Simple RAG
Objective
A Simple RAG (Retrieval-Augmented Generation) system provides intelligent information retrieval and answer generation by combining your own knowledge base with large language models. This architecture enables applications to provide accurate, contextual responses based on your specific documents and data while maintaining the natural language capabilities of modern LLMs.
Use Case
Simple RAG is ideal for applications that need:
- Document-Based Q&A: Answer questions based on company documents, manuals, or knowledge repositories.
- Internal Knowledge Search: Help employees find information from internal wikis, policies, or procedures.
- Customer Support: Provide accurate answers based on product documentation and support materials.
- Domain-Specific Information: Reduce hallucinations by grounding responses in verified company data.
- Contextual Responses: Generate answers that reference specific sources and maintain accuracy.
Prerequisite
Before configuring a Simple RAG, ensure you have:
- Orq.ai Account: Active workspace in the Orq.ai Studio.
- API Access: Valid API key from Workspace Settings > API Keys.
- Model Access: At least one text generation model enabled in the Model Garden, such as
gpt-4,claude-3-sonnet, orgpt-3.5-turbo. - Embedding Model: At least one embedding model enabled for knowledge base functionality, such as
text-embedding-ada-002ortext-embedding-3-small. - Source Documents: PDF, TXT, DOCX, CSV, or XML files containing your knowledge base content (max 10MB per file).
Creating a Knowledge Base
First, create a knowledge base to store your documents. Head to the Orq.ai Studio:
- Choose a Project and Folder and select the
+button. - Choose Knowledge Base.
- Enter a unique Key (e.g.,
companyDocs) and Name. - Select an Embedding Model from your enabled models.
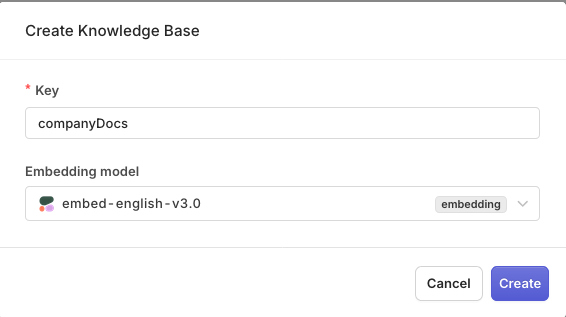
You can change embedding model later on.
Adding Source Documents
After creating the knowledge base:
- Click Add Data Source to upload your documents.
- Select files from your computer (TXT, PDF, DOCX, CSV, XLS formats supported).
- Configure chunking settings for optimal retrieval performance (to learn more, see Chunking Strategy)
- Wait for the documents to be processed and indexed.
Configuring a RAG Deployment
To create a Deployment with RAG capabilities:
- Choose a Project and Folder and select the
+button. - Choose Deployment.
- Enter name simpleRAG.
- Choose a primary Model.
Then configure your prompt messages. Click Add Message and select System role:
You are a helpful AI assistant that answers questions based on provided context from our company knowledge base.
Instructions:
- Use the retrieved context to answer user questions accurately
- If the context doesn't contain relevant information, say "I don't have enough information in the knowledge base to answer that question"
- Always cite which document or source your answer comes from when possible
- Be concise but comprehensive in your responses
- If asked about something not in the context, direct users to contact support
Context will be provided from the knowledge base: {{companyDocs}}
Answer based on this context:Adding Knowledge Base to Prompt
- Open the Knowledge Base tab in the Configuration screen.
- Select Add a Knowledge Base.
- Choose your knowledge base key (
companyDocs). - Set the type to Last User Message for automatic query-based retrieval.
- Click Save.
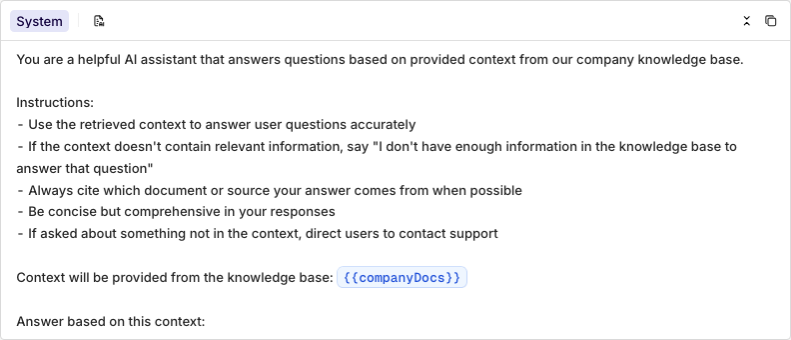
When the knowledge base is correctly loaded, it will show up in blue.
Test your RAG in the Test tab by asking questions about your uploaded documents.
Learn more about knowledge base configuration in Creating a Knowledge Base, and prompt configuration in Using a Knowledge Base in a Prompt.
When ready with your Deployment choose Deploy, learn more about Deployment Versioning.
Integrating with the SDK
Choose your preferred programming language and install the corresponding SDK:
pip install orq-ai-sdknpm install @orq-ai/nodeGet your integration ready by initializing the SDK as follows:
import os
from orq_ai_sdk import Orq
client = Orq(
api_key=os.environ.get("ORQ_API_KEY", "__API_KEY__"),
environment="production",
contact_id="rag_user" # optional
)import { Orq } from "@orq-ai/node";
const client = new Orq({
apiKey: process.env.ORQ_API_KEY || "__API_KEY__",
environment: "production",
contactId: "rag_user" // optional
});To implement a RAG-powered question answering system:
class RAG:
def __init__(self, client, deployment_key):
self.client = client
self.deployment_key = deployment_key
def ask_question(self, question, include_sources=True):
"""Ask a question and get a RAG-powered response"""
try:
# Invoke the RAG deployment
generation = self.client.deployments.invoke(
key=self.deployment_key,
messages=[
{
"role": "user",
"content": question
}
],
context={
"include_retrievals": include_sources # Include source chunks
},
metadata={
"query_type": "rag_question",
"user_intent": "information_seeking"
}
)
# Extract the response
answer = generation.choices[0].message.content
# Extract retrieved sources if available
sources = []
if hasattr(generation, 'retrievals') and generation.retrievals:
sources = [
{
"content": retrieval.content,
"source": retrieval.metadata.get("source", "Unknown"),
"score": retrieval.score
}
for retrieval in generation.retrievals
]
return {
"answer": answer,
"sources": sources,
"question": question
}
except Exception as e:
return {
"answer": "I'm sorry, I'm experiencing technical difficulties. Please try again later.",
"sources": [],
"error": str(e)
}
# Initialize and use the RAG system
rag = RAG(client, "simpleRAG")
result = rag.ask_question("What is our company return policy?")
print(f"Answer: {result['answer']}")
if result['sources']:
print("\nSources:")
for source in result['sources']:
print(f"- {source['source']}: {source['content'][:100]}...")class RAG {
constructor(client, deploymentKey) {
this.client = client;
this.deploymentKey = deploymentKey;
}
async askQuestion(question, includeSources = true) {
try {
const response = await this.client.deployments.invoke({
key: this.deploymentKey,
messages: [
{
role: "user",
content: question
}
],
context: {
include_retrievals: includeSources
},
metadata: {
query_type: "rag_question",
user_intent: "information_seeking"
}
});
const answer = response.choices[0].message.content;
// Extract retrieved sources if available
const sources = response.retrievals ? response.retrievals.map(retrieval => ({
content: retrieval.content,
source: retrieval.metadata?.source || "Unknown",
score: retrieval.score
})) : [];
return {
answer,
sources,
question
};
} catch (error) {
return {
answer: "I'm sorry, I'm experiencing technical difficulties. Please try again later.",
sources: [],
error: error.message
};
}
}
}
// Initialize and use the RAG system
const rag = new RAG(client, "simpleRAG");
const result = await rag.askQuestion("What is our company return policy?");
console.log(`Answer: ${result.answer}`);
if (result.sources.length > 0) {
console.log("\nSources:");
result.sources.forEach(source => {
console.log(`- ${source.source}: ${source.content.substring(0, 100)}...`);
});
}Here is what the output looks like:
❯ python3 rag_system.py
Answer: Based on our company documentation, our return policy allows customers to return items within 30 days of purchase with a valid receipt. Items must be in original condition and packaging. Refunds are processed within 5-7 business days after we receive the returned item.
Sources:
- company_policies.pdf: Return Policy: All items can be returned within 30 days of purchase provided...
- customer_service_guide.pdf: For returns, customers must provide proof of purchase and items must be...Viewing Logs and Retrievals
Going back to the Deployment page, you can view the calls made through your RAG application. You can view details for a single log by clicking on a log line. This opens a panel containing all the details for the log, including:
- The user's question and generated response
- Retrieved document chunks and their relevance scores
- Source attribution and metadata
- Performance metrics and response times
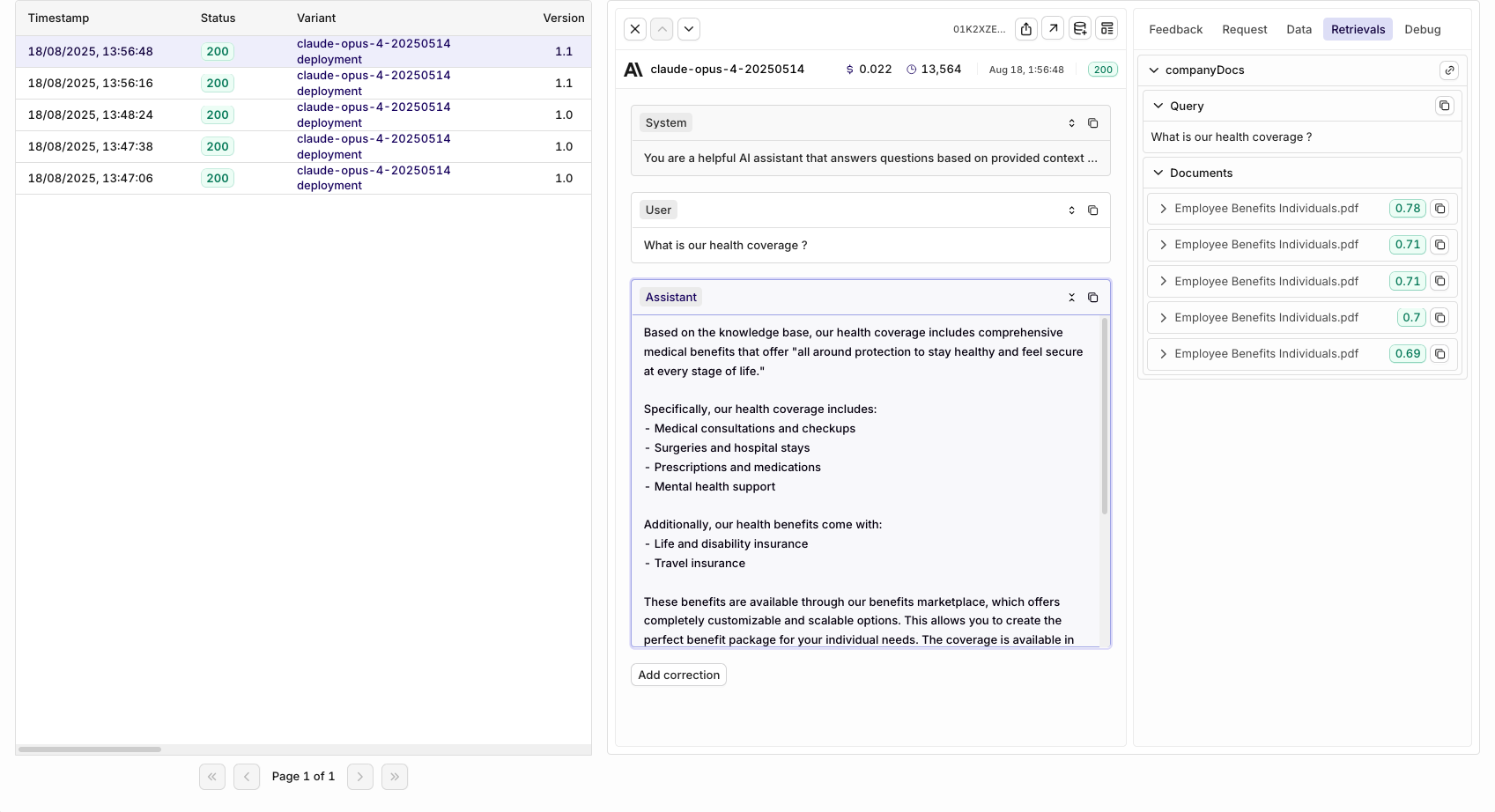
Within the logs you'll be able to see the source retrievals and their score.
Monitor your RAG system's performance by tracking:
- Retrieval Quality: Review which documents are being retrieved for different queries
- Answer Accuracy: Monitor response quality and source attribution
- Query Patterns: Identify common questions and knowledge gaps
- Response Times: Track performance of knowledge base searches and generation
To learn more about logs and retrievals see Logs and Include Retrievals.
You've completed the setup for a Simple RAG system. Explore our RAG Cookbook or other Cookbooks to see more advanced RAG implementations.
Updated about 1 month ago