Model Configuration
How to configure your large language model (LLM) to your specific needs?
After selecting the models you want to compare against each other or itself, it's time to configure them.
Understanding what each parameter does is crucial to improving your prompt and LLM output.
All models have their own set of parameters. For example: Google's image generation model lets you select the number of images it needs to generate, whereas OpenAI's image generation model lets you choose the dimension of the image. Also, the models have a different default setting and meaning behind each parameter. For example: Claude's temperature 1 differs from Gemini's temperature 1.
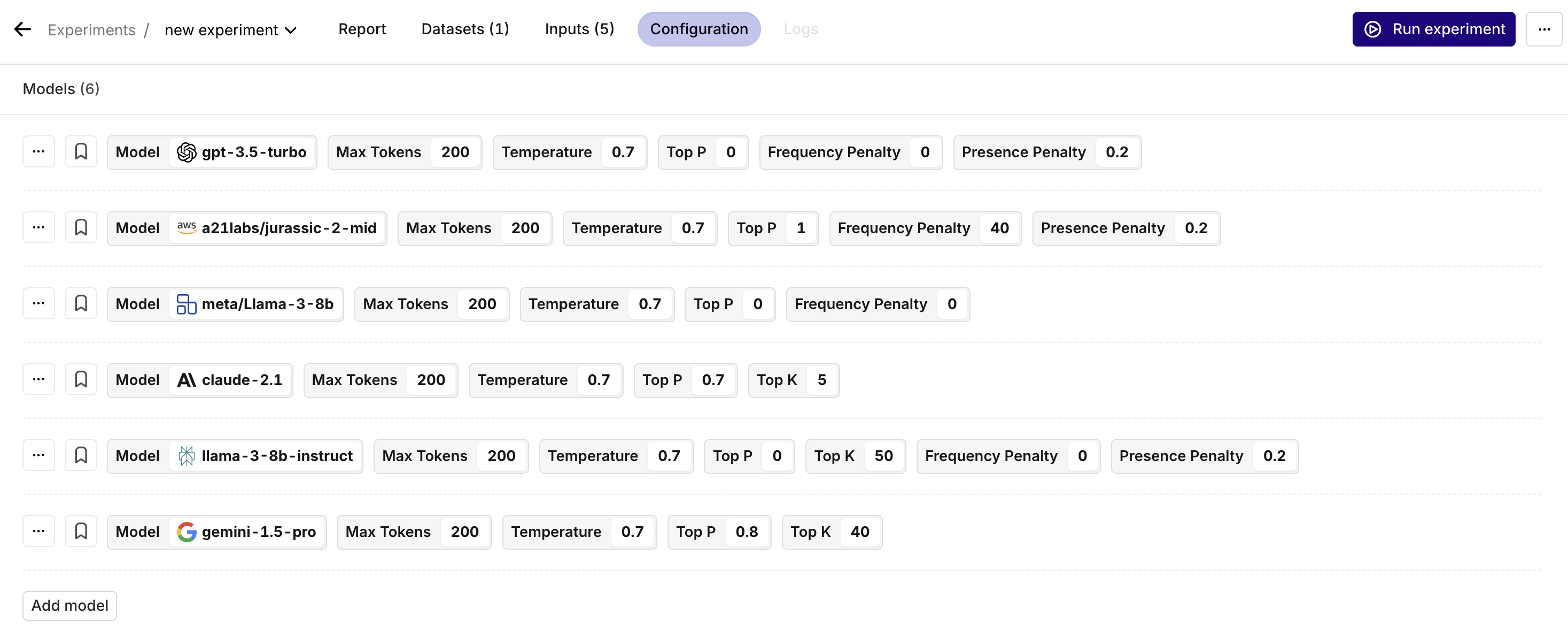
Parameters
Temperature
The temperature parameter is a master control for creativity and predictability. Imagine it as the dial on a creative thermostat. Turn it up, and the model generates more diverse, sometimes surprising responses, exploring the outer edges of its training. Dial it down, and the output becomes more predictable, sticking closely to the patterns it knows best.
Max tokens
The Max Tokens parameter allows you to define the upper limit of tokens that the model can produce in a single output. This feature helps prevent the model from generating excessively long text sequences, ensuring concise and relevant responses. Conversely, it's important to allocate a sufficient number of tokens to enable the model to deliver a complete answer. Setting the limit too low may result in the model's response being cut off before fully addressing the query.
Top K
This parameter narrows the model's choices to only the k most likely tokens during each step of text generation. By assigning a value to k, you direct the model to focus on a select group of tokens deemed most probable. This method aids in refining the output, making sure it follows particular patterns or meets certain criteria.
Top P
Top P, a.k.a. "nucleus sampling" is a smart filter for large language models. It selects a pool of likely words based on a probability threshold, balancing creativity with coherence. This method ensures responses are both relevant and interesting
Frequency Penalty
If you don't want the model to constantly use the same words, the frequency penalty helps to minimize repetition. It discourages the model from reusing the same words or phrases too frequently in its output, encouraging a richer, more varied use of language. This leads to more original and engaging responses, enhancing the creativity of the content generated.
Presence Penalty
Similar to the frequency penalty, this parameter also discourages or stimulates repetition. However, the presence penalty focuses more on discouraging repeated topics or ideas rather than specific words and phrases.
Updated 2 months ago