Setting up a Python Evaluator
Set up an evaluator in your Orq.ai panel
To start building a Python Evaluator , head to a Projects, use the + button and select Evaluator.
The following modal opens:
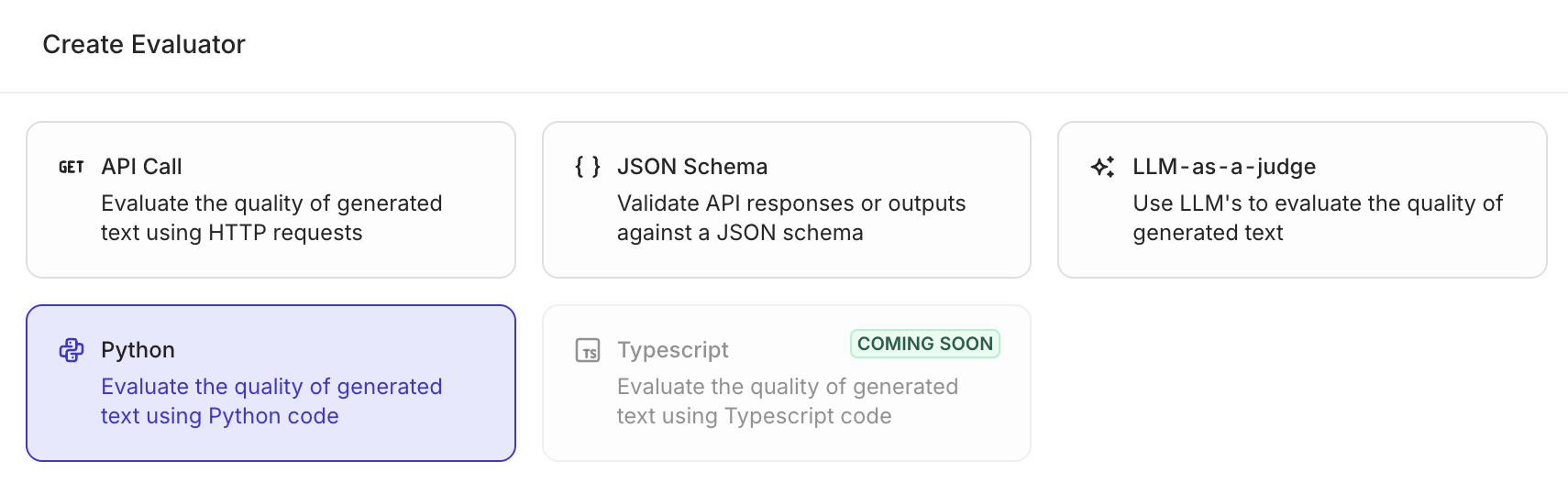
Select the Python type
You'll be then taken to the code editor to configure your Python evaluation.
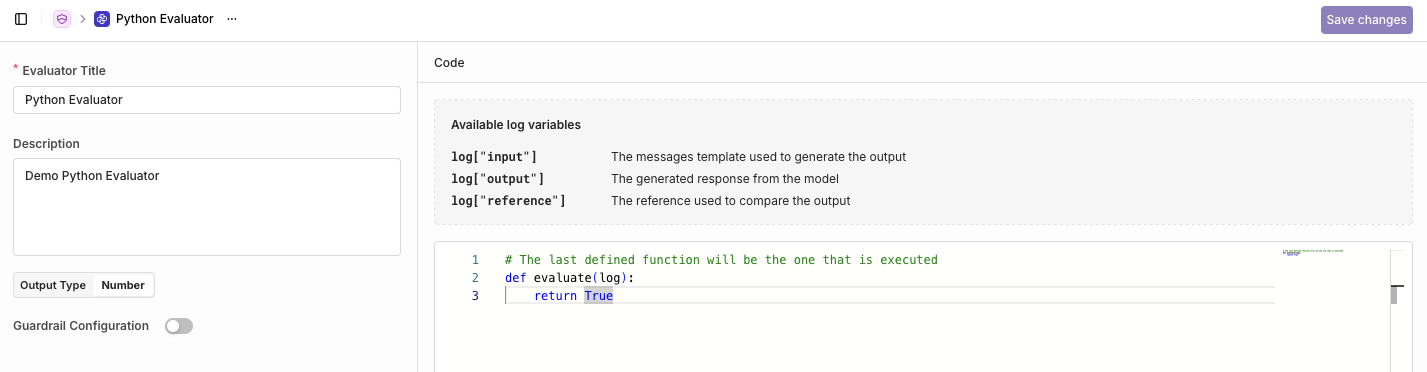
Edit here the Evaluator's code
Variable and Outputs
To perform an evaluation, the evaluator has access to the log of the Evaluated Model Execution, which contains the following three fields:
log["input"]The messages template used to generate the output.log["output"]The generated response from the model.log["reference"]The reference used to compare the output.
The evaluator can be configured with two different response types, note the return type of the entry-point function must match the chosen configuration:
- Number to return a score.
- Boolean to return a true/false value.
Example
The following example compares the output size with the given reference.
def evaluate(log):
output_size = len(log["output"])
reference_size = len(log["reference"])
return abs(output_size - reference_size)
You can define multiple methods within the code editor, the last method will be the entry-point for the Evaluator when run.
Environment and Libraries
The Python Evaluator runs in the following environment: python 3.11
The environment comes preloaded with the following libraries:
numpy==1.26.4
Guardrail Configuration
Within a Deployment, you can use your Python Evaluator as a Guardrail, blocking potential calls to
Enabling the Guardrail toggle will block payloads that don't validate the given JSON Schema.
Once created the Evaluator will be available to use in Deployments, to learn more see Using a Python Evaluator
Updated 27 days ago