Building customer support app with AI Gateway
TL;DR:
- Connect Orq.ai to LLM providers
- Use cURL streaming for real-time model responses.
- Add a knowledge base to enhance contextual understanding.
- Build a simple customer support agent powered by connected models and your data.
[ Video demonstration ]
AI Gateway is a single unified API endpoint that lets you seamlessly route and manage requests across multiple AI model providers (e.g., OpenAI, Anthropic, Google, AWS). This functionality comes in handy, when you want to avoid dependency on a single provider and automatically switch between providers in case of an outage. API gateway gives you freedom from a vendor lock-in and ensures that you can scale reliably when the usage surges.
[ Graphic of a roadmap ]
Getting started with AI Gateway
To get started you need to decide which provider you want to connect to. This is a sample OpenAI integration:
- Navigate to Integrations
- Select OpenAI
- Click on View integration
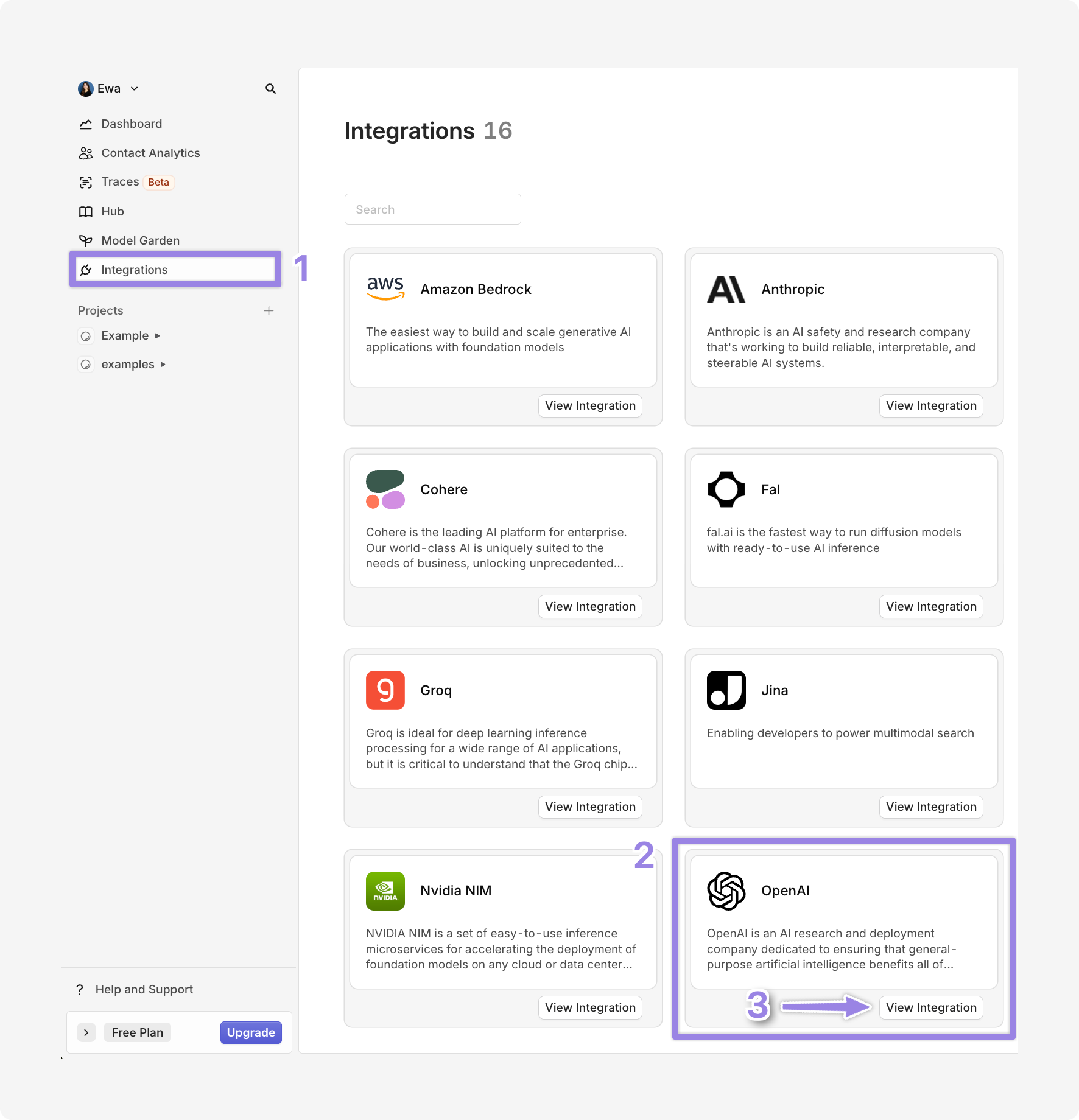
Click on Setup your own API key
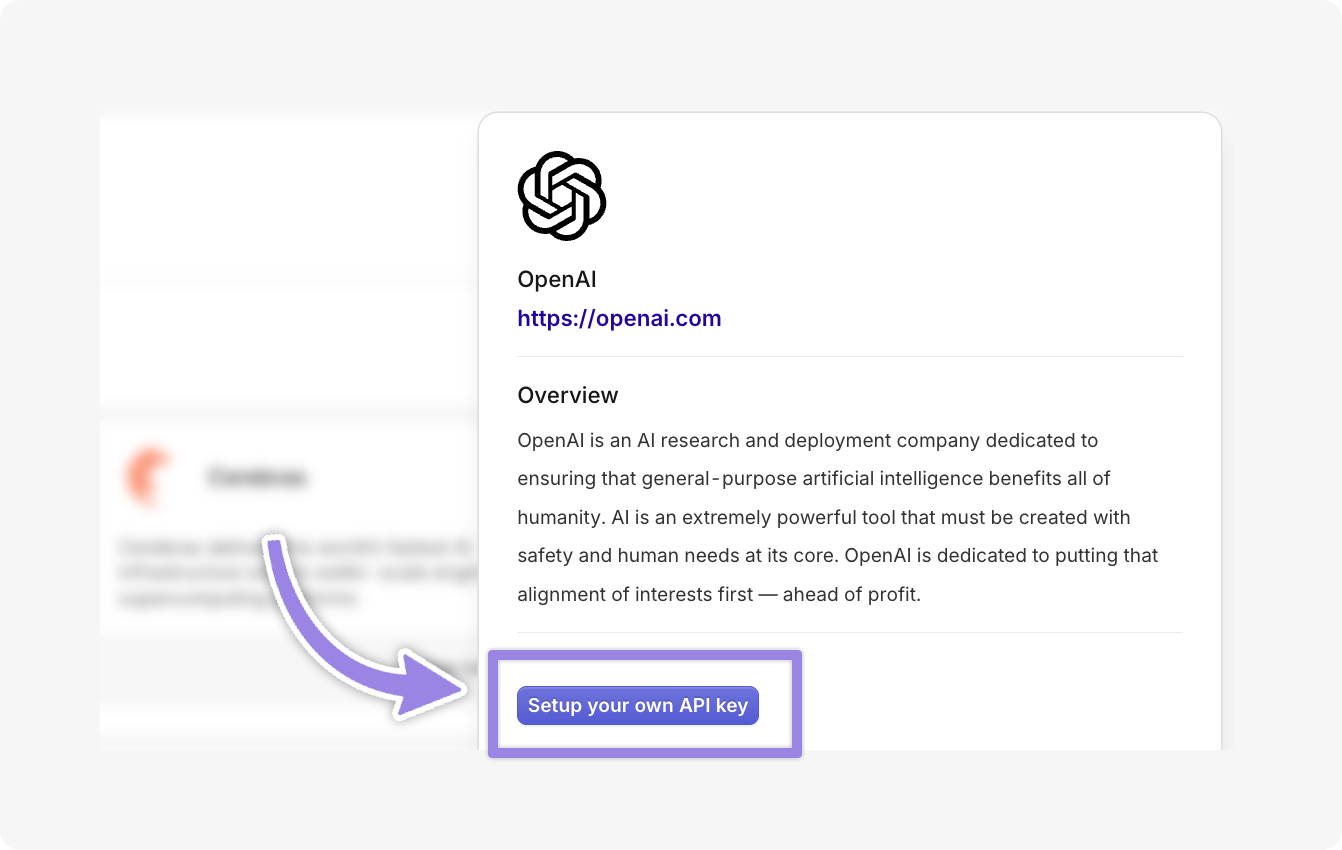
Log in to OpenAI's API platform and copy your secret key:

Navigate back to Orq.ai dashboard and paste your API keys inside the pop-up window that appears after you click the Setup your own API key button
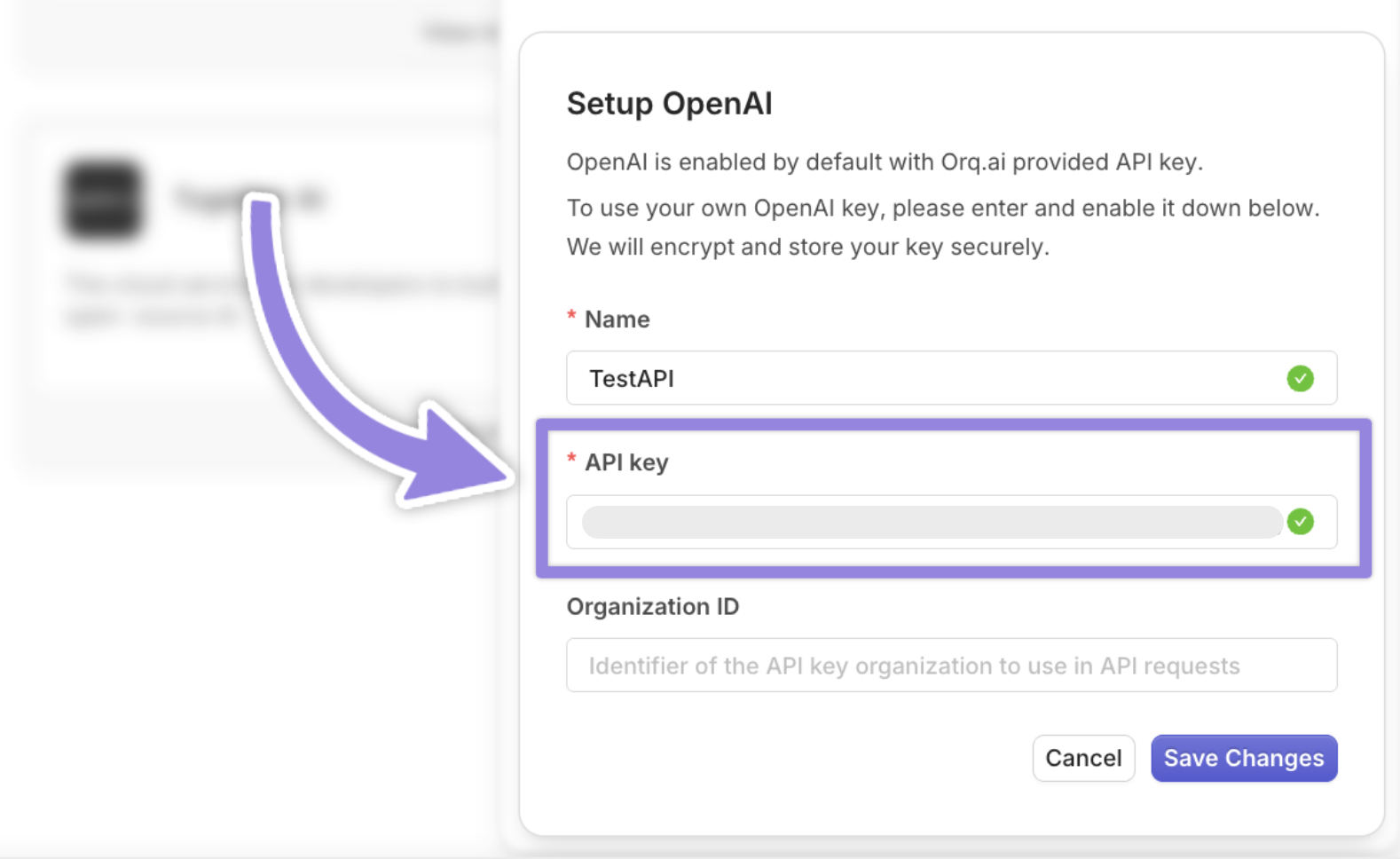
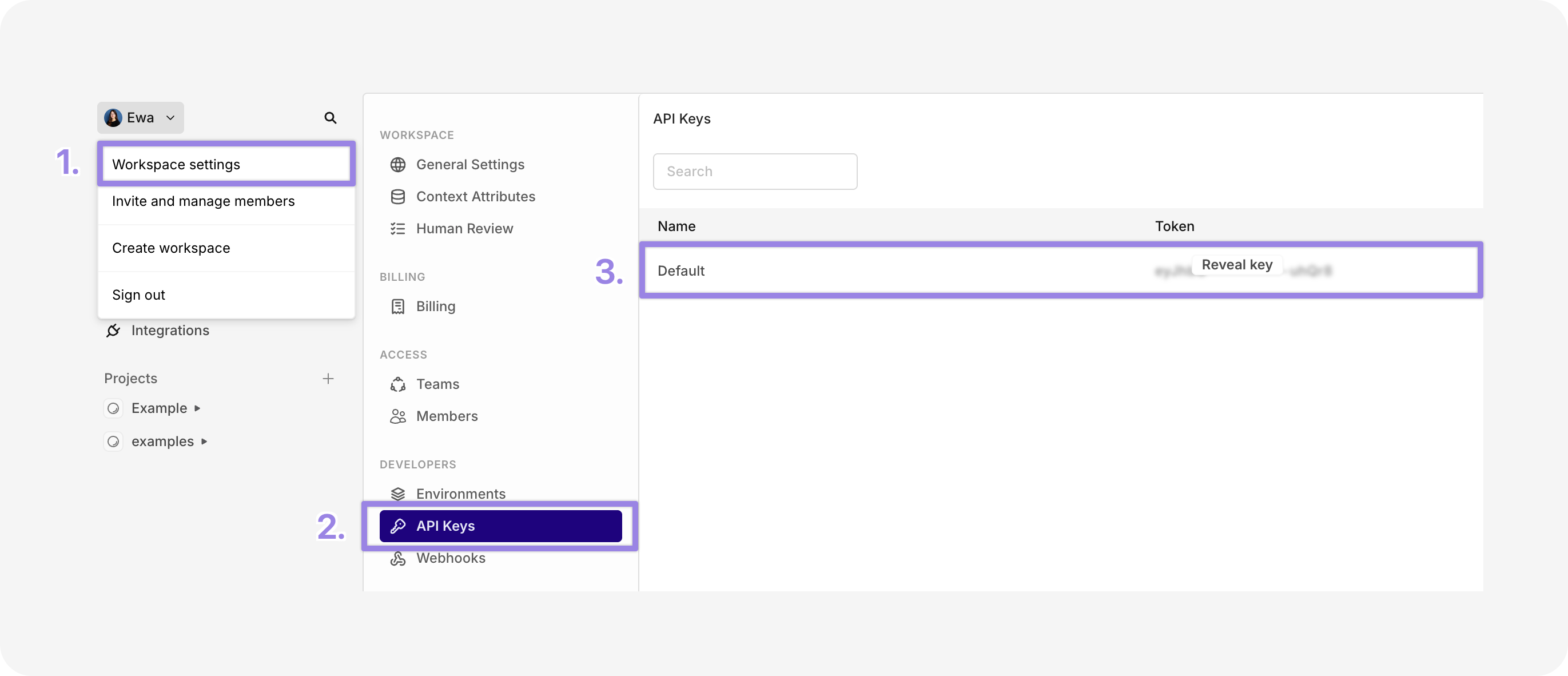
Next, you need to grab your Orq.ai API keys. To do that go to:
- Workspace settings
- API Keys
- Copy your key
In the Terminal copy the cURL command below and replace ORQ_API_KEY with your API key:
curl -X POST https://api.orq.ai/v2/proxy/chat/completions
-H "Authorization: Bearer $ORQ_API_KEY"
-H "Content-Type: application/json"
-d '{
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Hello, world!"}]
}'*If you are using GUI tools (Postman, Insomnia, Swagger, VS Code REST Client and JetBrains HTTP Files) to run cURL scripts check this blog post
This is how a successfull cURL request output looks like:
{"id":"01K7M0YTJ6X90VHPRDMM5GEC4R","object":"chat.completion","created":1760534948,"model":"gpt-4o-2024-08-06","choices":[{"index":0,"message":{"role":"assistant","content":"Hello! This is a response. How can I assist you today?","refusal":null,"annotations":[],"tool_calls":[]},"logprobs":null,"finish_reason":"stop"}],"usage":{"prompt_tokens":14,"completion_tokens":14,"total_tokens":28,"prompt_tokens_details":{"cached_tokens":0,"audio_tokens":0},"completion_tokens_details":{"reasoning_tokens":0,"audio_tokens":0,"accepted_prediction_tokens":0,"rejected_prediction_tokens":0}},"service_tier":"default","system_fingerprint":"fp_f33640a400"}% Notice that you got Hello! This is a response. How can I assist you today? reply back from your API call
Trouble shooting common errors
{"code":401,"error":"API key for openai is not configured in your workspace.
You can configure it in the integrations page.
Go to https://my.orq.ai/orq-YOUR-WORKSPACE-NAME/integrations","source":"provider"} Follow the instructions in this post above:
1. Navigate to Integrations
2. Select OpenAI
3. Click on View integration
4. Click on Setup your own API key{"code":429,"error":"429 You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs: https://platform.openai.com/docs/guides/error-codes/api-errors.","source":"provider"}Increase your API limits here:
https://platform.openai.com/settings/organization/limits Streaming
When you make a normal POST request, the connection closes when the full response is ready.
But when you set "stream": true, the API uses a Server-Sent Events (SSE) connection, an open HTTP connection that continuously sends small packets of data.
curl -N -X POST https://api.orq.ai/v2/proxy/chat/completions \
-H "Authorization: Bearer $ORQ_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-4o",
"stream": true,
"messages": [{"role": "user", "content": "Explain quantum computing simply"}]
}'Each line is a Server-Sent Event (SSE) chunk containing JSON
data: {"id":"01K7M30E5QP6GCQM3YKX1NRY8Q","object":"chat.completion.chunk","created":1760537098,"model":"gpt-4o-2024-08-06","service_tier":"default","system_fingerprint":"fp_eb3c3cb84d","choices":[{"index":0,"delta":{"content":","},"logprobs":null,"finish_reason":null}],"obfuscation":"sxHSdcRBR5Tk"}
data: {"id":"01K7M30E5QP6GCQM3YKX1NRY8Q","object":"chat.completion.chunk","created":1760537098,"model":"gpt-4o-2024-08-06","service_tier":"default","system_fingerprint":"fp_eb3c3cb84d","choices":[{"index":0,"delta":{"content":" opening"},"logprobs":null,"finish_reason":null}],"obfuscation":"R8up2"}
data: [DONE]Retries & fallbacks
Orq.ai allows automatic retries on common API errors and fallback to alternative models if the primary fails.
Use case: If gpt-4o hits a rate limit or downtime, the request automatically retries and may fall back to Anthropic or another model.
curl --location 'https://api.orq.ai/v2/router/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer $ORQ_API_KEY' \
--data-raw '{
"model": "openai/gpt-4o",
"messages": [
{ "role": "user", "content": "Explain Orq AI retries and fallbacks." }
],
"orq": {
"retry": { "count": 3, "on_codes": [429, 500, 502, 503, 504] },
"fallbacks": [
{ "model": "anthropic/claude-3-5-sonnet-20241022" },
{ "model": "openai/gpt-4o-mini" }
]
}
}'
How it works:
retry.count → number of automatic retries on failure codes.
fallbacks → list of alternative models Orq.ai tries if primary fails.
✅ This reduces downtime and ensures your agents remain responsive.
Caching
Orq.ai supports response caching to reduce latency and API usage.
"orq": {
"cache": {
"type": "exact_match",
"ttl": 1800
}
}Example explanation:
- type: "exact_match" → caches identical requests and reuses responses.
- ttl: 1800 → cache entries expire after 30 minutes (1800 seconds).
Benefits:
- Faster responses for repeated questions.
- Reduced API calls → lower cost.
- Example: A repeated FAQ query will return instantly from cache instead of hitting the model.
Adding a knowledge base
You can ground the conversation in domain-specific knowledge by linking knowledge_bases.
"orq": {
"knowledge_bases": [
{ "knowledge_id": "api-documentation", "top_k": 5, "threshold": 0.75 },
{ "knowledge_id": "integration-examples", "top_k": 3, "threshold": 0.8 }
]
}
Contact & Thread Tracking
Orq.ai allows tracking users and support sessions using contact and thread objects.
"orq": {
"contact": {
"id": "enterprise_customer_001",
"display_name": "Enterprise User",
"email": "[email protected]"
},
"thread": {
"id": "support_session_001",
"tags": ["api-integration", "enterprise", "technical-support"]
}
}
Benefits:
Cluster messages in threads for analytics and observability.
Track ongoing customer sessions and maintain conversation context.
Enables auditing or reporting on support interactions.
Dynamic inputs
"orq": {
"inputs": {
"company_name": "Orq AI",
"customer_tier": "Enterprise",
"use_case": "e-commerce platform"
}
}
{
"role": "system",
"content": "You are a helpful customer support agent for {{company_name}}. Use available knowledge to assist {{customer_tier}} customers."
}
How it works:
{{company_name}}, {{customer_tier}}, {{use_case}} are automatically replaced at runtime.
Prompts are personalized for each user/session without rewriting messages manually.
Building a Reliable Customer Support Agent
Imagine you’re creating a customer support agent for your company, Orq AI, which helps enterprise customers integrate APIs. You want it to be:
Reliable — automatically retry or fallback if a model fails.
Contextually aware — grounded in internal documentation and examples.
Fast and cost-efficient — using caching for repeated queries.
Traceable — track conversations per user and session.
Personalized — dynamic prompts based on user type and project.
curl --location 'https://api.orq.ai/v2/router/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer $ORQ_API_KEY' \
--data-raw '{
"model": "openai/gpt-4o",
"messages": [
{ "role": "system", "content": "You are a helpful customer support agent for {{company_name}}. Use available knowledge to assist {{customer_tier}} customers." },
{ "role": "user", "content": "I need help with API integration for my {{use_case}} project" }
],
"orq": {
"retry": { "count": 3, "on_codes": [429, 500, 502, 503, 504] },
"fallbacks": [
{ "model": "anthropic/claude-3-5-sonnet-20241022" },
{ "model": "openai/gpt-4o-mini" }
],
"cache": { "type": "exact_match", "ttl": 1800 },
"knowledge_bases": [
{ "knowledge_id": "api-documentation", "top_k": 5, "threshold": 0.75 },
{ "knowledge_id": "integration-examples", "top_k": 3, "threshold": 0.8 }
],
"contact": {
"id": "enterprise_customer_001",
"display_name": "Enterprise User",
"email": "[email protected]"
},
"thread": {
"id": "support_session_001",
"tags": ["api-integration", "enterprise", "technical-support"]
},
"inputs": {
"company_name": "Orq AI",
"customer_tier": "Enterprise",
"use_case": "e-commerce platform"
}
}
}'
- Dynamic Inputs / Prompt Templating
- Placeholders like
{{company name}}, {{customer_tier}}, and {{use_case}}are automatically replaced using the orq.inputs values. - Effect: Each customer gets a personalized, context-aware response without rewriting prompts.
Retries & Fallbacks
- If gpt-4o fails or is rate-limited (429, 500 series), Orq.ai retries up to 3 times.
- If retries fail, it automatically falls back to Anthropic Claude or GPT-4o-mini.
- Effect: The agent remains highly reliable and doesn’t leave customers waiting.
Caching
- Repeated queries with the same input return instantly from the cache (ttl: 1800s).
- Effect: Reduces latency and API usage, saving costs and improving responsiveness.
Knowledge Bases
- The agent pulls relevant documents from internal KBs like api-documentation or integration-examples.
- Effect: Responses are grounded in your company’s content, making them accurate and trustworthy.
Contact & Thread Tracking
- Each session is linked to a contact (user) and a thread (conversation cluster).
- Effect: Enables session observability, analytics, and organized support tracking for enterprise customers.
Postman
Updated about 1 hour ago