LlamaIndex
Integrate Orq.ai with LlamaIndex using OpenInference
Getting Started
LlamaIndex is a powerful framework for building RAG (Retrieval-Augmented Generation) applications with LLMs. Tracing LlamaIndex with Orq.ai provides comprehensive insights into document indexing, retrieval performance, query processing, and LLM interactions to optimize your RAG applications.
Prerequisites
Before you begin, ensure you have:
- An Orq.ai account and API Key
- LlamaIndex installed in your project
- Python 3.8+
- OpenAI API key (or other LLM provider credentials)
Install Dependencies
# Core LlamaIndex and OpenInference packages
pip install llama-index openinference-instrumentation-llama-index
# OpenTelemetry packages
pip install opentelemetry-sdk opentelemetry-exporter-otlp-proto-http
# LLM providers
pip install openai anthropic
# Optional: For advanced vector stores and embeddings
pip install llama-index-vector-stores-chroma llama-index-embeddings-openaiConfigure Orq.ai
Set up your environment variables to connect to Orq.ai's OpenTelemetry collector:
Unix/Linux/macOS:
export OTEL_EXPORTER_OTLP_ENDPOINT="https://api.orq.ai/v2/otel"
export OTEL_EXPORTER_OTLP_HEADERS="Authorization=Bearer <ORQ_API_KEY>"
export OTEL_RESOURCE_ATTRIBUTES="service.name=llamaindex-app,service.version=1.0.0"
export OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"Windows (PowerShell):
$env:OTEL_EXPORTER_OTLP_ENDPOINT = "https://api.orq.ai/v2/otel"
$env:OTEL_EXPORTER_OTLP_HEADERS = "Authorization=Bearer <ORQ_API_KEY>"
$env:OTEL_RESOURCE_ATTRIBUTES = "service.name=llamaindex-app,service.version=1.0.0"
$env:OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"Using .env file:
OTEL_EXPORTER_OTLP_ENDPOINT=https://api.orq.ai/v2/otel
OTEL_EXPORTER_OTLP_HEADERS=Authorization=Bearer <ORQ_API_KEY>
OTEL_RESOURCE_ATTRIBUTES=service.name=llamaindex-app,service.version=1.0.0
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>Integrations Example
We'll be using OpenInference as TracerProvider with LlamaIndex
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk import trace as trace_sdk
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# Initialize OpenTelemetry
tracer_provider = trace_sdk.TracerProvider()
tracer_provider.add_span_processor(BatchSpanProcessor(OTLPSpanExporter(
endpoint="https://api.orq.ai/v2/otel/v1/traces",
headers={"Authorization": "Bearer <ORQ_API_KEY>"}
)))
trace.set_tracer_provider(tracer_provider)
# Instrument LlamaIndex
LlamaIndexInstrumentor().instrument(tracer_provider=tracer_provider)
# Your LlamaIndex code is automatically traced
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What is the main topic of these documents?")View Traces
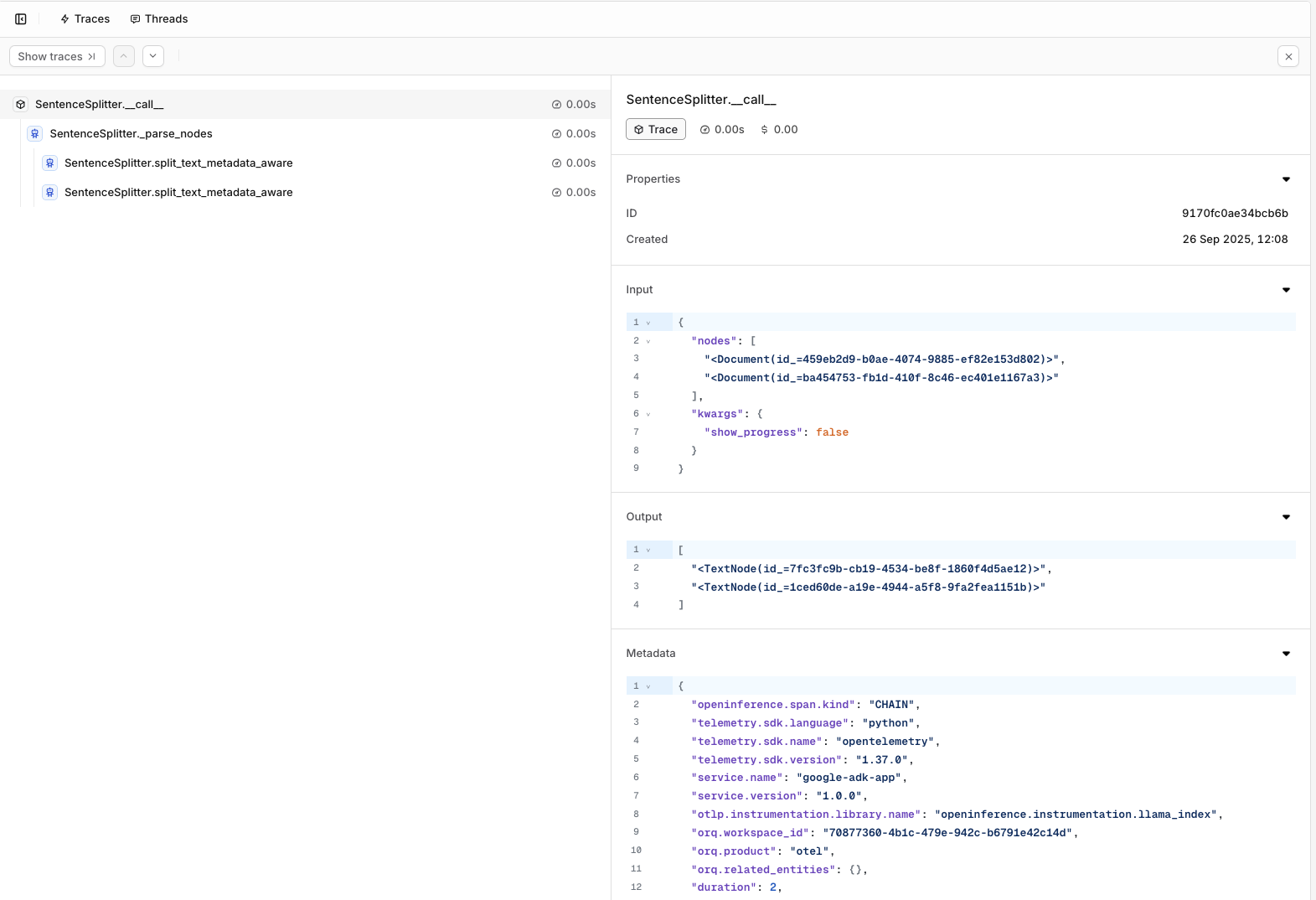
Traces from your LlamaIndex execution will be visible within the Traces menu in your orq.ai studio.
Updated 22 days ago