Orq.ai as Prompt Manager
Use orq.ai's LLM Prompts as prompt management, workflow, prompt engineering and version control platform for your AI team
As an alternative to using orq.ai as a gateway, you can use orq.ai as a prompt configuration manager. You use this alternative setup if you need full control over the actual LLM call and logging.
To retrieve the deployment configuration, call the get_config() or getConfig() method. The method takes in the following body parameters to get the deployment configuration payload:
key: this is the deployment ID to invoke. It is a type string, and it is required.inputs: This is an object, and it represents key-value pair variables to replace in your prompts. The default variables are used if a variable defined in the prompt is not provided.context: This object also represents key-value pairs that match your data model and fields declared in your configuration matrix. If you send multiple prompt keys, the context will be applied to the evaluation of each key.metadata: This object represents key-value pairs that you want to attach to the log generated by this request.
For example:
config = client.deployments.get_config(
"key" = "Deployment-configuration",
"context" ={ environments: [ "production" ], locale: [ "en" ]},
"inputs" ={ country: "Netherlands" },
"metadata"= {custom-field-name":"custom-metadata-value"}
)
print(config.to_dict())
const deploymentConfig = await client.deployments.getConfig({
key: "Deployment-configuration",
context: { environments: [ "production" ], locale: [ "en" ] },
inputs: { country: "Netherlands" },
metadata: { "custom-field-name": "custom-metadata-value" }
}););
Prompt metrics
After every successful transaction, you can add metrics to the log using the addMetrics() method. This method is a powerful tool for capturing and recording essential data points related to the transaction, allowing for a comprehensive evaluation of the language model's performance.
By implementing the addMetrics() method, you can track various metrics, including but not limited to chain ID, conversation ID, user ID, feedback (scores), custom metadata, and performance-related statistics.
deployment.add_metrics(
chain_id="c4a75b53-62fa-401b-8e97-493f3d299316",
conversation_id="ee7b0c8c-eeb2-43cf-83e9-a4a49f8f13ea",
user_id="e3a202a6-461b-447c-abe2-018ba4d04cd0",
feedback={"score": 100},
metadata={
"custom": "custom_metadata",
"chain_id": "ad1231xsdaABw",
},
usage={
"prompt_tokens": 100,
"completion_tokens": 900,
"total_tokens": 1000,
},
performance={
"latency": 9000,
"time_to_first_token": 250,
}
)
deployment.addMetrics({
chain_id: "c4a75b53-62fa-401b-8e97-493f3d299316",
conversation_id: "ee7b0c8c-eeb2-43cf-83e9-a4a49f8f13ea",
user_id: "e3a202a6-461b-447c-abe2-018ba4d04cd0",
feedback: {
score: 100
},
metadata: {
custom: "custom_metadata",
chain_id: "ad1231xsdaABw"
},
usage: {
prompt_tokens: 100,
completion_tokens: 900,
total_tokens: 1000
},
performance: {
latency: 9000,
time_to_first_token: 250
}
})
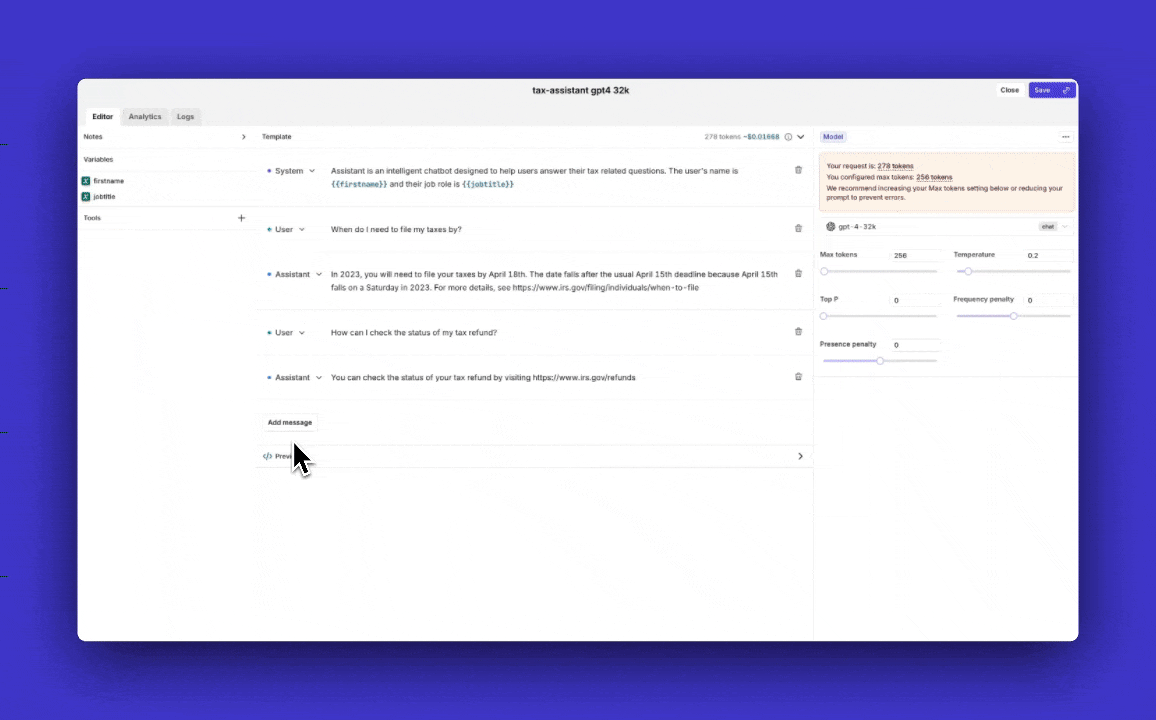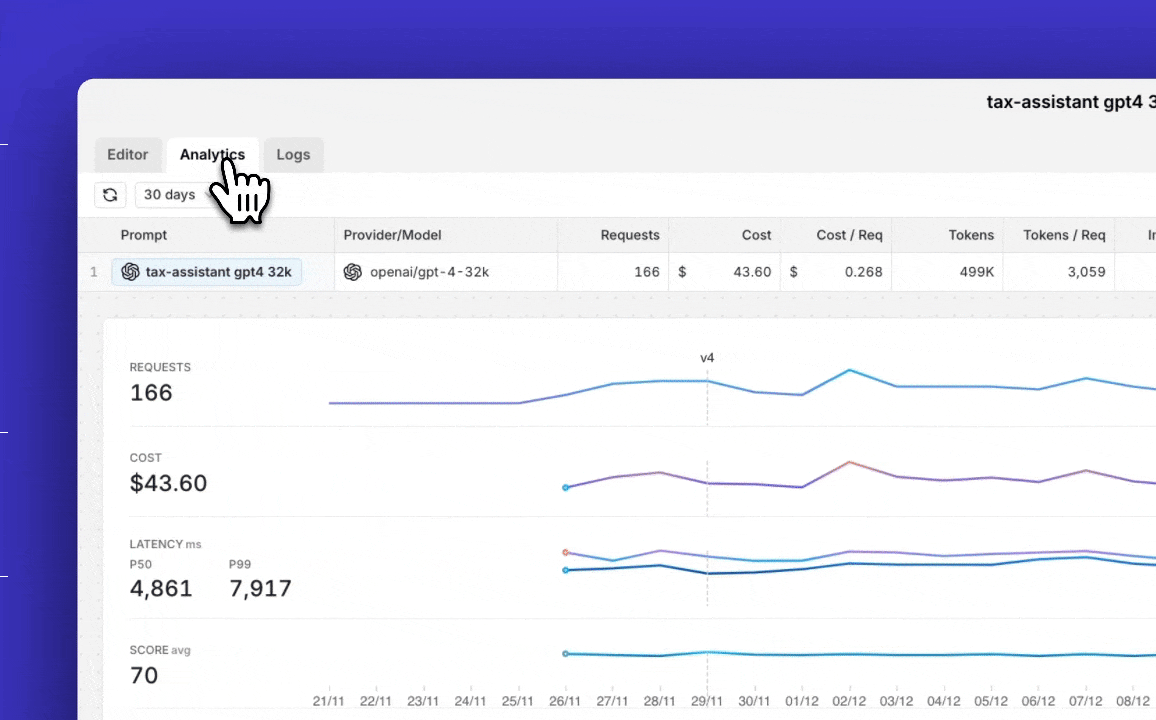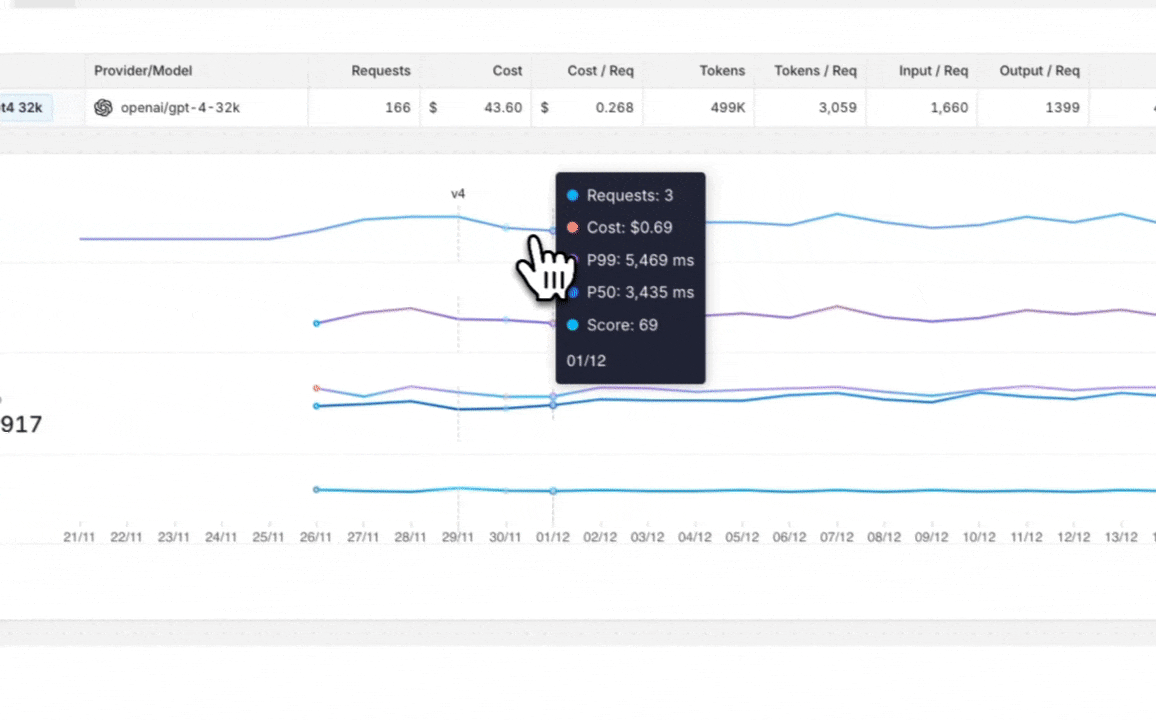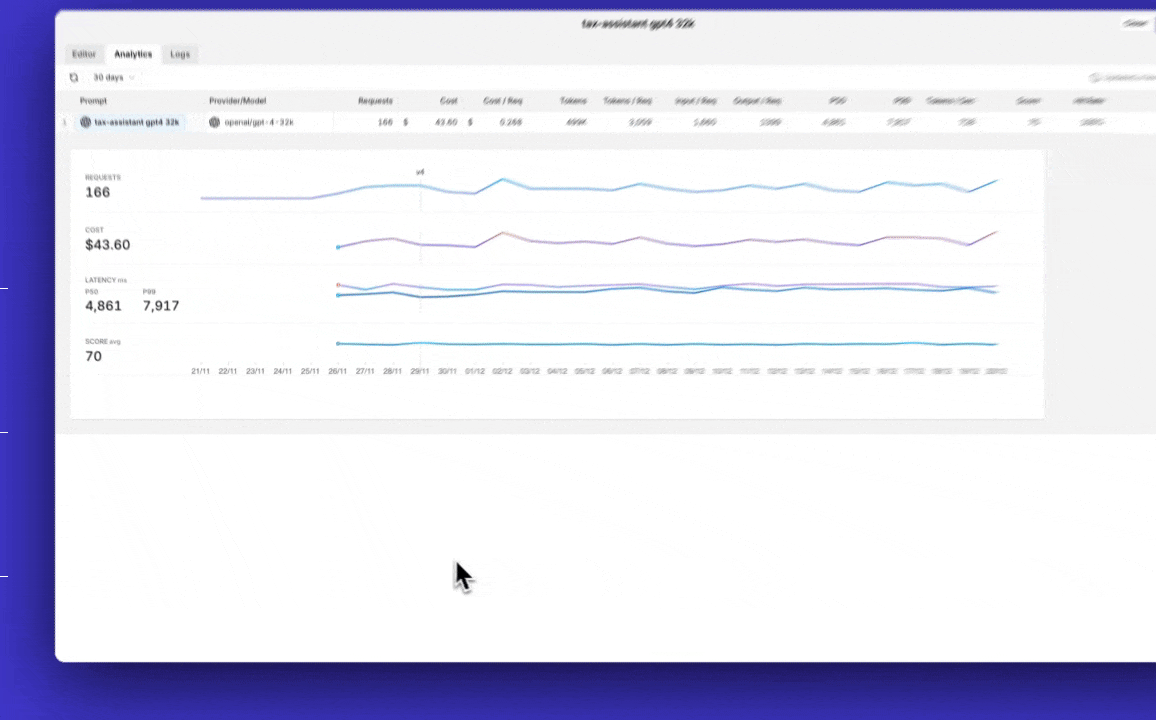
Prompt Analytics
Analytics of how the prompt interacts with the LLM are displayed in the analytics section of the prompt. Orq.ai records the prompt's version, requests, tokens, latency, score, and hit rate.
Prompt logs
This refers to records that capture details about the prompts used during interactions with large language models (LLMs). These logs are important in analyzing and improving the performance of language models in various applications.

Updated about 1 month ago