Using Evaluators via the API
The Evaluator Library is available to use via the API and SDKs, this page dives into the available calls.
Prerequisite
To get started, an API key is needed to use within SDKs or HTTP API.
To get an API key ready, see Authentication.
SDK
Built-in Evaluators
All the built-in evaluators available within our Evaluator Library are directly callable through the API.
| Name | Description | Path |
|---|---|---|
| BERT Score | BERT-based semantic similarity scoring | /v2/evaluators/bert_score |
| BLEU Score | BLEU score for text comparison (translation quality) | /v2/evaluators/bleu_score |
| Contains | Check if text contains specific content | /v2/evaluators/contains |
| Contains All | Check if text contains all specified items | /v2/evaluators/contains_all |
| Contains Any | Check if text contains any of specified items | /v2/evaluators/contains_any |
| Contains None | Check if text contains none of specified items | /v2/evaluators/contains_none |
| Contains Email | Validate presence of email addresses | /v2/evaluators/contains_email |
| Contains URL | Check for URL presence | /v2/evaluators/contains_url |
| Contains Valid Link | Validate working links | /v2/evaluators/contains_valid_link |
| Ends With | Check text ending patterns | /v2/evaluators/ends_with |
| Exact Match | Exact string matching | /v2/evaluators/exact_match |
| Valid JSON | JSON format validation | /v2/evaluators/valid_json |
| Length Between | Check text length within range | /v2/evaluators/length_between |
| Length Greater Than | Minimum length validation | /v2/evaluators/length_greater_than |
| Length Less Than | Maximum length validation | /v2/evaluators/length_less_than |
| Age Appropriate | Age-appropriate content checking | /v2/evaluators/age_appropriate |
| Bot Detection | Detect bot-generated content | /v2/evaluators/bot_detection |
| Grammar | Grammar quality assessment | /v2/evaluators/grammar |
| PII | Personal Identifiable Information detection | /v2/evaluators/pii |
| Sentiment Classification | Sentiment analysis | /v2/evaluators/sentiment_classification |
| Tone of Voice | Tone analysis and classification | /v2/evaluators/tone_of_voice |
| Fact Checking Knowledge Base | Fact verification against knowledge base | /v2/evaluators/fact_checking_knowledge_base |
| Localization | Localization quality assessment | /v2/evaluators/localization |
| Summarization | Summary quality evaluation | /v2/evaluators/summarization |
| Translation | Translation quality assessment | /v2/evaluators/translation |
| RAGAs Coherence | Text coherence measurement | /v2/evaluators/ragas_coherence |
| RAGAs Conciseness | Conciseness evaluation | /v2/evaluators/ragas_conciseness |
| RAGAs Context Precision | Context precision in RAG systems | /v2/evaluators/ragas_context_precision |
| RAGAs Correctness | Factual correctness assessment | /v2/evaluators/ragas_correctness |
| RAGAs Faithfulness | Faithfulness to source material | /v2/evaluators/ragas_faithfulness |
| RAGAs Harmfulness | Harmful content detection | /v2/evaluators/ragas_harmfulness |
| RAGAs Maliciousness | Malicious content detection | /v2/evaluators/ragas_maliciousness |
| RAGAs Response Relevancy | Response relevance scoring | /v2/evaluators/ragas_response_relevancy |
| RAGAs Summarization | RAG-specific summarization quality | /v2/evaluators/ragas_summarization |
Example
We'll be calling the Tone of Voice endpoint:
Here is an example call:
The query defines the way the evaluator runs on the given output.
curl --request POST \
--url https://api.orq.ai/v2/evaluators/tone_of_voice \
--header 'accept: application/json' \
--header 'authorization: Bearer ORQ_API_KEY' \
--header 'content-type: application/json' \
--data '
{
"query": "Validate the tone of voice if it is professional.",
"output": "Hello, how are you ??",
"model": "openai/gpt-4o"
}
'from orq_ai_sdk import Orq
import os
with Orq(
api_key=os.getenv("ORQ_API_KEY", ""),
) as orq:
res = orq.evals.tone_of_voice(request={
"query": "Validate the tone of voice if it is professional.",
"output": "Hello, how are you ??",
"model": "openai/gpt-4o"
})
assert res is not None
# Handle response
print(res)import { Orq } from "@orq-ai/node";
const orq = new Orq({
apiKey: process.env["ORQ_API_KEY"] ?? "",
});
async function run() {
const result = await orq.evals.toneOfVoice({
query: "Validate the tone of voice if it is professional.",
output: "Hello, how are you ??",
model: "openai/gpt-4o",
});
console.log(result);
}
run();Here is the result returned by the API
The value here holds result of the evaluator call following the query
{
"value": {
"value": false,
"explanation": "The output does not align with a professional tone. The use of 'Hello, how are you ??' is informal and lacks the formality expected in professional communication. The double question marks and casual greeting are more suited to a casual or friendly context rather than a professional one. A professional tone would require a more formal greeting and a clear purpose for the communication."
}
}Calling a custom evaluator
It is also possible to call a custom-made Evaluator made on orq using the Invoke a Custom Evaluator API call.
You can fetch the Evaluator ID to send to this call by searching for Evaluators using the Get all Evaluators API.
Finally, through the Orq studio, find the View Code button on your Evaluator page. the following modal opens:
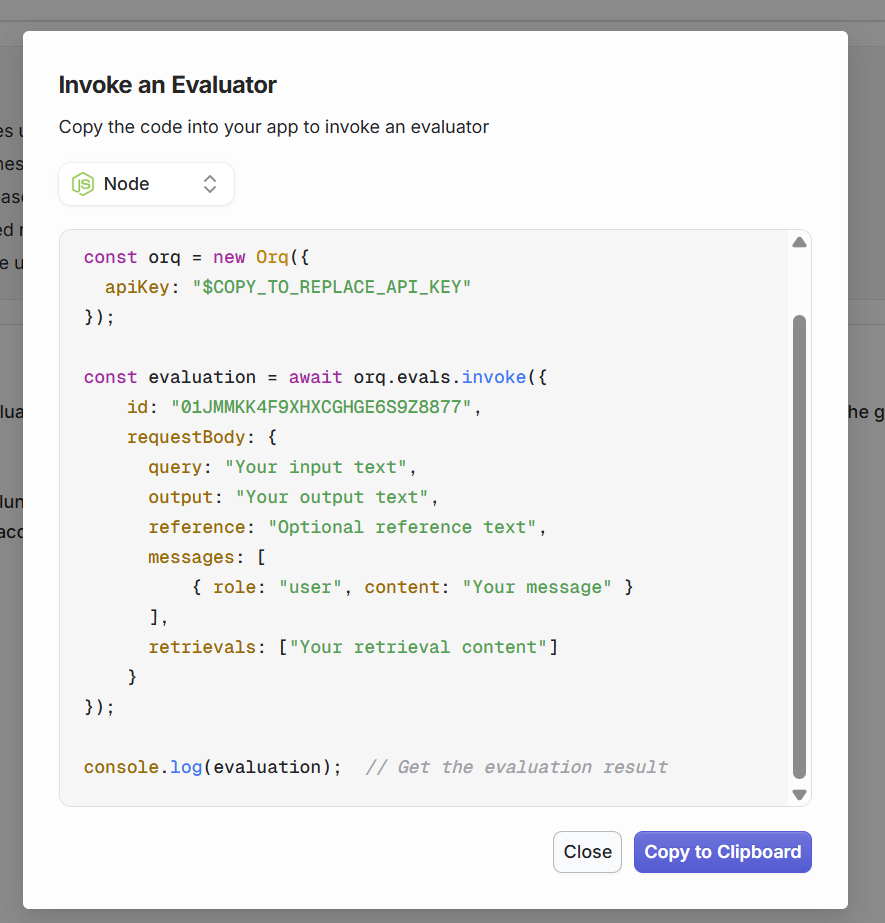
Evaluator code is available in cURL, Node.js, and Python
This code is used to call the current Evaluator through the API. Ensure the payload is containing all necessary data for the Evaluator to execute correctly.
Using EvaluatorQ
EvaluatorQ is a dedicated SDK for using Evaluators within your application.
It features the following capabilities:
- Parallel Execution: Run multiple evaluation jobs concurrently with progress tracking
- Flexible Data Sources: Support for inline data, promises, and Orq platform datasets
- Type-safe: Fully written in TypeScript
Installation:
npm install @orq-ai/evaluatorqUsage example:
import { evaluatorq, job } from "@orq-ai/evaluatorq";
const textAnalyzer = job("text-analyzer", async (data) => {
const text = data.inputs.text;
const analysis = {
length: text.length,
wordCount: text.split(" ").length,
uppercase: text.toUpperCase(),
};
return analysis;
});
await evaluatorq("text-analysis", {
data: [
{ inputs: { text: "Hello world" } },
{ inputs: { text: "Testing evaluation" } },
],
jobs: [textAnalyzer],
evaluators: [
{
name: "length-check",
scorer: async ({ output }) => {
const passesCheck = output.length > 10;
return {
value: passesCheck ? 1 : 0,
explanation: passesCheck
? "Output length is sufficient"
: `Output too short (${output.length} chars, need >10)`,
};
},
},
],
});Learn more, see the EvaluatorQ repository on Github
Updated about 1 month ago