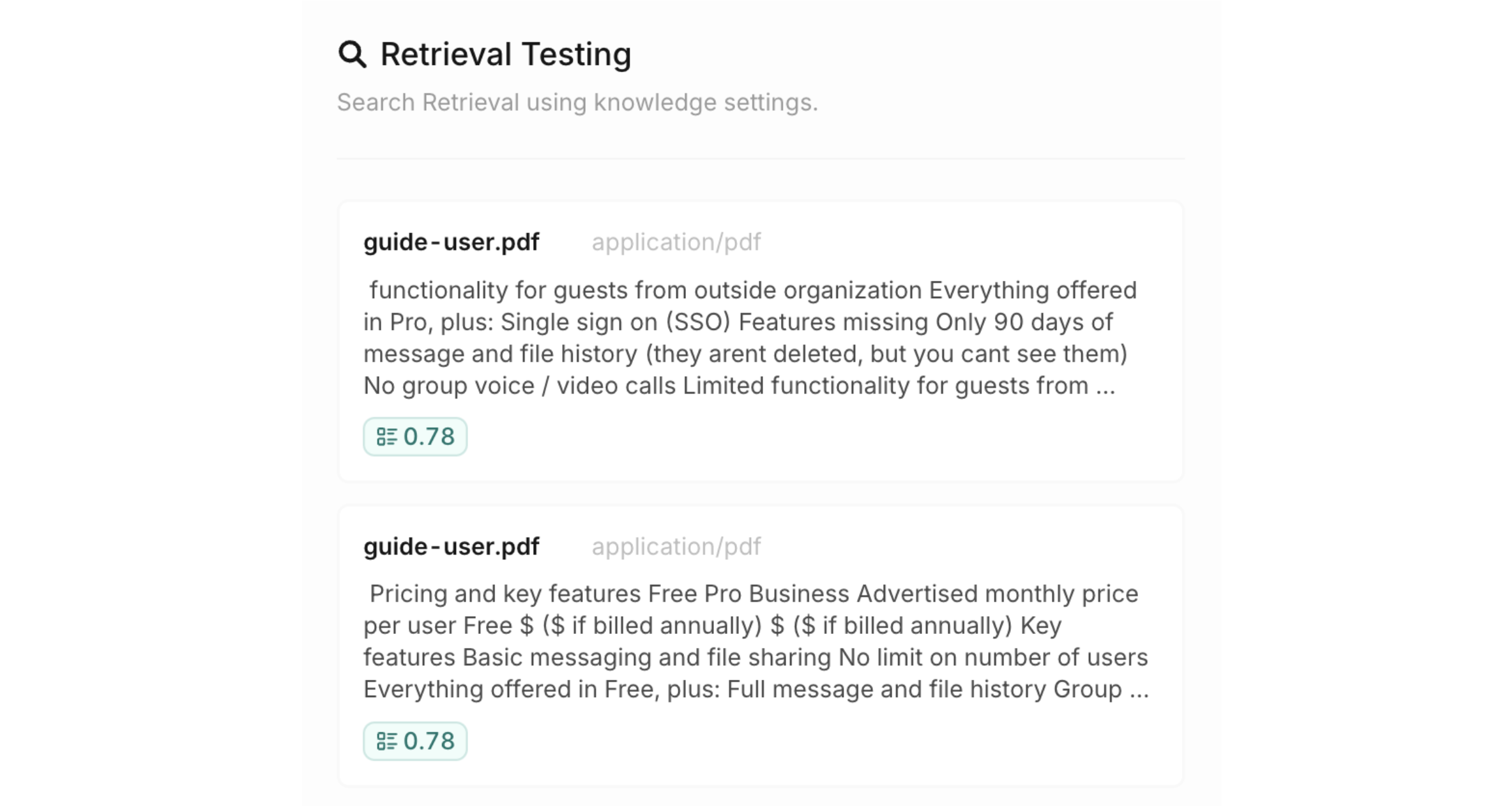
The chunks will be returned with a matching score, letting you know which results will be retrieved by the embedding model.
Knowledge Settings
By choosing the Knowledge Settings button, you can configure the following settings.
Embedding Models
Here, you can configure which llm model to use to query the Knowledge Base. Your configuration here is similar to any model configuration within Playgrounds, Experiments, or Deployments and includes the usual parameters
.](https://files.readme.io/c956357-Screenshot_2024-08-15_at_12.47.07.png)
Here you can define which model to use. You need to have activated Embedding models within your Model Garden.
Retrieval Settings
Here you can configure how search will be made within the sources.
To learn more, see Retrieval settings.
Updated 22 days ago