

Enabling new Models
To see available Models and enable them for use, head to the AI Gateway section in AI Studio and open the Models page.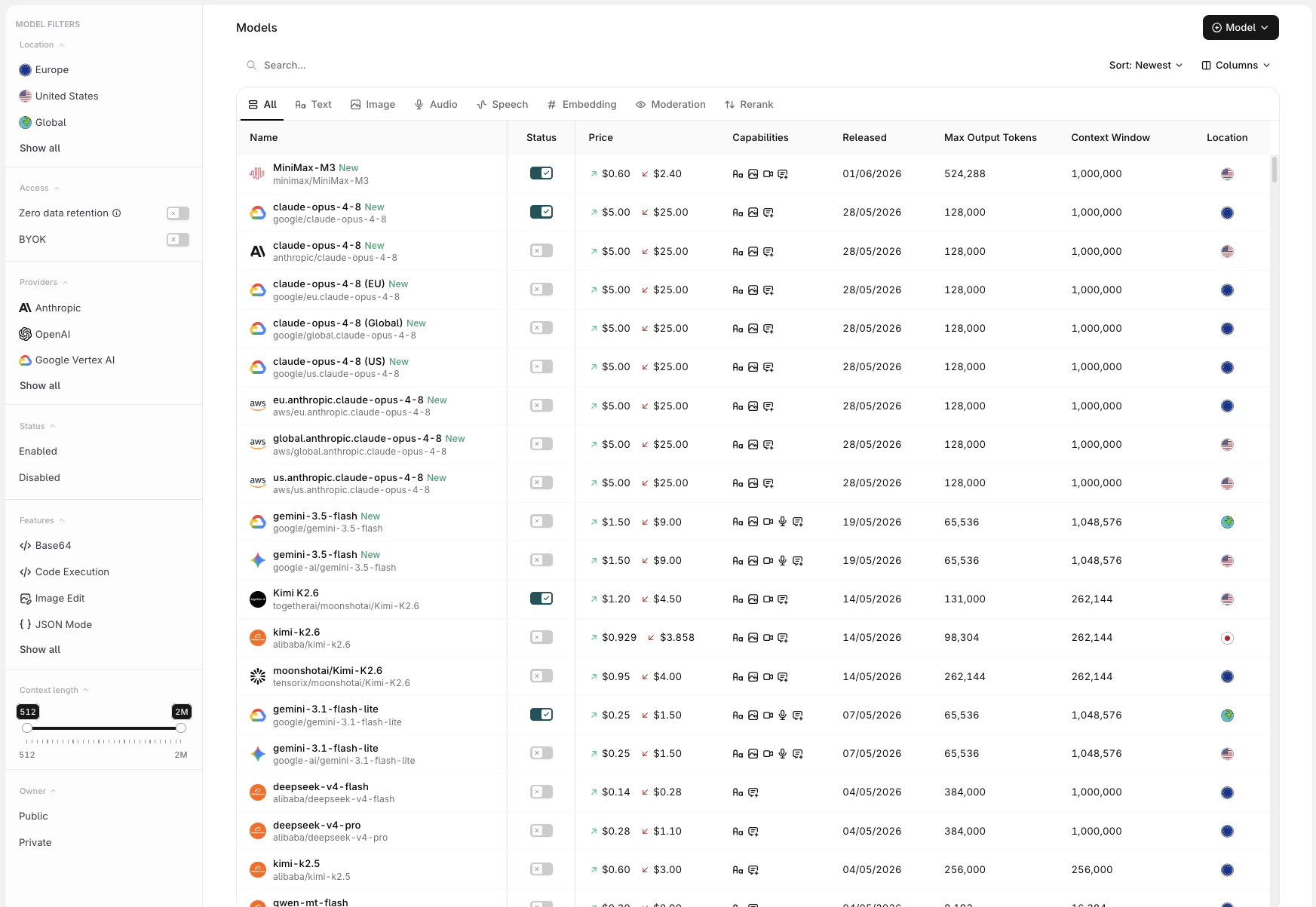
- Name: full model name and provider
- Input / Output pricing: per-token cost for input and output
- Features: capability badges indicating support for ZDR, BYOK, and other model-specific features
- Released: the model’s release date
- Max Output Tokens: maximum tokens the model can generate per response
- Context Length: total token window (input + output)
- Location: the region where the model is served
Use the Status Toggle to Enable a model for use with the AI Gateway.
Filters
Use the modality tabs at the top of the list to scope models by type: All Text Image Audio Speech Embedding Moderation Rerank The sidebar provides additional filters:| Filter | Description |
|---|---|
| Location | Filter by region: Europe, United States, Global, APAC, Australia, Singapore |
| Access | Toggle Zero data retention for ZDR-compliant providers, or BYOK for providers where an API key has been added |
| Providers | Filter by LLM provider. See Providers to configure API keys |
| Status | Show Enabled or Disabled models |
| Features | Filter by capability: Base64, Code Execution, Image Edit, JSON Mode, PDF, Reasoning, Streaming, Tool Calling, URL, Vision, Web Search |
| Context length | Drag the range slider to filter by context window size (512 to 2M tokens) |
| Owner | Filter between Public (Orq.ai-provided) and Private (onboarded) models |
Onboarding Private Models
Onboard private models by choosing Model at the top-right of the screen. This is useful when hosting a fine-tuned model or any model deployed on a private provider such as Azure AI Foundry or Vertex AI.Private Models Providers
Show Azure AI Foundry
Show Azure AI Foundry
From the Azure AI Foundry project homepage, copy the API key and one of the two endpoints shown at the top. Orq.ai accepts the following endpoints:
Paste the endpoint URL exactly as shown in Azure AI Foundry. Orq.ai does not append any path suffix.
Reference imported models in code using
| Endpoint type | Format | What it imports |
|---|---|---|
| Azure OpenAI endpoint | https://<resource>.openai.azure.com/openai/v1 | OpenAI-compatible deployments |
| Project endpoint | https://<resource>.services.ai.azure.com/api/projects/<project> | All deployments from publishers in the project (Anthropic, Cohere, and xAI) |
To learn more about the Azure AI Foundry deployment, see our Provider Documentation.
Open Add Model
In the AI Gateway sidebar, go to Models, then click Model at the top-right and select Azure.
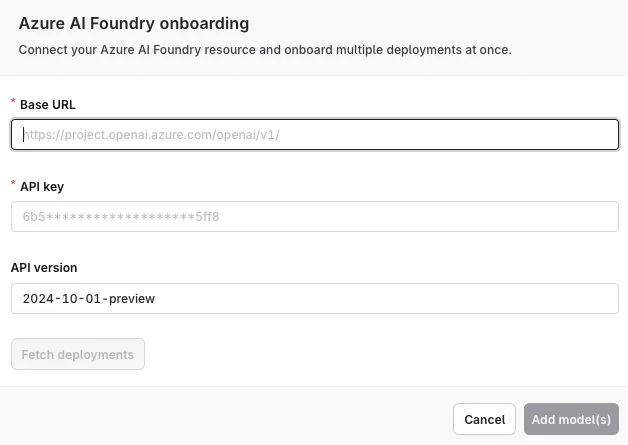
Fetch deployments
Click Fetch deployments to automatically import all available deployments. The imported models appear in the Models list. Toggle each model Enabled before use. Enabled models are available in Deployments, Agents, Playground, and Experiments.
<workspacename>@azure/<modelname> (see Referencing Private Models in Code).Show Vertex AI
Show Vertex AI
In the AI Gateway sidebar, go to Models, then click Model at the top-right and select Vertex AI. Enter the JSON configuration from your Google Cloud project to make the model available on the platform.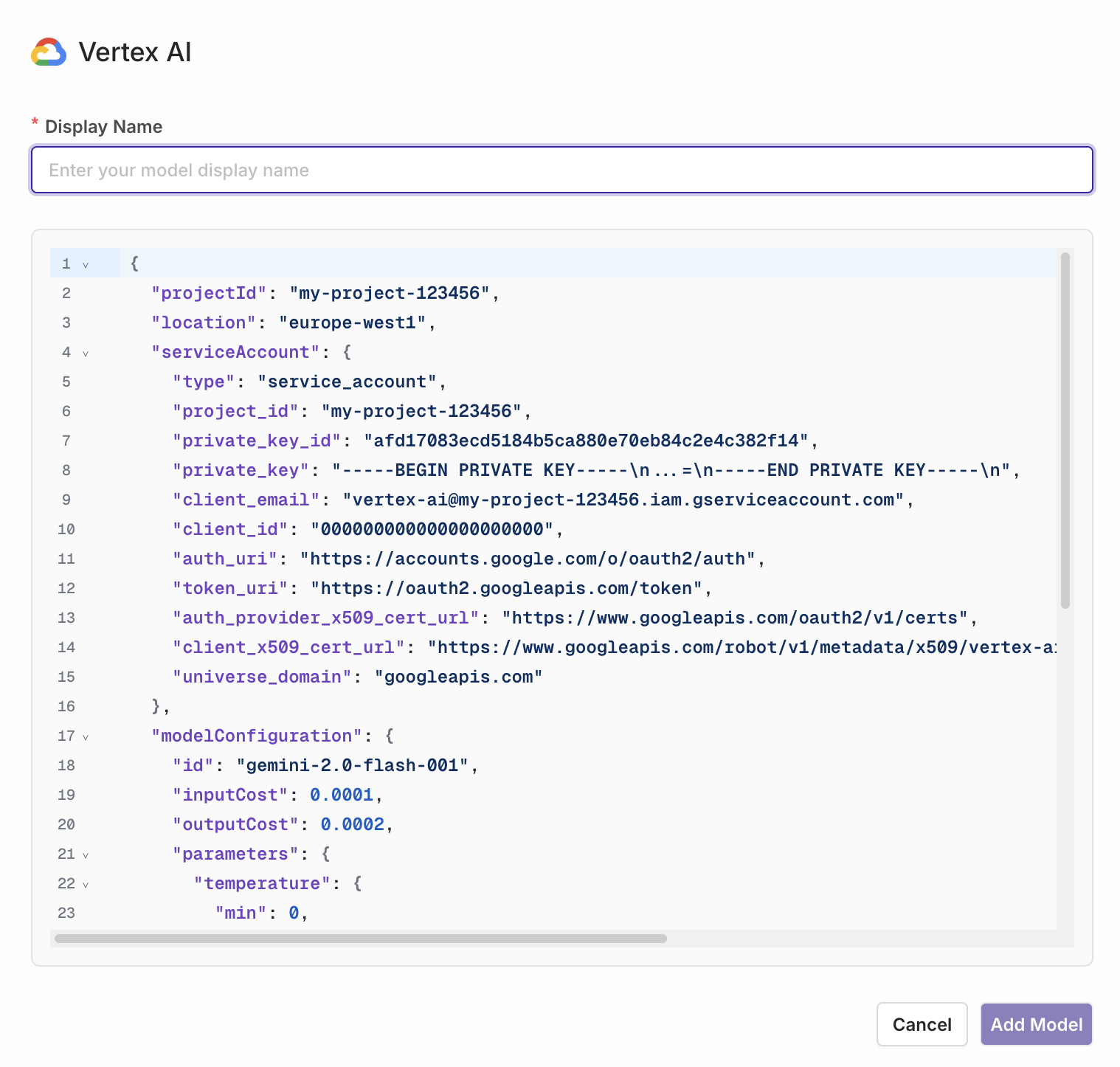
Show LiteLLM
Show LiteLLM
To import LiteLLM models, first create an Integration for the LiteLLM instance. After creation, return to the AI Gateway and import models from the connected instance.
Referencing Private Models in Code
When referencing private models through the SDKs, API, or Supported Libraries, the model is referenced by the following string:<workspacename>@<provider>/<modelname>.
Example: corp@azure/gpt-4o-2024-05-13