Datasets in Experiments
What are datasets and how to use them?
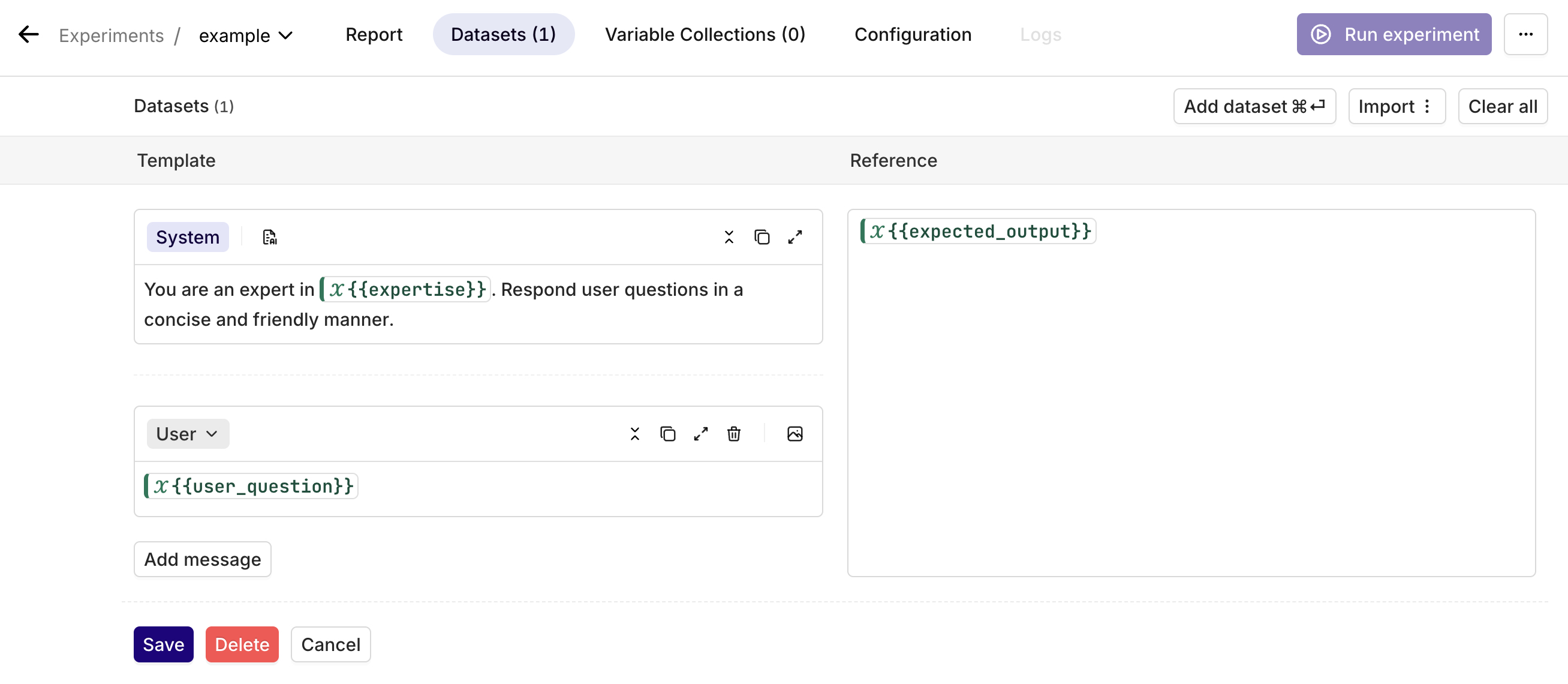
Datasets are a combination of a prompt template and an optional reference (expected output).
To get started, you can import your dataset by uploading a CSV file. Additionally, you can also manually add a dataset.
Template
The template is nothing more than your prompt template.
You can use Input Variables by incorporating the {{variable_name}} within your prompt (see screenshot).
Make sure to attach the correct role to your prompt message.
If you’re using multiple models, it’s recommended to only send a user message without a system message, as each model handles user roles differently.
Reference
In addition to your prompt, you have the option to add a reference. This is needed in order to run Evaluators in Experiments. It basically compares the newly generated output with the expected output.
Updated 2 months ago